
第20章 Web编程
本章主题
♦ Python的Web应用:简单的Web客户端
♦ urlparse和urllib模块
♦ 高级的Web客户端
♦ 网络爬虫/蜘蛛/机器人
♦ CGI:帮助Web服务器处理客户端数据
♦ 创建CGI应用程序
♦ 在CGI中使用Unicode
♦ 高级CGI
♦ 创建Web服务器
♦ 相关模块
20.1 介绍
本章是有关Web编程的介绍,可以帮助你对Python在因特网上的各种基础应用有个概要了解,例如通过Web页面建立用户反馈表单,通过CGI动态生成输出页面。
20.1.1 Web应用:客户端/服务器计算
Web应用遵循我们反复提到的客户端/服务器架构。这里,Web的客户端是浏览器,应用程序允许用户在万维网上查询文档。另外Web服务器端,进程运行在信息提供商的主机上。这些服务器等待客户和文档请求,进行相应的处理,返回相关的数据。正如大多数客户端/服务器的服务器端一样,Web服务器端被设置为“永远”运行。图20-1列举了Web应用的体验。这里,一个用户执行一个像浏览器的这类客户端程序与Web服务器取得连接,就可以在因特网上任何地方获得数据。
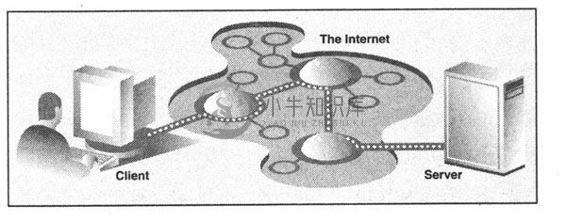
图 20-1 因特网上的Web客户端和Web服务器。在因特网上客户端向服务器端发送一个请求,然后服务器端响应这个请求并将相应的数据返回给客户端
客户端可能向服务器端发出各种请求。这些请求可能包括获得一个网页视图或者提交一个包含数据的表单。这个请求经过服务器端的处理,然后会以特定的格式(HTML等)返回给客户端浏览。
Web客户端和服务器端交互使用的“语言”, Web交互的标准协议是HTTP(超文本传输协议)。 HTTP协议是TCP/IP协议的上层协议,这意味着HTTP协议依靠TCP/IP协议来进行低层的交流工作。它的职责不是路由或者传递消息(TCP/IP协议处理这些),而是通过发送、接收HTTP消息来处理客户端的请求。
HTTP协议属于无状态协议,它不跟踪从一个客户端到另一个客户端的请求信息,这点和我们现今使用的客户端/服务器端架构很像。服务器端持续运行,但是客户端的活动是按照这种结构独立进行的:一旦一个客户的请求完成后,活动将被终止。可以随时发送新的请求,但是他们会被处理成独立的服务请求。由于每个请求缺乏上下文背景,你可以注意到有些URL会有很长的变量和值作为请求的一部分,以便提供一些状态信息。另外一个选项是“cookie”——保存在客户端的客户状态信息。在本章的后面部分,我们将会看到如何使用URL和cookie来保存状态信息。
20.1.2 因特网
因特网是一个连接全球客户端和服务器端的变幻莫测的“迷雾”。客户端最终连接到服务器的通路,实际包含了不定节点的连通。作为一个客户端用户,所有这些实现细节都会被隐藏起来。抽象成为了从客户端到所访问的服务器端的直接连接。被隐藏起来的HTTP, TCP/IP协议将会处理所有的繁重工作。中间的环节信息用户并不关心,所以将这些执行过程隐藏起来是有好处的。图20-2展示了因特网的扩展视图。
如图20-2所示,因特网是由多种工作在一定规则下的(也许非连贯的)相互连接的网络组成的。图表左侧的焦点是Web客户端,在家上网的用户通过拨号连接到ISP(因特网供应商)上,上班族使用的则是公司的局域网。
图表的右半部分关注的是Web服务器端及位置所在。具有大型Web站点的公司会将他们全部的“Web服务器”放在ISP那里。这种物理安放被称为“整合”,这意味着你的服务器和其他客户的服务器一同放在ISP处被“集中管理”。这些服务器或许为客户提供了不同的数据或者有一部分为应付重负荷(高数量用户群)而设计成了可以存储重复数据的系统。小公司的Web站点或许不需要这么大的硬盘或者网络设备,也许仅有一个或者几个“整合”服务器安放在他们的ISP处就可以了。
在任何一种情况下,大多数“整合”服务器被部署在大型ISP提供的骨干网上,这意味着他们具有更高的“带宽”,如果你愿意,可以更接近因特网的核心点,从而可以更快地与因特网取得连接。这就允许客户端可以绕过许多网络直接快速的访问服务器,从而在指定的时间内可以使得更多的客户获得服务。
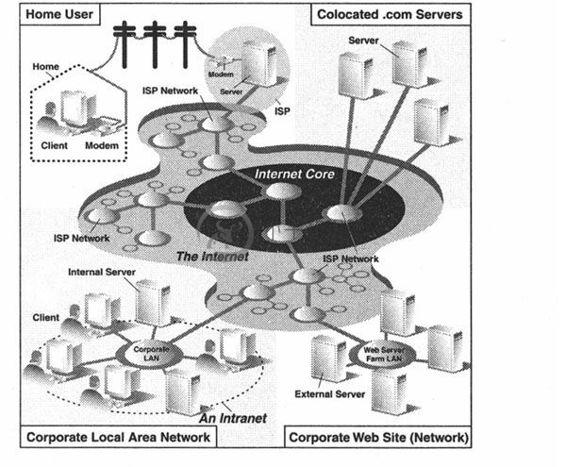
图 20-2 因特网的统览。左侧指明了在哪里你可以找到Web客户端,而右侧则暗示了Web服务器的具体位置
有一点需要记清楚,Web应用是网络应用的一种最普遍的形式,但不是唯一的也不是最古老的一种形式。因特网的出现早于Web近30年。在Web出现之前,因特网主要用于教学和科研目的。因特网上的大多数系统都是运行在Unix平台上的——一个多用户操作系统,许多最初的网际协议至今仍被沿用。
这些协议包括telnet(允许用户在因特网上登录到远程的主机上,沿用至今), FTP协议(文本传输协议,用户通过上传和下载文件可以共享文件和数据,沿用至今), Gopher (Web搜索引擎的雏形——一个在互联网上爬动的小软件“gopher”可以自动寻找你感兴趣的数据), SMTP或者叫做简单邮件传输协议(这个协议用于最古老的也是应用最广泛的电子邮件),NNTP(新闻对新闻传输协议)。
由于Python的最初偏重的就是因特网编程,除了其他一些东西外你还可以找到上边提及的所有协议。可以这样区分“因特网编程”和“Web编程”,后者仅包括针对Web的应用程序开发,也就是说Web客户端和服务器是本章的焦点。
因特网编程涵盖更多范围的应用程序:包括我们之前提及的一些网际协议,例如FTP、SMTP等,同时也包括我们前一章提到的网络编程和套接字编程。
20.2 使用Python进行Web应用:创建一个简单的Web客户端
有一点需要记清楚,浏览器只是Web客户端的一种。任何一个通过向服务器端发送请求来获得数据的应用程序都被认为是“客户端”。当然,也可以建立其他的客户端从而在因特网上检索出文档和数据。这样做的一个重要原因就是浏览器的能力有限,也就是说,它主要用于查看并同其他Web站点交互。另一方面,一个客户端程序,有能力做得更多——它不仅可以下载数据,同时也可以存储、操作数据,甚至或可以将其传送到另外一个地方或者传给另外一个应用。
一个使用urllib模块下载或者访问Web上的信息的应用程序[使用urllib. urlopen()或者urllib. urlre-trieve()]可以被认为是简单的Web客户端。你所要做的就是提供一个有效的Web地址。
20.2.1 统一资源定位符
简单的Web应用包括使用被称为URL(统一资源定位器,Uniform Resource Locator)的Web地址。这个地址用来在Web上定位一个文档,或者调用一个CGI程序来为你的客户端产生一个文档。URL是大型标识符URI(统一资源标识,Uniform Resource Identifier)的一部分。这个超集是建立在已有的命名惯例基础上的。一个URL是一个简单的URI,使用已存在的协议或规划(也就是http, ftp等)作为地址的一部分。为了进一步描绘这些,我们将会引入非URL的URI,有时这些被成为URN(统一资源名称,Uniform Resource Name),但是在今天我们唯一使用的一种URI是URL,至于URI和URN你也许没有听到太多,这或许已被保存成XML标识符了。
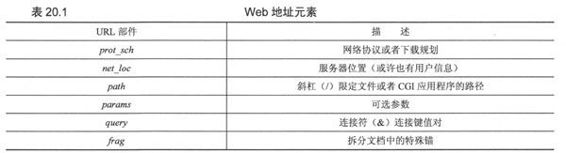
如街道地址一样,Web地址也有一些结构。美国的街道地址通常是这种格式“号码街道名称”,例如“123主大街”。这个和其他国家不同,他们有自己的规则。URL使用这种格式:

表20.1描述了各个部件。
net_loc可以进一步拆分成多个部件,有些是必备的,其他的是可选部件,net_loc字符串如下:
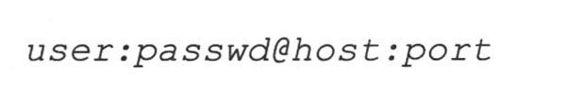
表20.2中分别描述了这些部件
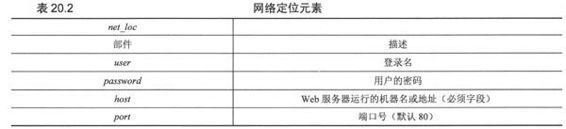
在这4个部件中,host主机名是最重要的。端口号只有在Web服务器运行其他非默认端口上时才会被使用(如果你不确定所使用的端口号,可以参考第16章)。
用户名和密码部分只有在使用FTP连接时候才有可能用到,因为即使是使用FTP,大多数的连接都是使用“匿名”这时是不需要用户名和密码的。
Python支持两种不同的模块,分别以不同的功能和兼容性来处理URL。一种是urlparse,另一种是urllib。这里我们将会简单的介绍下它们的功能。
20.2.2 urlparse模块
urlpasrse模块提供了操作URL字符串的基本功能。这些功能包括urlparse()、urlunparse()和urljoin().

