
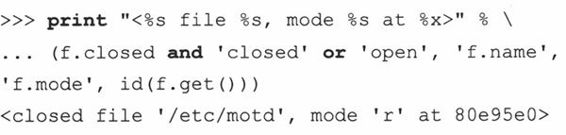
第13章 面向对象编程
本章主题
♦ 引言
♦ 面向对象编程
♦ 类
♦ 实例
♦ 绑定与方法调用
♦ 子类,派生和继承
♦ 内建函数
♦ 定制类
♦ 私有性
♦ 授权与包装
♦ 相关模块
♦ 新式类的高级特性
在我们的描绘中,类最终解释了面向对象编程(OOP, object-oriented programming)思想。本章中,我们首先将给出一个总体上的概述,涵盖了Python中使用类和OOP的所有主要方面。其余部分针对类,类实例和方法进行详细探讨。我们还将描述Python中有关派生或子类化及继承机理。最后,Python可以在特定功能方面定制类,例如重载操作符,模拟Python类型等。我们将展示如何实现这些特殊的方法来自定义你的类,以让它们表现得更像Python的内建类型。
然而,除了这些外,Python的面向对象编程(OOP)还有一些令人兴奋的变动。在版本2. 2中,Python社区最终统一了类型(type)和类(classe),新式类具备更多高级的OOP特性,扮演了一个经典类(或者说旧式类)超集的角色,后者是Python诞生时所创造的类对象。
下面,我们首先介绍在两种风格的类(译者注:新式类和旧式类)中都存在的核心特性,然后讲解那些只有新式类才拥有的的高级特性。
13.1 引言
在摸清OOP和类的本质之前,我们首先讲一些高级主题,然后通过几个简单的例子热一热身。如果你刚学习面向对象编程,你可以先跳过这部分内容,直接进入第13. 2节。如果你对有关面向对象编程已经熟悉了,并且想了解它在Python中是怎样表现的,那么先看一下这部分内容,然后再进入第13. 3节,一探究竟!
在Python中,面向对象编程主要有两个主题,就是类和类实例(见图13-1)。

图 13-1
1. 类与实例
类与实例相互关联着:类是对象的定义,而实例是“真正的实物”,它存放了类中所定义的对象的具体信息。
下面的示例展示了如何创建一个类:

关键字是class,紧接着是一个类名。随后是定义类的类体代码。这里通常由各种各样的定义和声明组成。新式类和经典类声明的最大不同在于,所有新式类必须继承至少一个父类,参数bases可以是一个(单继承)或多个(多重继承)用于继承的父类。
object是“所有类之母”。如果你的类没有继承任何其他父类,object将作为默认的父类。它位于所有类继承结构的最上层。如果你没有直接或间接的子类化一个对象,那么你就定义了一个经典类:

如果你没有指定一个父类,或者如果所子类化的基本类没有父类,你这样就是创建了一个经典类。很多Python类都还是经典类。即使经典类已经过时了,在以后的Python版本中,仍然可以使用它们。不过我们强烈推荐你尽可能使用新式类,尽管对于学习来说,两者都行。
左边的工厂制造机器相当于类,而生产出来的玩具就是它们各个类的实例。尽管每个实例都有一个基本的结构,但各自的属性像颜色或尺寸可以改变——这就好比实例的属性。
创建一个实例的过程称作实例化,过程如下(注意:没有使用new关键字):
类名使用我们所熟悉的函数操作符(()),以“函数调用”的形式出现。然后你通常会把这个新建的实例赋给一个变量。赋值在语法上不是必须的,但如果你没有把这个实例保存到一个变量中,它就没用了,会被自动垃圾收集器回收,因为任何引用指向这个实例。这样,你刚刚所做的一切,就是为那个实例分配了一块内存,随即又释放了它。
类既可以很简单,也可以很复杂,这全凭你的需要。最简单的情况,类仅用作名称空间(namespace)(参见第11章)。这意味着你把数据保存在变量中,对他们按名称空间进行分组,使得他们处于同样的关系空间中——所谓的关系是使用标准Python句点属性标识。例如,你有一个本身没有任何属性的类,使用它仅对数据提供一个名字空间,让你的类拥有像Pascal中的记录集(record)和C语言中的结构体(structure)一样的特性,或者换句话说,这样的类仅作为容器对象来共享名字空间。
示例如下:

注意有的地方在语法构成上需要有一行语句,但实际上不需要做任何操作,这时候可以使用pass语句。这种情况,必要的代码就是类体,但我们暂不想提供这些。上面定义的类没有任何方法或属性。下面我们创建一个实例,它只使用类作为名称空间容器。