urlparse()将URL字符串拆分成如上所描述的一些主要部件。语法结构如下:

urlparse()将urlstr解析成一个6元组(prot_sch、net_loc、 path、params、query、frag) 。这里的每个部件在上边已经描述过了。如果urlstr中没有提供默认的网络协议或下载规划时可以使用defProtSch。allowFrag标识一个URL是否允许使用零部件。下边是一个给定URL经urlparse()后的输出:

urlunparse()的功能与urlpase()完全相反:它拼合一个6元组(prot_sch、net_loc、path、params、query、frag) -urltup,它可能是一个URL经urlparse()后的输出返回值。于是,我们可以用如下方式表示:
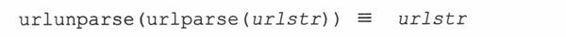
你或许已经猜到了urlunpase()的语法
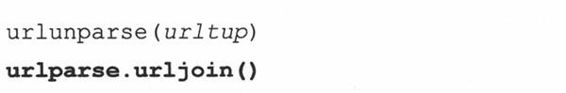
在需要多个相关的URL时我们就需要使用urljoin()的功能了,如在一个Web页中生成的一系列页面的URL。Urljoin()的语法是:
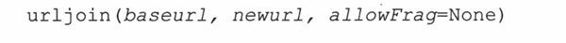
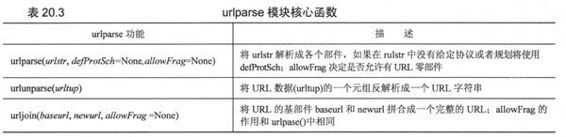
urljoin()取得baseurl,并将其基路径(net_loc附加一个完整的路径,但是不包括终端的文件)与newurl连接起来。例如:

在表20.3中可以找到urlparse的功能概述。
20.2.3 urllib模块
 核心模块:urllib
核心模块:urllib
urllib模块提供了所有你需要的功能,除非你计划写一个更加低层的网络客户端。urllib提供了一个高级的Web交流库,支持Web协议、HTTP、FTP和Gopher协议,同时也支持对本地文件的访问。urllib模块的特殊功能是利用上述协议下载数据(从因特网、局域网、主机上下载)。使用这个模块可以避免使用httplib、ftplib和gopherlib这些模块,除非你想用更低层的功能。在那些情况下这些模块都是可选择的(注意:大多数以*lib命名的模块用于客户端相关协议开发。并不是所有情况都是这样的,或许urllib应该被命名为“internetlib”或其他相似的名字)。
Urllib模块提供了在给定的URL地址下载数据的功能,同时也可以通过字符串的编码、解码来确保它们是有效URL字符串的一部分。我们接下来要谈的功能包括urlopen()、urlretrieve() 、 quote() 、 unquote() 、quote_plus()、unquote_plus()和urlencode()。我们可以使用urlopen()方法返回文件类型对象。你会觉得这些方法不陌生,因为在第9章我们已经涉及到了文件方面的内容。
1. urllib. urlopen()
urlopen()打开一个给定URL字符串与Web连接,并返回了文件类的对象。语法结构如下:

urlopen()打开urlstr所指向的URL。如果没有给定协议或者下载规划,或者文件规划早已传入,urlopen()则会打开一个本地的文件。
对于所有的HTTP请求,常见的请求类型是“GET”。在这些情况中,向Web服务器发送的请求字符串(编码键值或引用,如urlencode()函数的字符串输出(如下))应该是urlstr的一部分。
如果要求使用“POST”方法,请求的字符串(编码的)应该被放到postQueryData变量中。(要了解更多关于“GET”和”POST”方法的信息,请查看CGI应用编程部分的普通文档或者文本,这些我们在下边也会讨论)。GET和POST请求是向Web服务器上传数据的两种方法。
一旦连接成功,urlopen()将会返回一个文件类型对象,就像在目标路径下打开了一个可读文件。例如,如果我们的文件对象是f,那么我们的“句柄”将会支持可读方法,如f. read() 、f. readline() 、 f. readlines() 、f.close()和f.fileno()。
此外,f.info()方法可以返回MIME(多目标因特网邮件扩展,Multipurpose Internet Mail Extension)头文件。这个头文件通知浏览器返回的文件类型可以用哪类应用程序打开。例如,浏览器本身可以查看HTML(超文本标记语言,HyperText Markup Language),纯文本文件,生成(指由数据显示图像—译者注)PNG (Portable Network Graohics) 、JPEG (Joint Photographic Experts Group)或者GIF (GraphicsInterchange Format)文件。其他如多媒体文件、特殊类型文件需要通过扩展的应用程序才能打开。
最后,geturl()方法在考虑了所有可能发生的间接导向后,从最终打开的文件中获得真实的URL,这些文件类型对象的方法在表20.4中有描述。

如果你打算访问更加复杂的URL或者想要处理更复杂的情况,如基于数字的权限验证、重定位、cookie等问题,我们建议你使用urllib2模块,这个在1. 6版本中有介绍(多数是试验模块)。它同时还有一个urlopen()函数,但也提供了其他的可以打开各种URL的函数和类。关于urllib2的更多信息,将会在本章的下一部分介绍。
2. urllib.urlretrieve()
如果你对整个URL文档的工作感兴趣,urlretrieve()可以帮你快速处理一些繁重的工作。下面是urlretrieve()的语法:

除了像urlopen()这样从URL中读取内容,urlretrieve()可以方便地将urlstr定位到的整个HTML文件下载到你本地的硬盘上。你可以将下载后的数据存成一个本地文件或者一个临时文件。如果该文件已经被复制到本地或者已经是一个本地文件,后续的下载动作将不会发生。
如果可能,downloadStatusHook这个函数将会在每块数据下载或传输完成后被调用。调用时使用下边三个参数:目前读入的块数、块的字节数和文件的总字节数。如果你正在用文本或图表向用户演示“下载状态”信息,这个函数将会是非常有用的。
urlretrieve()返回一个2元组,(filename, mime_hdrs) .filename是包含下载数据的本地文件名,mime_hdrs是对Web服务器响应后返回的一系列MIME文件头。要获得更多的信息,可以看mimetools的Message类。对本地文件来说mime_hdrs是空的。
关于urlretrieve()的简单应用,可以看11. 4 (grabweb.py)中的例子。在本章的20. 2小节中将会介绍urlretrieve()更深层的应用。
3. Urllib.quote()和urllib.quote-plus()
quote*()函数获取URL数据,并将其编码,从而适用于URL字符串中。尤其是一些不能被打印的或者不被Web服务器作为有效URL接收的特殊字符串必须被转换。这就是quote*()函数的功能。quote*()函数的语法如下:

逗号、下划线、句点、斜线和字母数字这类符号是不需要转化的。其他的则均需要转换。另外,那些不被允许的字符前边会被加上百分号(%)同时转换成16进制,例如:“%xx”, “XX”代表这个字母的ASCII码的十六进制值。当调用quote*()时,urldata字符串被转换成了一个可在URL字符串中使用的等价值。safe字符串可以包含一系列不能被转换的字符。默认的是斜线(/).
quote_plus()与quote()很像,另外它还可以将空格编码成(+)号。下边是一个使用quote()和quote_plus()的例子:

4. urllib.unquote()和urllib.unquote_plus()
也许和你猜到的一样,unquote*()函数与quote*()函数的功能完全相反——它将所有编码为“%xx”式的字母都转换成它们的ASCII码值。Unquote*()的语法如下:
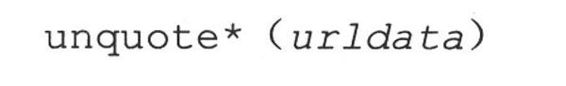
调用unquote()函数将会把urldata中所有的URL-编码字母都解码,并返回字符串。Unquote_plus()函数会将加号转换成空格符。
5. urllib. urlencode()
在1. 5. 2版的Python中,urlopen()函数接收字典的键-值对,并将其编译成CGI请求的URL字符串的一部分。键值对的格式是“键=值”,以连接符(&)划分。更进一步,键和它们的值被传到quote_plus()函数中进行适当的编码。下边是urlencode()输出的一个例子:

urllib和urlparse还有一些其他的功能,在这里我们就不一一概述了。阅读相关文档可以获得更多信息。
6.安全套接字层支持
在1. 6版中urllib模块通过安全套接字层(Secure Socket Layer, SSL)支持开放的HTTP连接socket模块的核心变化是增加并实现了SSL。随后,urllib和httplib模块被上传用于支持URL在“https”连接规划中的应用。除了那两个模块以外,其他的含有SSL的模块还有imaplib、poplib和smtplib.
在表20.5中可以看到关于本节讨论的urllib函数的总结。

20.2.4 urllib模块
正如前面所提到的,urllib2可以处理更复杂URL的打开问题。一个例子就是有基本认证(登录名和密码)需求的Web站点。最简单的“获得已验证参数”的方法是使用前边章节中描述的URL部件net_loc,也就是说:http://user:[email protected]。这种解决方案的问题是不具有可编程性的。然而使用urllib2,我们可以通过两种不同的方式来解决这个问题。
我们可以建立一个基础认证处理器(urllib2. HTTPBasicAuthHandler),同时在基本URL或域上注册一个登录密码,这就意味着我们在Web站点上定义了个安全区域。(关于域的更多信息可以查看RFC2617 (HTTP认证:基本数字认证))。一旦完成这些,你可以安装URL打开器,通过这个处理器打开所有的URL。
另一个可选的办法就是当浏览器提示的时候,输入用户名和密码,这样就发送了一个带有适当用户请求的认证头。在20.1的例子中,我们可以很容易的区分出这两种方法。
逐行解释
1 ~ 7行
普通的初始化过程,外加几个为后续脚本使用的常量。
9 ~ 15行
代码的“handler”版本分配了一个前面提到的基本处理器类,并添加了认证信息。之后该处理器被用于建立一个URL-opener,并安装它以便所有已打开的URL能用到这些认证信息。这段代码和urllib2模块的Python官方文档是兼容的。
例20.1 HTTP认证客户端(urlopenAuth.py)


17 ~ 22行
这段代码的“request”版本创建了一个Request对象,并在HTTP请求中添加了基本的base64编码认证头信息。返回“主体”后(译者注:指for循环)调用urlopen()时,该请求被用来替换其中的URL字符串。注意原始URL内建在Requst对象中,因此在随后的urllib2. urlopen()调用中替换URL字符串才不会产生问题。。这段代码的灵感来自Mike Foord和Lee Harr在Python Cookbook上的回复,具体位置在:
http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/305288
http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/267197
如果能直接用哈尔的HTTPRealmFinder类就更好了,那样我们就没必要在例子里使用硬编码了。
24 ~ 29行
这个脚本的剩余部分只是用两种技术分别打开了给定的URL,并显示服务器返回的HTML页面第一行(舍弃了其他行),当然前提是要通过认证。注意如果认证信息无效的话会返回一个HTTP错误(并且不会有HTML)。
程序的输出应当如下所示:

还有一个很有用的文档可以在http://www.voidspace.org.uk/python/articles/urllib2.shtml找到,你可以把它作为Python官方文档的补充。
20.3 高级Web客户端
Web浏览器是基本的Web客户端,主要用来在Web上查询或者下载文件。而Web的高级客户端并不只是从因特网上下载文档。
高级Web客户端的一个例子就是网络爬虫(也称蜘蛛或机器人)。这些程序可以基于不同目的在因特网上探索和下载页面,其中包括:
为Google和Yahoo这类大型的搜索引擎建索引;
脱机浏览——将文档下载到本地,重新设定超链接,为本地浏览器创建镜像;
下载并保存历史记录或框架;
Web页的缓存,节省再次访问Web站点的下载时间。
我们下边介绍网络爬虫crawl.py,抓取Web的开始页面地址(URL),下载该页面和其他后续链接页面,但是仅限于那些与开始页面有着相同域名的页面。如果没有这个限制的话,你的硬盘将会被耗尽!crwal.py的代码在例20.2中展示。
逐行(逐个类)解释
1 ~ 11行
该脚本的开始部分包括Python在Unix上标准的初始化行和一些模块属性的导入,它们都会在本应用程序中用到。
13 ~ 49行
Retriever类的责任是从Web下载页面,解析每个文档中的链接并在必要的时候把它们加入“to-do”队列。我们为每个从网上下载的页面都创建一个Retriever类的实例。Retriever中的方法展现了它的功能:构造器(__init__())、filename()、 download()和parseAndGetLinks().
filename()方法使用给定的URL找出安全、有效的相关文件名并存储在本地。大体上说,它会去掉URL的“http://”前缀,使用剩余的部分作为文件名,并创建必要的文件夹路径。那些没有文件名前缀的URL则会被赋予一个默认的文件名“index. htm”(可以在调用filename()时重新指定这个名字).
构造器实例化了一个Retriever对象,并把URL和通过filename()获得的相应文件名都作为本地属性保存起来。
例20.2 高级Web客户端:网络爬虫(crawl.py)
这个爬虫程序包括两个类,一个管理整个crawling进程(Crawler),一个检索并解析每一个下载的Web页面(Retriever).




正如你想象的,download()方法实际会连上网络去下载给定链接的页面。它使用URL调用urllib.urlretrieve()函数并把结果保存在filename中(该值由filename()返回)。如果下载成功,parse()方法会被调用来解析刚从网络拷贝下来的页面;否则会返回一个错误字符串。
如果Crawler判定没有错误发生,它会调用parseAndGetLinks()方法来解析新下载的页面并决定该页面中每个链接的后续动作。
51 ~ 98行
Crawler类是这次演示中的“明星”,掌管在一个Web站点上的整个抓爬过程。如果我们为应用程序添加线程,就可以为每个待抓爬的站点分别创建实例。Crawler的构造器在初始化过程中存储了三样东西,第一个是q,一个待下载链接的队列。这个队列在运行过程中会有涨落,有页面处理完毕它就变短,在下载的页面中发现新的链接则会让它变长。
Crawler包含的另两个数值是seen,一个所有“我们已看过”(已下载)的链接的列表和dom,我们把主链接的域名存储在这里,并用这个值来判定后续链接是否是该域的一部分。
Crawler还有一个静态数据成员count。这个计数器只是用来保存我们已经从网上下载的对象数目。每一个页面成功下载它就会增加。
除了构造器Crawler还有其他两个方法,getPage()和go(). go()只是简单地启动Crawler,它在代码的主体部分被调用。go()中有一个循环,只有队列中还有待下载的新链接它就会不停的执行。然而这个的真正工作者,却是getPage()方法。
getPage()初始化了一个Retriever对象,并把第一个链接赋给它然后让它执行。如果页面下载成功,计数器会增加并且链接会被加到“已看”列表。它会反复地检查每个已下载页面中的所有链接并判决是否有链接要被加入待下载队列。go()中的主循环会不停地推进处理过程直到队列为空,这时便大功告成。
属于其他域的链接、已经下载过的链接、已在队列中待处理的链接和“mailto: ”类型的链接在扩充队列时都会被忽略掉。
100 ~ 114行
main()是程序运行的起点,它在该脚本被直接调用时执行。其他导入crawl.py的模块则需要调用main()来启动处理过程。main()需要一个URL来启动处理,如果在命令行指定了一个(例如这个脚本被直接调用时),它就会使用这个指定的。否则,脚本进入交互模式,提示用户输入起始URL。一旦有了起始链接,Crawler就会被实例化并启动开来。
一个调用crawl.py的例子如下所示:


执行后,在本地的系统文件中将会在创建一个名为www.null.com的目录及子目录。左右的HTML文件都会显示在主目录下。
20.4 CGI:帮助Web服务器处理客户端数据
20.4.1 CGI介绍
Web开发的最初目的是在全球范围内对文档进行存储和归档(大多是教学和科研目的的)。这些零碎的信息通常产生于静态的文本或HTML.
HTML是一个文本格式而算不上是一种语言,它包括改变字体的类型、大小、风格。HTML的主要特性在于它对超文本的兼容性,文本以某种高亮的形式指向另外一个相关文档。可以通过鼠标点击或者其他用户的选择机制来访问这类文档。这些静态的HTML文档在Web服务器上,在有请求时,将被送到客户端。
随着因特网和Web服务器的形成,产生了处理用户输入的需求。在线零售商需要能够单独订货,网上银行和搜索引擎需要为用户分别建立账号。因此发明了这种执行模式,并成为了Web站点可以从用户那里获得特殊信息的唯一形式(在Java applet出现之前)。反过来,在客户提交了特定数据后,就要求立即生成HTML页面。
现在Web服务器仅有一点做得很不错:获取用户对文件的请求,并将这个文件(也就是说HTML文件)返回给客户端。它们现在还不具有处理字段类特殊数据的机制。将这些请求送到可以生成动态HTML页面的扩展应用程序中并返回给客户端,这些还没有成为Web服务器的职责。
这整个过程开始于Web服务器从客户端接到了请求(GET或者POST),并调用合适的程序。然后开始等待HTML页面——与此同时,客户端也在等待。一旦程序完成,会将生成的动态HTML页面返回到服务器端,然后服务器端再将这个最终结果返回给用户。服务器接到表单反馈,与外部应用程序交互,收到并返回新生成的HTML页面都发生在一个叫做Web服务器CGI(标准网关接口,CommonGateway Interface)的接口上。图20-3描述了CGI的工作原理,逐步展示了一个用户从提交表单到返回最终结果Web页面的整个执行过程和数据流。
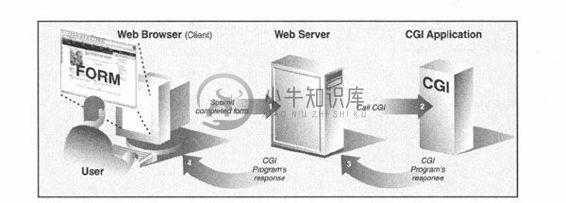
图 20-3 CGI工作概要图。CGI代表了在一个Web服务器和能够处理用户表单、生成并返回动态HTML页的应用程序间的交互
客户端输入给Web服务器端的表单可能包括处理过程和一些存储在后台数据库中的表单。需要记住的是,在任何时候都可能有任何一个用户去填写这个字段,或者点击提交按钮或图片,这更像激活了某种CGI活动。
创建HTML的CGI应用程序通常是用高级编程语言来实现的,可以接受、处理数据,向服务器端返回HTML页面。目前使用的编程语言有Perl、PHP、C/C++或Python.
在我们研究CGI之前,我们必须告诉你典型的Web应用产品已经不再使用CGI了。
由于它词义的局限性和允许Web服务器处理大量模拟客户端数据能力的局限性,CGI几乎绝迹。Web服务的关键使命依赖于遵循像C/C++这样的语言规范。如今的Web服务器典型的部件有Aphache和集成的数据库部件(MySQL或者PostgreSQL) 、Java (Tomcat) 、PHP和各种Perl模块、Python模块,以及SSL/security。然而,如果你工作在私人小型的或者小组织的Web网站上的话就没有必要使用这种强大而复杂的Web服务器,CGI是一个适用于小型Web网站开发的工具。
更进一步来说,有很多Web应用程序开发框架和内容管理系统,这些都弥补了过去CGI的不足。然而,在这些浓缩和升华下,它们仍旧遵循CGI最初提供的模式,可以允许用户输入,根据输入执行拷贝,并提供了一个有效的HTML作为最终的客户端输出。因此,为了开发更加高效的Web服务,有必要理解CGI实现的基本原理。
在下一部分中,我们将会关注在cgi模块的协助下如何在Python中建立一个CGI应用程序。
20.4.2 CGI应用程序
CGI应用程序和典型的应用程序有些不同。主要的区别在于输入、输出及用户和计算机交互方面。当一个CGI脚本开始执行时,它需要检索“用户-支持”表单,但这些数据必须要从Web的客户端才可以获得,而不是从服务器或者硬盘上获得。
这些不同于标准输出的输出将会返回到连接的Web客户端,而不是返回到屏幕、CUI窗口或者硬盘上。这些返回来的数据必须是具有一系列有效头文件的HTML。否则,如果浏览器是Web的客户端,由于浏览器只能识别有效的HTTP数据(也就是MIME头和HTML),那么返回的也只能是个错误消息(具体的就是因特网服务器错误).
最后,可能和你想象的一样,用户不能与脚本进行交互。所有的交互都将发生在Web客户端(用户的行为)、Web服务器端和CGI应用程序间。
20.4.3 cgi模块
在cgi模块中有个主要类,即FieldStorage类,它完成了所有的工作。在Python CGI脚本开始时这个类将会被实例化,它会从Web客户端(具有Web服务器)读出有关的用户信息。一旦这个对象被实例化,它将会包含一个类似字典的对象,具有一系列的键-值对,键就是通过表单传入的表单条目的名字,而值则包含相应的数据。
这些值本身可以是以下三种对象之一。它们既可以是FieldStorage对象(实例),也可以是另一个类似的名为MiniFieldStorage类的实例,后者用在没有文件上传或mulitple-part格式数据的情况。MiniFieldStorage实例只包含名字和数据的键-值对。最后,它们还可以是这些对象的列表。这发生在表单中的某个域有多个输入值的情况下。
对于简单的Web表单,你将会经常发现所有的MiniFieldStorage实例。下边包含的所有的例子都仅针对这种情况。
20.5 建立CGI应用程序
20.5.1 建立Web服务器
为了可以用Python进行CGI开发,你首先需要安装一个Web服务器,将其配置成可以处理Python CGI请求的模式,然后让你的Web服务器访问CGI脚本。其中有些操作你也许需要获得系统管理员的帮助。
如果你需要一个真正的Web服务器,可以下载并安装Aphache. Aphache的插件或模块可以处理Python CGI,但这在我们的例子里并不是必要的。如果你准备把自己的服务“带入真实世界”,也许会想安装这些软件,尽管它们似乎过于强大。
为了学习的目的或者是建立小型的Web站点,使用Python自身带的Web服务器就已经足够了。在第20.8节,你将会实际地学习如何建立和配置简单的基于Python的Web服务器。如果你想在本阶段获得更多知识,也可以现在提前阅读那部分。然而,这并不是本章的焦点。
如果你只是想建立一个基于Web的服务器,可以直接执行下边的Python语句。