我们当然也可以使用变量“x”,“y”来完成同样的事情,但本例中,实例名字mathObj将mathObj.x和mathObj.y关联起来。这就是我们所说的使用类作为名字空间容器。mathObj.x和mathObj.y是实例属性,因为它们不是类MyData的属性,而是实例对象(mathObj)的独有属性。本章后面,我们将看到这些属性实质上是动态的:你不需要在构造器中,或其他任何地方为它们预先声明或者赋值。
2. 方法
我们改进类的方式之一就是给类添加功能。类的功能有一个更通俗的名字叫方法。在Python中,方法定义在类定义中,但只能被实例所调用。也就是说,调用一个方法的最终途径必须是这样的:(1)定义类(和方法);(2)创建一个实例;(3)最后一步,用这个实例调用方法。例如:

你可能注意到了self参数,它在所有的方法声明中都存在。这个参数代表实例对象本身,当你用实例调用方法时,由解释器悄悄地传递给方法的,所以,你不需要自己传递self进来,因为它是自动传入的。
举例说明一下,假如你有一个带两参数的方法,所有你的调用只需要传递第二个参数,Python把self作为第一个参数传递进来,如果你犯错的话,也不要紧。Python将告诉你传入的参数个数有误。总之,你只会犯一次错,下一次……你当然就记得了!
这种需要在每个方法中给出实例(self)的要求对于那些使用C++或Java的人可能是一种新的体验,所以请意识到这点。
Python的哲学本质上就是要明白清晰。在其他语言中,self称为“this”。可以在13. 7—节的”核心笔记”中找到有关self更多内容。一般的方法会需要这个实例(self),而静态方法或类方法不会,其中类方法需要类而不是实例。在第13. 8节中可以看到有关静态方法和类方法的更多内容。
现在我们来实例化这个类,然后调用那个方法:

在本节结束时,我们用一个稍复杂的例子来总结一下这部分内容,这个例子给出如何处理类(和实例),还介绍了一个特殊的方法__init__(),子类化及继承。
对于已熟悉面向对象编程的人来说,__init__()类似于类构造器。如果你初涉OOP世界,可以认为一个构造器仅是一个特殊的方法,它在创建一个新的对象时被调用。在Python中,__init__()实际上不是一个构造器。你没有调用”new”来创建一个新对象。(Python根本就没有“new”关键字)。取而代之,Python创建实例后,在实例化过程中,调用__init__()方法,当一个类被实例化时,就可以定义额外的行为,比如,设定初始值或者运行一些初步诊断代码——主要是在实例被创建后,实例化调用返回这个实例之前,去执行某些特定的任务或设置。
我们将把print语句添加到方法中,这样我们就清楚什么时候方法被调用了。通常,我们不把输入或输出语句放入函数中,除非预期代码体具有输出的特性。
3. 创建一个类(类定义)


在AddrBookEntry类的定义中,定义了两个方法:__init__()和updatePhone()__init__()在实例化时被调用,即,在AddrBookEntry()被调用时。你可以认为实例化是对__init__()的一种隐式的调用,因为传给AddrBookEntry()的参数完全与__init__()接收到的参数是一样的(除了self,它是自动传递的)。
回忆一下,当方法在实例中被调用时,self(实例对象)参数自动由解释器传递,所以在上面的__init__()中,需要的参数是nm和ph,它们分别表示名字和电话号码。__init__()在实例化时,设置这两个属性,以便在实例从实例化调用中返回时,这两个属性对程序员是可见的。你可能已猜到,updatePhone()方法的目的是替换地址本条目的电话号码属性。
4. 创建实例(实例化)

这就是实例化调用,它会自动调用__init__()。self把实例对象自动传入)__init__()。你可以在脑子里把方法中的self用实例名替换掉。在上面第一个例子中,当对象john被实例化后,它的john. name就被设置了,你可在下面得到证实。
另外,如果不存在默认的参数,那么传给__init__()的两个参数在实例化时是必须的。
5. 访问实例属性