-m选项是在2. 4中新引进的,如果你使用的是比这旧的Python版本,或者想看一下它执行的不同方式,请看14.4.3节。无论如何,最终它需要工作起来。
这将会在当前机器的当前目录下建立一个端口号为8000的Web服务器,然后可以在启动这个服务器的目录下建立一个Cgi-bin,将Python CGI脚本放到那里。将一些HTML文件放到那个目录下,或许有些。py CGI脚本在Cgi-bin中,然后就可以在地址栏中输入这些地址来访问Web站点了。
http://localhost:8000/friends.htm
http://localhost:8000/cgi-bin/friends2.py
20.5.2 建立表单页
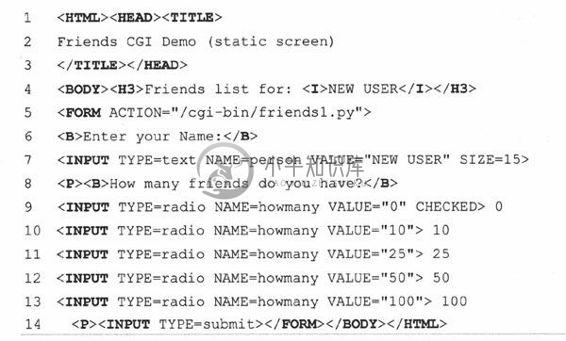
在例20.3中,我们写了一个简单的Web表单friends.html。
正如你可以在代码中看到的一样,这个表单包括两个输入变量:person和howmany,这两个值将会被传到我们的CGI脚本friendsl.py中。
你会注意到在例子中我们将CGI脚本初始化到主机默认的cgi-bin目录下(“Action”连接)(如果这个信息与你开发环境不一样的话,在测试Web页面和CGI之前请更新你的表单事件)。同时由于表单事件中缺少METHOD子标签,所有的请求将会采用默认的GET方法。选择GET方法是因为我们的表单没有太多的字段,同时我们希望我们的请求字段可以在“位置”(aka “Address”, “Go To”)条中显示,以便你可以看到被送到服务器端的URL。
例20.3 静态表单页(friends. htm)
这个HTML文件展示给用户一个空文档,含有用户名和一系列可供用户选择的单选按钮。
让我们看看friends.htm提交后在客户端屏幕上的显示(图20-4 Safari, MacOS和图20-5 IE6)
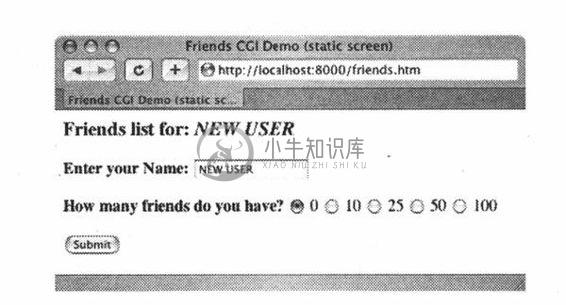
图 20-4 Friends表单页在Mac OS X操作系统Safari浏览器上的显示(friends.htm)
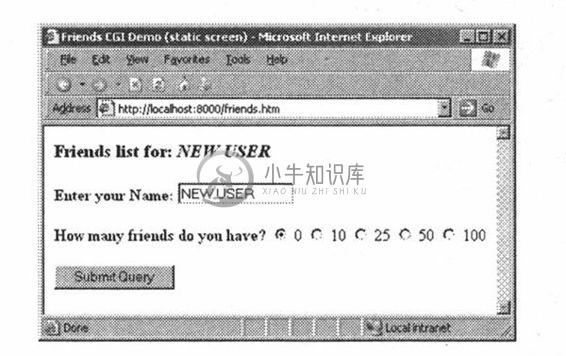
图 20-5 friends表单页面在Win32操作系统IE 6浏览器上的显示(friends.htm)
通过本章,我们将会展示来自不同Web浏览器和操作系统的屏幕截图。
20.5.3 生成结果页
这些输入是由用户完成的,然后按下了“Submit”按钮(可选的,用户也可以在该文本字段中按下回车键获得相同的效果)。当这些发生后,在例20.4中的脚本,friendsl.py将会随CGI一起被执行。
这个脚本包含了所有的编程功能,读出并处理表单的输入,同时向用户返回结果HTML页面。所有的这些“实际”的工作仅是通过4行Python代码来实现的(14〜17行).
表单的变量是FieldStorage的实例,包含person和howmanyh字段的值。我们把这些值本分别存入Python的who和howmany变量中。变量reshtml包含需要返回的HTML文本的正文,还有一些动态填好的字段,这些数据都是从表单中读入的。
例20.4 CGI代码结果示图(friendsl.py)
CGI脚本在表单上抓取person和howmany字段,并用这些数据生成动态的结果示图。


 核心提示:HTML头文件是从HTML中分离出来的
核心提示:HTML头文件是从HTML中分离出来的
有一点需要向CGI初学者指明的是,在向CGI脚本返回结果时,须先返回一个适当的HTTP头文件后才会返回结果HTML页面。进一步说,为了区分这些头文件和结果HTML页面,需要在friendsl.py的第5行中插入几个换行符。在本章后边的代码中也是这样处理的。
图20-6是可能出现的屏幕显示,假设用户输入的名字为“erick allen”,单击“10friends”单选按钮。这次的屏幕截图展示的是在Windows环境下IE 3浏览器中的效果。
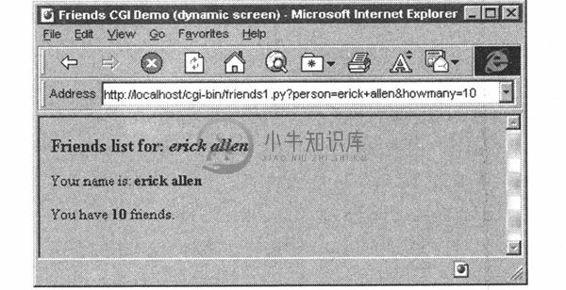
图 20-6 Friends的结果页面在Win32操作系统IE 3浏览器上的显示
如果你是一个Web站点的生产商,你也许会想,“如果这个人忘记了的话,我能自动地将这个人的名字大写,会不会更好些? ”这个通过Python的CGI可以很容易地实现(我们很快就会进行试验!)。
注意GET请求是如何将表单中的变量和值加载在URL地址条中的。你是否观察到了friends. htm页面的标题有个“static”,而friends.py脚本输出到屏幕上的则是“dynamic”?我们这样做的一个原因就是:指明friends. htm文件是一个静态的文本,而结果页面却是动态生成的。换句话说,结果页面的HTML不是以文本文件的形式存在硬盘上的,而是由我们的CGI脚本生成的,并且将其以本地文件的形式返回。
在下边的例子中,我们将会更新我们的CGI脚本,使其变得更灵活些,从而完全绕过静态文件。
20.5.4 生成表单和结果页面
我们删除fiends. html文件并将其合并到friends2.py中。这个脚本现在将会同时生成表单页和结果页面。但是我们如何控制生成哪个页面呢?好吧,如果有表单数据被发送,那就意味着我们需要建立一个结果页面。如果我们没有获得任何的信息,这就说明我们需要生成一个用户可以输入数据的表单页面。
例20.5展示的就是我们的新脚本friends2.py。
那么我们改变了哪些脚本呢?让我们一起看下这个脚本的代码块。
逐行解释
1 ~ 5行
除了通常的起始和模块导入行,我们还把HTTP MTMI头从后面的HTML正文部分分离出来,放在了这里。因为我们将在返回的两种页面(表单页面和结果页面)中都使用它,而又不想重复写文本。当需要输出时,我们将把这个头字串加在相应的HTML正文中。
7 ~ 29行
所有这些代码都是为了整合CGI脚本里的friends.htm表单页面。我们对表单页面的文本使用一个变量formhtml,还有一个用来创建单选按钮的字符串变量fradio。我们从friends. htm复制了这个单选按钮HTML文本,但我们意在展示如何使用Python来生成更多的动态输出——见22〜27行的for循环。
showForm()函数负责对用户输入生成表单页。它为单选按钮创建了一个文字集,并把这些HTML文本行合并到了formhtml主体中,然后给表单加上头信息,最后通过把整个字符串输出到标准输出的方式给客户端返回了整块数据。
例20.5 生成表单和结果页面(friends2.py)
将friends.html和friendsl.py合并成friends2.py。得到的脚本可以同时显示表单和动态生成的HTML结果页面,同时可以巧妙地知道应该输出哪个页面。


这段代码中有两件有趣的事值得注意。第一点是表单中12行action处的“hidden”变量,这里的值为“edit”。我们决定显示哪个页面(表单页面或是结果页面)的唯一途径是通过这个字段。我们将在第53~56行看到这个字段如何起作用。
还有,请注意我们在生成所有按钮的循环里把单选按钮0设置为默认按钮。这表明我们可以在一行代码里(第18行)更新单选按钮的布局和/或它们的值,而不用再写多行文字。这也同时提供了更多的灵活性,可以用逻辑来判断哪个单选按钮被选中,见我们脚本的下一个升级版,后面的friends3.py。
现在你或许会想“既然我也可以选择person或howmany是否出现,那为什么我们要用一个action变量呢? ”这是一个很好的问题,因为在这种情况下你当然可以只用person或hwomany。
然而,action变量代表了一种更明显的出现,不光是它的名字还有它的作用,其代码很容易理解。person和howmany变量都是对其值起作用,而action变量则被用作一个标志。
创立action的另一个原因是我们将会再一次使用它来帮助我们决定生成哪一页。具体来说,我们需要在person变量出现时会显示一个表单(而不是生成结果页面)——如果在这里仅依赖person变量,你的代码运行将失败。
31 ~ 39行
显示结果页的代码实际上和friendsl.py中的一样。
41 ~ 56行
因为这个脚本可以产生出不同的页面,所以我们创建了一个包括一切的process()函数来获得表单数据并决定采用何种动作。看起来process()的主体部分也和friendsl.py中主体部分的代码相似。然而它们有两个主要的不同。
因为这个脚本也许可以,也许不能取得所期待的字段(例如,第一次运行脚本时生成一个表单页,这样的话就不会给服务器传递任何字段),我们需要用if语句把从表单项取得的值“括起来”,并检查它们此时是否有效。还有我们上面提到的action字段,它可以帮助我们判定应生成哪一个页面。第53〜56行作了这种判定。
在图20-7和图20-8中,你会先看到脚本生成的表单页面(已经输入了一个名字并选择了一个单选按钮),然后是结果页面,也是这个脚本生成的。
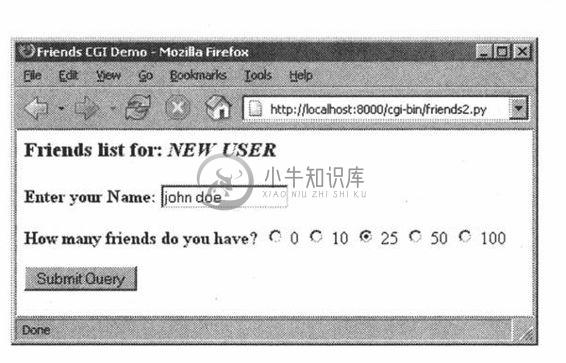
图 20-7 Friends表单页面在Win32操作系统Firefox1.x浏览器上的显示(friends2.py)
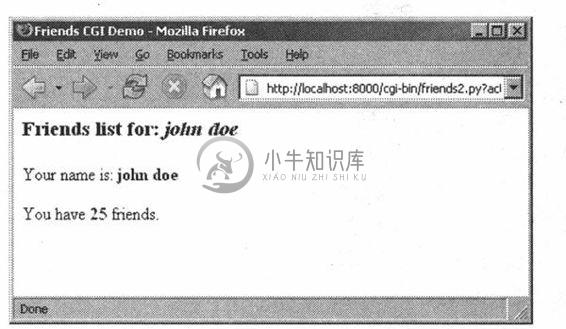
图 20-8 Friends结果页面在Win32操作系统Firefox浏览器上的显示(friends2.py)
如果看一下位置或“转到”栏,你将不会看到一个对friends. htm静态文件的URL,而在图20-4和图20-5中都有。
20.5.5 全面交互的Web站点
我们最后一个例子将会完成这个循环。如在前面中,用户在表单页中输入他的信息,然后我们处理这些数据,并输出一个结果页面。现在我们将会在结果页面上加个链接允许返回到表单页面,但是我们返回的是含有用户输入信息的页面而不是一个空白页面。我们页加上了一些错误处理程序,来展示它是如何实现的。
现在在例子20.6中我们展示我们最后的更新,friends3.py。
friends3.py和friends2.py没有太大的不同。我们请读者比较不同处;这里我们简要的介绍了主要的不同点。
简略的逐行解释
第8行
我们把URL从表单中抽出来是因为现在有两个地方需要它,结果页面是它的新顾客。
10 ~ 19行、69 ~ 71行、75 ~ 82行
所有这些行都用来处理新特性——错误页面。如果用户没有选择单选按钮,指明朋友数量,那么howmany字段就不会传送给服务器,在这种情况下,showError()函数会返回一个错误页面给客户。
错误页面的显示使用了JavaScript的“后退”按钮。因为按钮都是输入类型的,所以需要一个表单,但不需要有动作,因为我们只是简单地后退到浏览器历史中的上一个页面。尽管我们的脚本目前只支持(或者说探测、测试)一种类型的错误,但我们仍然使用了一个通用的error变量,这是为了以后还可以继续开发这个脚本,给它增加更多的错误检测。
例20.6 全用户交互和错误处理(friends3.py)
通过加上返回输入信息的表单页面的连接,我们实现了整个循环,给了用户一次完整的Web应用体验。我们的应用程序现在也进行了一些简单的错误验证,在用户没有选择任何单选按钮时,可以通知用户。


第27行、38 ~ 41行、49行、52 ~ 55行
这个脚本的一个目的是创建一个有意义的链接,以便从结果页面返回表单页面。当有错误发生时,用户可以使用这个链接返回表单页面去更新他/她填写的数据。新的表单页面只有当它包含了用户先前输入的信息时才有意义(如果让用户重复输入这些信息会很令人沮丧)。
为了实现这一点,我们需要把当前值嵌入到更新过的表单中。在第27行,我们给name新增了一个值。这个值如果给出的话,会被插入到name字段。显然,在初始表单页面上它将是空值。第38〜41行,我们根据当前选定的朋友数目设置了单选按钮。最后,通过第49行和第52〜55行更新了的doResults()函数,我们创建了这个包含已有信息的链接,它会让用户“返回”到我们更改后的表单页面。
62行
最后我们从美学角度上加了一个简单的特性。在friendsl.py和friends2.py的截屏中,可以看到返回结果和用户的输入一字不差。在上述的截屏中,如果用户的名字没有大写这将影响返回的页面。我们加了一个对string.capwords()函数的调用从而自动的将用户名置成大写。capwords()函数可以将传进来的每个单词的第一个字母置成大写的。这也许是或许不是必要的特性,但是我们还是愿意一起分享它,以便你知道这个功能的存在。
下边我们将会展示4个截屏,表明用户和CGI表单及脚本的交互过程。
在图20-9中,我们调用friends3.py生成了一个熟悉的新表单页面。输入”fool bar”,同时故意忘记检查单选按钮。单击Submit按钮后将会返回错误页面,请看图20-10。

图 20-9 Friends的初始表单页面在MacOS X操作系统Camino浏览器上的显示(friends3.py)

图 20-10 Friends的错误页面(无效的用户输入)在Camino浏览器上的显示(Friends3.py)
我们单击“后退”按钮,选择“50”单选按钮,重新提交表单。结果页面如图20-11所示,看起来很熟悉,但是现在在页面底部有个额外的连接。这个连接将会把我们带到表单页面。新表单页面和最初的页面的唯一区别是所有用户输入的数据都被设置成了”默认值”,这意味着这些值在表单中已经存在了。我们可以看图20-12。

图 20-11 带有当前信息的更新后的friends表单页面

图 20-12 friends结果页面(无效输入)(friends3.py)
这时用户可以更改任何一个字段,或者重新提交表单。
毫无疑问你会开始注意到我们的表单和数据已经变得复杂多了,生成的HTML页面是这样,结果页面更是复杂。如果你有HTML文本和应用程序的接入点的话,你可能会考虑与Python的HTMLgen模块的连接,HTMLgen是Python的一个扩展模块,专用于生成HTML页面。
20.6 在CGI中使用Unicode编码
在第6章中,我们介绍了Unicode字符串的使用。在6.8.5部分,我们给了个简单的例子脚本:取得Unicode字符串,写入一个文件,并重新读出来。在这里,我们将演示一个具有Unicode输出的简单CGI脚本,并给浏览器足够的提示,从而可以正确的生成这些字符。唯一的要求是你的计算机必须装有对应的东亚字体以便浏览器可以显示它们。
为了看到Unicode的作用,我们将会用CGI脚本生成一个多语言功能的Web页面。首先我们用Unicode字符串定义一些消息。我们假设你的编辑器只能输入ASCII编码。因此,非ASCII编码的字符使用\u转义符输入。实际上从文件或数据库中也能读取这些消息。

CGI产生的第一个头信息指出内容类型(content-type)是HTTP。此处还声明了消息是以UTF-8编码进行传输的,这点很重要,这样浏览器才可以正确的解释它。