一旦实例被创建后,就可以证实一下,在实例化过程中,我们的实例属性是否确实被__init__()设置了。我们可以通过解释器“转储”实例来查看它是什么类型的对象。(以后我们将学到如何定制类来获得想要的Python对象字符串的输出形式,而不是现在看到的默认的Python对象字符串(<…>))
6. 方法调用(通过实例)

updatePhone()方法需要一个参数(不计self在内):新的电话号码。在updatePhone()之后,立即检查实例属性,可以证实已生效。
7. 创建子类
靠继承来进行子类化是创建和定制新类类型的一种方式,新的类将保持已存在类所有的特性,而不会改动原来类的定义(指对新类的改动不会影响到原来的类——译者注)。对于新类类型而言,这个新的子类可以定制只属于它的特定功能。除了与父类或基类的关系外,子类与通常的类没有什么区别,也像一般类一样进行实例化。注意下面,子类声明中提到了父类:

现在我们创建了第一个子类,EmplAddrBookEntry。 Python中,当一个类被派生出来,子类就继承了基类的属性,所以,在上面的类中,我们不仅定义了__init__(), updatEmail()方法,而且EmplAddrBookEntry还从AddrBookEntry中继承了updatePhone()方法。
如果需要,每个子类最好定义它自己的构造器,不然,基类的构造器会被调用。然而,如果子类重写基类的构造器,基类的构造器就不会被自动调用了——这样,基类的构造器就必须显式写出才会被执行,像我们上面那样,用AddrBookEntry.__init__()设置名字和电话号码。我们的子类在构造器后面几行还设置了另外两个实例属性:员工ID和电子邮件地址。
注意,这里我们要显式传递self实例对象给基类构造器,因为我们不是在该实例中而是在一个子类实例中调用那个方法。因为我们不是通过实例来调用它,这种未绑定的方法调用需要传递一个适当的实例(self)给方法。
本小节后面的例子,告诉我们如何创建子类的实例,访问它们的属性及调用它的方法,包括从父类继承而来的方法。
8. 使用子类