例20.7 简单Unicode CGI示例(uniCGI.py)
这个脚本输出到你Web浏览器端的是Unicode字符串。

然后输出真正的消息。事先用string类的encode()方法先将这个字符串转换成UTF-8序列。
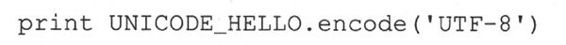
例20.7中显示了完整的程序。
如果你在你的浏览器中运行这个CGI,你将会获得如图20-13所示的输出。
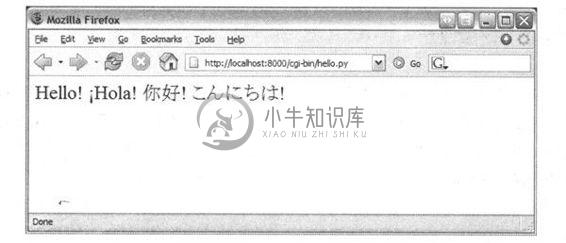
图 20-13 简单的CGI Unicode编码在Firefox上的输出(uniCGI.py)
20.7 高级CGI
现在我们来看看CGI编程的高级方面。这包括cookie的使用(保存在客户端的缓存数据),同一个CGI字段的多重值和用multipart表单实现的文件上传。为了节省空间,我们将会在同一个程序中向你展示这三个特性。首先让我们看一下多次提交问题。
20.7.1 Mulitipart表单提交和文件的上传
目前,CGI特别指出只允许两种表单编码,即”application/x-www-form-urlencoded”和”multipart/form-dat”。由于前者是默认的,就没有必要像下边那样在FORM标签里声明编码方式。

但是对于multipart表单,你需要像这样明确给出编码:

在表单提交时你可以使用任一种编码,但在目前上传的文件仅能表现为multipart编码。Multipart编码是由网景在早期开发的,但是已经被微软(开始于IE4)和其他浏览器采用。
通过使用输入文件类型完成文件上传:

这个指令表现为一个空的文本字段,同时旁边有个按钮,可以让你浏览文件目录系统,找到要上传的文件。在使用multipart编码时,你客户端提交到服务器端的表单看起来会很像带有附件的email。同时还需要有一个单独的编码,因为它还没有聪明到”通过URL编码”的程度,尤其是对一个二进制文件。这些信息仍然会到达服务器,只是以一种不同的”封装”形式而已。
不论你使用的是默认编码还是multipart编码,cgi模块都会以同样的方式来处理它们,在表单提交时提供键和相应的值。你还可以像以前那样通过FieldStorage实例来访问数据。
20.7.2 多值字段
除了上传文件,我们将会展示如何处理具有多值的字段。最常见的情况就是你有一系列的复选框允许用户有多个选择。每个复选框都会标上相同的字段名,但是为了区分它们,会有不同的值与特定的复选框关联。
正如你所知道的,在表单提交时,数据从用户端以键-值对形式发送到服务器端。当提交不止一个复选框时,就会有多个值对应同一个键。在这种情况下,cgi模块将会建立一个这类实例的列表,你可以遍历获得所有的值,而不是为你的数据指定一个MiniFielStorage实例。总的来说不是很痛苦。
20.7.3 cookie
最后,我们会在例子中使用cookie。如果你对cookie还不太熟悉的话,可以把它们看成是Web站点服务器要求保存在客户端(例如浏览器)上的二进制数据。
由于HTTP是一个”无状态信息”的协议,如你在本章最开始看到的截图一样,是通过GET请求中的键值对来完成信息从一个页面到另一个页面的传递。实现这个功能的另外一种方法如我们以前看到的一样,是使用隐藏的表单�段,如在后期friends.py脚本中对action变量的处理。这些信息必须被嵌入新生成的页面中并返回给客户端,所以这些变量和值由服务器来管理。
还有一种可以保持对多个页面浏览连续性的方法就是在客户端保存这些数据。这就是引进cookie的原因。服务器可以向客户端发送一个请求来保存cookie,而不必用在返回的Web页面中嵌入数据的方法来保持数据。cookie连接到最初的服务器的主域上(这样一个服务器就不能设置或者覆盖其他服务器上的cookie),并且有一定的生存期限(因此你的浏览器不会堆满cookie)。
这两个属性是通过有关数据条目的键-值对和cookie联系在一起的。cookie还有一些其他的属性,如域子路径、cookie安全传输请求。
有了cookie,我们不再需要为了跟踪用户而将数据从一页传到另一页了。虽然这在隐私问题上也引发了大量的争论,多数Web站点还是合理地使用了cookie。为了准备代码,在客户端获得请求文件前,Web服务器向客户端发送”SetCookie”头文件要求客户端存储cookie。
一旦在客户端建立了cookie, HTTP_COOKIE环境变量会将那些cookie自动放到请求中发送给服务器。cookie是以分号分隔的键值对存在’。要访问这些数据,你的应用程序就要多次拆分这些字符串(也就是说,使用str.split()或者手动解析)。cookie以分号(;)分隔,每个键-值对中间都由等号(=)分开。
和multipart编码一样,cookie同样起源于网景,他们实现了cookie并制定出第一个规范并沿用至今,在下边的Web站点中你可以接触这些文档:http://www.netscape.com/newsref/std/cookie_spec.html。
一旦cookie标准化以后,这些文档最终都被废除了,你可以从评论请求文档(Request for Comment,RFC)中获得更多现在的信息。现今发布的最新的cookie的文件是RFC 2109。
20.7.4 使用高级CGI
现在我们来展示CGI应用程序advcgi.py,它的代码号功能和本章前部分讲到的friends3.py的差别不是很大。默认的第一页是用户填写的表单,它由4个主要部分组成:用户设置cookie字符串、姓名字段、编程语言复选框列表、文件提交框。在图20-14中可以看到示图。
图20-15是在另一个浏览器看到的表单效果图,在这个表单中,我们可以输入自己的信息,如图20-16中给的样式。注意查找文件的按钮在不同的浏览器中显示的文字是不同的,如“Browse…”、“Choose”、“…”等。
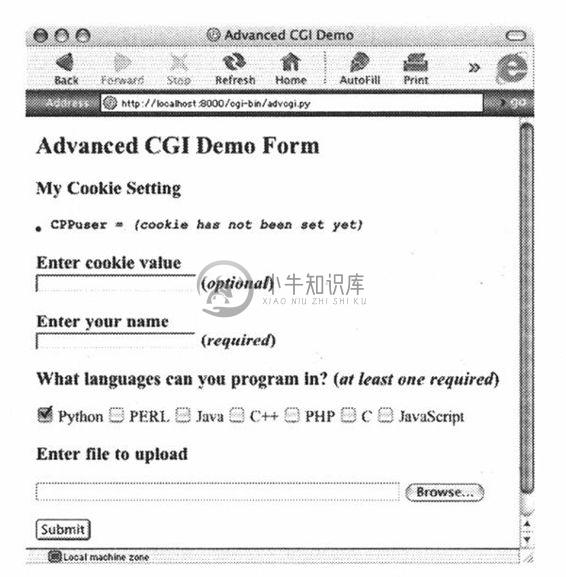
图 20-14 MacOS X系统IE5浏览器中上传及填写多值表单页
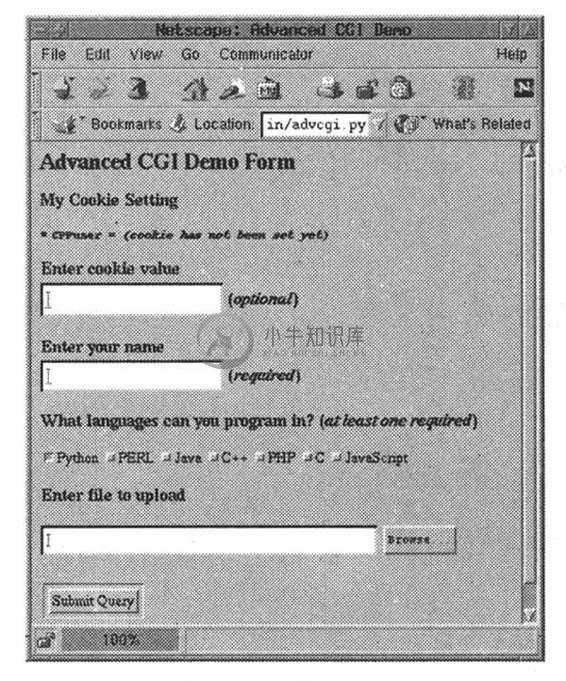
图 20-15 Linux系统Netscape4浏览器中的同一个高级CGI
这些数据以mutipart编码提交到服务器端,在服务器端以同样的方式用FieldStorage实例获取。唯一不同的就是对上传文件的检索。在我们的应用程序中,我们选择的是逐行读取,遍历文件。如果你不介意文件的大小的话,也可以一次读入整个文件。
由于这是服务器端第一次接到数据,这时,当我们向客户端返回结果页面时,我们使用”SetCookie:”头文件来捕获浏览器端的cookie。
在图20-17中,你可以看到数据提交后的结果展示。用户输入的所有数据都可以在页面中显示出来。在最后对话框中指定的文件也被上传到了服务器端,并显示出来。
你也会注意到在结果页面下方的那个链接,它使用相同的CGI脚本,可以帮我们返回表单页。
如果我们单击下方的那个链接,没有任何表单数据提交给我们的脚本,因此会显示一个表单页面。然而,如你在图20-17中看到的一样,所有的东西都可以显示出来,并非是一个空的表单!我们前边输入的信息都被显示出来了!在没有表单数据的情况下我们是怎样做到这一点的呢(将其隐藏或者作为URL中的请求参数)?实际上秘密是这些数据都被保存在客户端的cookie中了。
用户的cookie将用户输入表单中的值都保存了起来,用户名、使用的语言、上传文件的信息都会存储在cookie中。
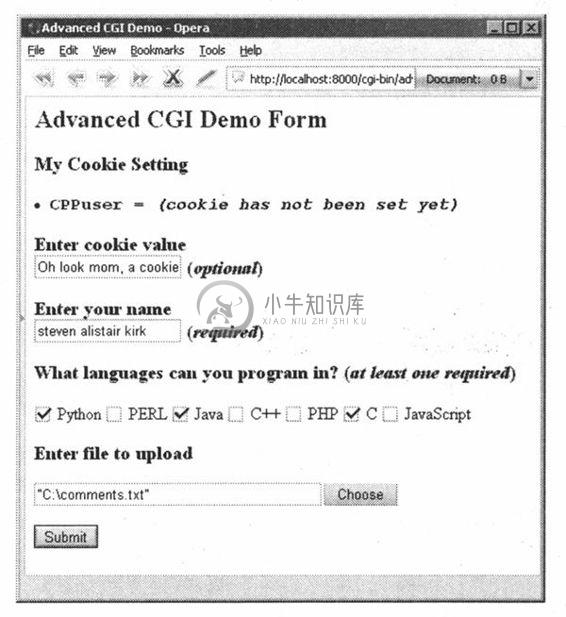
图 20-16 高级CGI提交演示,Win32系统Opera 8浏览器
当脚本检测到表单没有数据时,它会返回一个表单页面,但是在表单页面建立前,它们从客户端的cookie中抓取了数据(当用户在单击了那个链接的时候将会自动传入)并且相应的将其填入表单中。因此当表单最终显示出来时,先前的输入便会魔术般地显示在用户面前(如图20-18所示)。
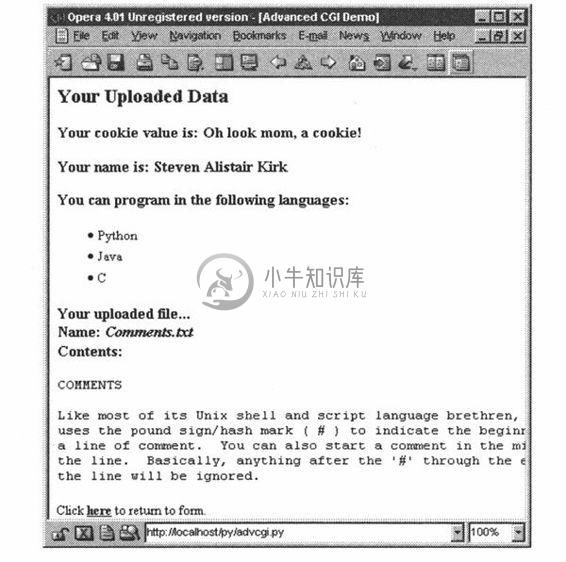
图 20-17 由Web服务器生成和返回的结果页面,Win 32系统Opera 4浏览器
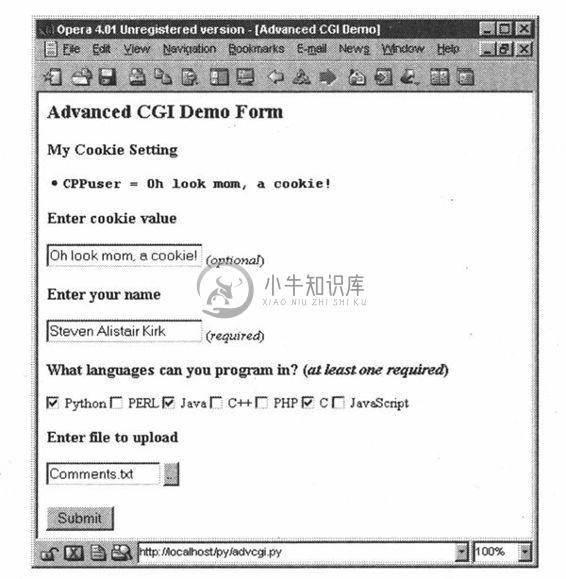
图 20-18 通过客户端cookie载入数据的表单页
我们相信你现在已经迫不及待的想看下这个程序了,详见例20.8。
advcgi.py和我们本章前部分提到的CGI脚本friends3.py相当像,它有表单页、结果页、错误页可以返回。新的脚本中除了有所有的高级CGI特性外,还在脚本中增加了更多的面向对象特征:用类和方法代替了一系列的函数。我们页面的HTML文本对我们的类来说都是静态的了,这就意味着它们在实例中都是以常量出现的——虽然我们这里仅有一个实例。
逐行(逐块)解释
1 ~ 7行
普通的起始和模块导入行出现在这里。你可能不太熟悉的唯一模块是cStringIO,我们曾在第10章简单讲解过它并在例20.1中用过。cStringIO.StingIO()会在字符串上创建一个类似文件的对象,所以访问这个字符串与打开一个文件并使用文件句柄去访问数据很相似。
9 ~ 12行
在声明AdvCGI类之后,header和url(静态)变量被创建出来,在显示所有不同页面的方法中会用到这些变量。
14 ~ 80行
所有这个块中的代码都是用来创建、显示表单页面的。那些数据属性都是不言自明的。getCPPcookie()取得Web客户端发来的cookie信息,而showForm()校对所有这些信息并把表单页面返回给客户端。
82 ~ 91行
这个代码块负责错误页面。
93 ~ 144行
结果页面的生成使用了本块代码。setCPPcookie()方法要求客户端为我们的应用程序存储cookie,而doResults()方法聚集所有数据并把输出发回客户端。
例20.8 高级CGI应用(asvcgi.py)
这个脚本有一个处理所有事情的主函数,AdvCGI,它有方法显示表单、错误或结果页面,同时也可以从客户端(Web浏览器)读写cookie。





doResults()方法收集所有数据并把输出发回客户端。
146 ~ 196行
脚本一开始就实例化了一个AdvCGI页面对象,然后调用它的go()方法让一切运转起来,这和严格的基于过程编写的程序不同。go()方法中包含读取所有新到的数据并决定显示哪个页面的逻辑。
如果没有给出名字或选定语言,错误页面将会被显示。如果没有收到任何输入数据,将调用showForm()方法来输出表单,否则将调用doResults()方法来显示结果页面。通过设置self.error变量可以创建错误页面,这样做有两个目的。它不但可以让你把错误原因设置在字符串里,并且可以作为一个标记表明有错误发生。如果该变量不为空,用户将会被导向到错误页面。
处理person字段(第154~159行)的方法和我们先前看到的一样,一个键-值对;然而,在收集语言信息时却需要一点技巧,原因是我们必须检查一个(Mini) FieldStorage对象或一个该对象的列表。我们将使用熟悉的type()内建函数来达到目的。最终,我们会有一个单独或多个语言名的列表,具体依赖于用户的选择情况。
使用cookie(第161~165行)来保管数据展示了如何利用它们来避免使用任何类型的CGI字段。你一定注意到了代码里包含这些数据的地方没有调用CGI处理,这意味着数据并非来自FieldStorage对象。这些数据是由Web客户端通过每一次请求和从cookie取得的值(包括用户的选择结果和用来填充后续表单的已有信息)传给我们的。
因为showResults()方法从客户那里取得了新的收入值,所以它负责通过调用setCPPcookie()设置cookie。而showForm()必须读出cookie中的值才能用表单页显示用户的当前选项。这通过它对getCPPcookie()的调用实现。
最后,我们看看文件上传处理(第178~187行)。不论一个文件是否已经上传,FieldStorage都会从file属性中获得一个文件句柄。在第180行,如果没有指明文件名,那么我们只须把它设成空字符串。如果访问过value属性,那么文件的整个内容都会被放到value里。还有一个更好的做法,你可以去访问文件指针——file属性——并且可以每次只读一行或者其他更慢一些的处理方法。
在我们的例子里,文件上传只是用户提交过程的一部分,所以我们可以简单地把文件指针传给doResults()函数,从文件中抽取数据。由于空间限制doResults()将只显示文件最前面1K的内容,这也表明显示一个4M的二进制文件是没必要(或未必有效/有用)的。
20.8 Web(HTTP)服务器
到现在为止,我们已经讨论了如何使用Python建立Web客户端并用CGI请求处理帮助Web服务器执行了一些工作。我们通过第20.2节和第20.3节的学习知道了Python可以用来建立简单和复杂的Web客户端,而对复杂的CGI请求没有说明。
然而,我们在这章的焦点是探索建立Web服务器。如果说Firefox、Mozilla、IE、Opera、Netscape、AOL、Safari、Camino、Epiphany、Galeon和Lynx浏览器是最流行的一些Web客户端,那么什么是最常用的Web服务器呢?它们就是Apache、Netscape IIS、thttpd、Zeus和Zope。由于这些服务器都远远超过了你的应用程序要求,这里我们使用Python建立简单但有用的Web服务器。
用Python建立Web服务器
由于已经打算建立这样的一个应用程序,很自然就需要创建个人素材,但是你将要用到的所有的基础代码都在Python的标准库中。要建立一个Web服务、一个基本的服务器和一个“处理器”是必备的。
基础的(Web)服务器是一个必备的模具。它的角色是在客户端和服务器端完成必要HTTP交互。在BaseHTTPServer模块中可以找到一个名叫HTTPServer的服务器基本类。
处理器是一些处理主要“Web服务”的简单软件。它们处理客户端的请求,并返回适当的文件,静态的文本或者由CGI生成的动态文件。处理器的复杂性决定了你的Web服务器的复杂程度。Python标准库提供了三种不同的处理器。
最基本、最普通的是vanilla处理器,被命名为BaseHTTPResquestHandler,这个可以在基本Web服务器的BaseHTTPServer模块中找到。除了获得客户端的请求外,不再执行其他的处理工作,因此你必须自己完成它们,这样就导致了myhttpd.py服务的出现。
用于SimpleHTTPServer模块中的SimpleHTTPRequestHandler建立在BaseHTTPResquestHandler基础上,直接执行标准的GET和HEAD请求。这虽然还不算完美,但已经可以完成一些简单的功能了。
最后,我们来看下用于CGIHTTPServer模块中的CGIHTTPRequestHandler处理器,它可以获取SimpleHTTPRequestHandler并为POST请求提供支持。它可以调用CGI脚本完成请求处理过程,也可以将生成的HTML脚本返回给客户端。
这三个模块和他们的类在表20.6中有描述。
为了能理解在SimpleHTTPServer和CGIHTTPServer模块中的其他高级处理器是如何工作的,我们将对BaseHTTPRequestHandler实现简单的GET处理功能。
在例20.9中,我们展示了一个Web服务器(myhttpd.py)的全部工作代码。
这个服务的子类BaseHTTPRequestHandler只包含do_GET()方法,在基础服务器接到GET请求时被调用。尝试打开客户端传来的路径,如果实现了,将会返回”OK”状态(200),并转发下载的Web页面,否则将会返回404状态。
main()函数只是简单的将Web服务器类实例化,然后启动它进入永不停息的服务循环,如果遇到了^C中断或者类似的键输入则会将其关闭。如果你可以访问并运行这个服务器,你就会发现它会显示出一些类似这样的登录输出:

当然,我们的Web服务器实在太简单了,它甚至还不能处理普通的文本文件。我们将这部分的解决方案留给读者研发——在本章最后的练习题中。
正如你所看到的一样,建立一个Web服务器并在纯Python脚本中运行并不会花太多时间。为你的特定应用程序定制改进处理器将需要做更多事情。请查看本部分的相关库来获得更多模块及其类的信息。
例20.9 简单Web服务器(myhttpd.py)
这个简单的Web服务器可以读取GET请求,获取Web页面(.html文件)并将其返回给客户端。它通过使用BaseHTTPServer的BaseHTTPRequestHandler处理器执行do_GET()方法来处理GET请求。


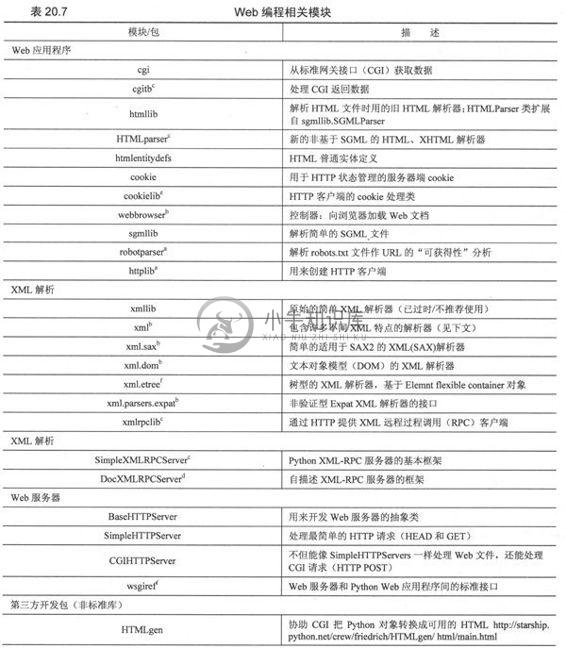
20.9 相关模块
在表20.7中,我们列出了对Web开发有用的模块。也许你会想看下第17章的因特网客户端编程,还有第23章的Web服务部分的模块,这些对Web应用都是很有用的。

20.10 练习
20-1.urllib模块及文件。
请修改friends3.py脚本,把名字和相应的朋友数量存储在一个两列的磁盘文本文件中,以后每次运行脚本都添加名字。附加题:增加一些代码把这种文件的内容转储到Web浏览器里(以HTML格式)。附加题:增加一个链接,用以清空文件中的所有名字。
20-2.urllib模块。编写一个程序,它接收一个用户输入的URL(可以是一个Web页面或一个FTP文件,例如,http://python.org或ftp://ftp.python.org/pub/python/README),然后下载它并以相同的文件名(如果你的系统不支持也可以把它改成和原文件相似的名字)存储到电脑上。Web页面(HTTP)应保存成。htm或。html文件,而FTP文件应保持其扩展名。
20-3.urllib模块。重写例11.4的grabWeb.py脚本,它会下载一个Web页面,并显示生成的HTML文件的第一个和最后一个非空白行,你应使用urlopen()来代替urlretrieve()来直接处理数据(这样就不必先下载所有文件再处理它了)。
20-4.URL和正则表达式。你的浏览器也许会保存你最喜欢的Web站点的URL,并把它们保存成”书签”里的一个HTML文件(Mozilla衍生浏览器)或是”收藏夹”中的一组URL文件(IE)。找出你浏览器记录”热门链接”的方法,并找出其所在和存储方式。不去更改任何文件,剔除对应Web站点(如果给定了的话)的URL和名字,生成一个以名字和链接作为输出的双列列表,并把这些数据保存到硬盘文件中。截取站点名和URL,确保每一行的输出不超过80个字符。
20-5.URL、urllib模块、异常、已编码正则表达式。作为对上一个问题的延伸,给你的脚本增加代码来测试你所喜欢的链接。记录无效链接(及其名字),包括无效的Web站点和已经被删除的Web页面。只输出并在磁盘中保存依然有效的链接。
20-6.错误检测。friends3.py脚本在没有选择任意一个单选按钮指定好友的数目时会返回一个错误提示。在更新CGI脚本时如果没有输入名字(例如空字符或空白)也会返回一个错误。附加题:目前为止我们探讨的仅是服务器端的错误检测。研究JavaScript编程,并通过创建JavaScript代码来同时检测错误,以确保这些错误在到达服务器前被终止,这样便实现了客户端错误检测。下面的问题20-7~问题20-10涉及Web服务器的访问日志文件和正则表达式。Web服务器(及其管理员)通常需要保存访问日志文件(一般是主Web的server文件夹里的logs/access_log)来跟踪文件请求。一段时间之后,这些逐渐变大的文件需要被保存或删节。为什么不能仅保存有用的信息而删除这些文件来节省磁盘空间呢?通过下面的习题,你会练习正则表达式和如何使用它们进行归档及分析Web服务器数据。
20-7.计算日志文件中有多少种请求(GET vs POST)。
20-8.计算成功下载的页面/数据:显示所有返回值为200 (OK(没有错误发生))的链接,以及每个链接被访问的次数。
20-9.计算错误:显示所有产生错误的链接(返回值为400或500)以及每个链接被访问的次数。
20-10.跟踪IP地址:对每个IP地址’输出每个页面/数据下载情况的列表,以及这些链接被访问的次数。
20-11.简单CGI。为Web站点创建”评论”或”反馈”页面。由表单获得用户反馈,在脚本中处理数据,最后返回一个”感谢”页面。
20-12.简单CGI。创建一个Web客户簿。接受用户输入的名字、电子邮件地址、日志,并将其保存到文件中(自定义格式)。类似上一个题,返回一个”感谢你对本页的填写”页面。同时再给用户提供一个查看客户簿的链接。
20-13.Web浏览器Cookie和Web站点注册。更改你对习题20-4的答案。你现在可以使用用户名-密码信息来注册Web站点,而不必只用简单的基于文本的菜单系统。附加题:想办法让自己熟悉Web浏览器cookie,并在最后登录成功后将会话保持4个小时。
20-14.Web客户端。移植例20.1的Web爬虫脚本crawler.py,使用HTMLParser模块或BeautifulSoup解析系统。
20-15.错误处理。当一个CGI脚本崩溃时会发生什么?如何用cgitb模块提供帮助?
20-16.CGI、文件升级及Zip文件。创建一个不仅能保存文件到服务器磁盘,而且能智能解压Zip文件(或其他压缩档)到同名子文件夹的CGI应用程序。
20-17.Zope、Plone、TurboGears及Django。研究每一个复杂的Web开发平台并分别创建一个简单的应用程序。
20-18.Web数据库应用程序。思考对你Web数据库应用程序支持的数据库构架。对于多用户的应用程序,你需要支持每个用户对数据库的全部内容的访问,但每个人可能分别输入。一个例子就是你家人及亲属的”地址簿”。每个成员成功登录后,显示出来的页面应该有几个选项”添加条目”、”查看我的条目”、”更新条目”、”移动或删除条目”以及”查看所有条目”。
20-19.电子商务引擎。使用你在习题13-11中建立的类,增加一些产品清单建立一个电子商务Web站点。确保你的应用程序支持多个用户,机器每个用户的注册功能。
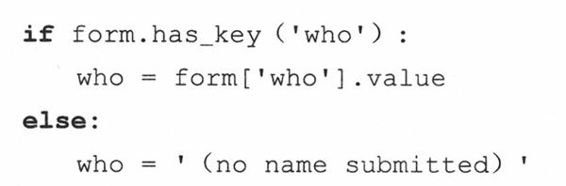
20-20.字典及cgi模块相关。正如你所知道的,cgi.FieldStorage()方法返回一个字典类对象,包括提交的CGI变量的键值对。你可以使用这个对象的keys()和has_key()方法。在Python1.5中,get()方法被添加到字典中,用它可以返回给定键的值,当键不存在时返回一个默认值。FieldStorage对象却没有这个方法。让我们依照用户手册的形式:

为cgi.py中类的定义添加一个类似的get()方法(你可以把它重命名为mycgi.py或其他你喜欢的名字),以便能像下面这样操作:
…也可以用一行实现,这样就更像字典的形式了:

20-21.高级Web客户端。在20.7小节中的myhttpd.py代码只能读取HTML文件并将其返回到客户端。添加对以”.txt”结束的普通的文本的支持。确保返回正确的”text/plain” de MIME类。附加题:添加对以”.jpg”及”.jpeg”结束的JPEG文件的支持,并返回”image/jpeg”的MIME类型。
20-22.高级Web客户端。作为crawl.py的输入的URL必须是以”http://”协议指示符开头,高层的URL必须包含一个反斜线,例如:http://www.prenhallprofessional.com/。加强crawl.py的功能,允许用户只输入主机名(没有协议部分[确保是HTTP]),反斜线是可选的。例如:www.prenhallprofessional.com应该是可接受的输入形式。
20-23.高级Web客户端。更改20.3小节中的crawl.py脚本,让它也下载”ftp:”型的链接。所有的“mailto:”都会被crawl.py忽略。增加代码确保它也忽略”telnet:”、”news:”、”gopher:”和”about:”型的链接。
20-24.高级Web客户端。20.3小节中的crawl.py脚本仅从相同站点内的Web页面中找到链接,下载了。html文件,却不处理/保存图片这类对页面同样有意义的”文件”。对于那些允许URL缺少末端斜线(/)的服务器,这个脚本也不能处理。给crawl.py增添两个类来解决这些问题。
一个是urllib.FancyURLOpener类的子类My404UrlOpener,它仅包含一个方法,http_error_404(),用该方法来判断收到的404错误中是不是包含缺少末端斜线的URL。如果有,它就添加斜线并重新请求(仅一次)。如果仍然失败,才返回一个真正的404错误。你必须用该类的一个实例来设置urllib._urlopener,这样urllib才能使用它。
创建另一个类LinklmageParser,它派生自htmllib.HTMLParser。这个类应有一个构造器用来调用基类的构造器,并且初始化一个列表用来保存从Web页面中解析出的图片文件。应重写handle_image()方法,把图片文件名添加到图片列表中(这样就不会像现在的基类方法那样丢弃它们了)。