 核心笔记:命名类、属性和方法
核心笔记:命名类、属性和方法
类名通常由大写字母打头。这是标准惯例,可以帮助你识别类,特别是在实例化过程中(有时看起来像函数调用)。还有,数据属性听起来应当是数据值的名字,方法名应当指出对应对象或值的行为。另一种表达方式是:数据值应该使用名词作为名字,方法使用谓词(动词加对象)。数据项是操作的对象、方法应当表明程序员想要在对象进行什么操作。在上面我们定义的类中,遵循了这样的方针,数据值像“name”、“phone”和“email”,行为如“updatePhone”, “updateEmail”。这就是常说的“混合记法(mixedCase)”或“骆驼记法(camelCase)” (因为单词之间没有空格但首字母都大写,这样看上去类似驼峰,故而得名。译者注)。 “Python Style Guide”推荐使用骆驼记法的下划线方式,比如,“update_phone”, “update_email”。类也要细致命名,像“AddrBookEntry”、“RepairShop”等就是很好的名字。
我希望你已初步理解如何在Python中进行面向对象编程了。本章其他小节将带你深入到面向对象编程,Python类及实例的方方面面。
13.2 面向对象编程
编程的发展已经从简单控制流中按步的指令序列进入到更有组织的方式中,依靠代码块可以形成命名子程序和完成既定的功能。结构化的或过程性编程可以让我们把程序组织成逻辑块,以便重复或重用。创建程序的过程变得更具逻辑性;选出的行为要符合规范,才可以约束创建的数据。Deitel父子(这里指DEITEL系列书籍作者Harvey M. Deitel和Paul James Deitel父子,译者注)认为结构化编程是“面向行为”的,因为事实上,即使没有任何行为的数据也必须“规定”逻辑性。
然而,如果我们能对数据加上动作呢?如果我们所创建和编写的数据片段,是真实生活中实体的模型,内嵌数据体和动作呢?如果我们能通过一系列已定义的接口(又称存取函数集合)访问数据属性,像自动取款机(ATM)卡或能访问你的银行账号的个人支票,我们就有了一个“对象”系统,从大的方面来看,每一个对象既可以与自身进行交互,也可以与其他对象进行交互。
面向对象编程踏上了进化的阶梯,增强了结构化编程,实现了数据与动作的融合:数据层和逻辑层现在由一个可用以创建这些对象的简单抽象层来描述。现实世界中的问题和实体完全暴露了本质,从中提供的一种抽象,可以用来进行相似编码,或者编入能与系统中对象进行交互的对象中。类提供了这样一些对象的定义,实例即是这些定义的实现。二者对面向对象设计(object-oriented design, OOD)来说都是重要的,OOD仅意味来创建你采用面向对象方式架构来创建系统。
13.2.1 面向对象设计与面向对象编程的关系
面向对象设计(OOD)不会特别要求面向对象编程语言。事实上,OOD可以由纯结构化语言来实现,比如C,但如果想要构造具备对象性质和特点的数据类型,就需要在程序上作更多的努力。当一门语言内建00特性,00编程开发就会更加方便高效。
另一方面,一门面向对象的语言不一定会强制你写OO方面的程序。例如C++可以被认为“更好的C”;而Java,则要求万物皆类,此外还规定,一个源文件对应一个类定义。然而,在Python中,类和OOP都不是日常编程所必需的。尽管它从一开始设计就是面向对象的,并且结构上支持OOP,但Python没有限定或要求你在你的应用中写OO的代码。OOP是一门强大的工具,不管你是准备入门、学习、过渡或是转向OOP,都可以“窥一斑而知全豹”。
13.2.2 现实中的问题
考虑用OOD来工作的一个最重要的原因,在于它直接提供建模和解决现实世界问题和情形的途径。比如,让你来试着模拟一台汽车维修店,可以让你停车进行维修。我们需要建两个一般实体:处在一个“系统”中并与其交互的人类,和一个修理店,它定义了物理位置,用于人类活动。因为前者有更多不同的类型,我将首先对它进行描述,然后描述后者。在此类活动中,一个名为Person的类被创建以用来表示所有的人。Person的实例可以包括消费者(Customer),技工(Mechanic),还可能是出纳员(Cashier) 。这些实例具有相似的行为,也有独一无二的行为。比如,他们能用声音进行交流,都有talk()方法,还有drive_car()方法。不同的是,技工有repair_car()方法,而出纳有ring_sale()方法。技工有一个repair_certification属性,而所有人都有一个drivers_license属性。
最后,所有这些实例都是一个检查(overseeing)类RepairShop的参与者,后者具有一个叫operating_hours的数据属性,它通过时间函数来确定何时顾客来修车,何时职员技工和出纳员来上班。RepairShop可能还有一个AutoBay类,拥有SmogZone, TireBrakeZone等实例,也许还有一个叫GeneralRepair的实例。
我们所编的RepairShop的一个关键点是要展示类和实例加上它们的行为是如何用来对现实生活场景建模的。同样,你可以把诸如机场、餐厅、芯片工厂、医院其至一个音乐公司想像为类,它们完全具备各自的参与者和功能性。
13.2.3 *常用术语
对于已熟悉有关OOP术语的朋友来说,看Python中是怎么称呼的:
1. 抽象/实现
抽象指对现实世界问题和实体的本质表现、行为和特征建模,建立一个相关的子集,可以用于描绘程序结构,从而实现这种模型。抽象不仅包括这种模型的数据属性,还定义了这些数据的接口。对某种抽象的实现就是对此数据及与之相关接口的现实化(realization) 。现实化这个过程对于客户程序应当是透明而且无关的。
2. 封装/接口
封装描述了对数据/信息进行隐藏的观念,它对数据属性提供接口和访问函数。通过任何客户端直接对数据的访问,无视接口与封装性都是背道而驰的,除非程序员允许这些操作。作为实现的一部分,客户端根本就不需要知道在封装之后,数据属性是如何组织的。在Python中,所有的类属性都是公开的,但名字可能被“混淆”了,以阻止未经授权的访问,但仅此而已,再没有其他预防措施了。这就需要在设计时,对数据提供相应的接口,以免客户程序通过不规范的操作来存取封装的数据属性。
3. 合成
合成扩充了对类的描述,使得多个不同的类合成为一个大的类,来解决现实问题。合成描述了一个异常复杂的系统,比如一个类由其他类组成,更小的组件也可能是其他的类,数据属性及行为,所有这些合在一起,彼此是”有一个”的关系。比如,RepairShop “有一个”技工(应该至少有一个吧),还”有一个”顾客(至少一个)。
这些组件要么通过联合关系组在一块,意思是说,对子组件的访问是允许的(对RepairShop来说,顾客可能请求一个SmogCheck,客户程序这时就是与RepairShop的组件进行交互),要么是聚合在一起,封装的组件仅能通过定义好的接口来访问,对于客户程序来说是透明的。继续我的例子,客户程序可能会建立一个SmogCheck请求来代表顾客,但不能够同RepairShop的SmogZone部分进行交互,因为SmogZone是由RepairShop内部控制的,只能通过smogCheckCar()方法调用。Python支持上述两种形式的合成。
4. 派生/继承/继承结构
派生描述了子类的创建,新类保留已存类类型中所有需要的数据和行为,但允许修改或者其他的自定义操作,都不会修改原类的定义。继承描述了子类属性从祖先类继承这样一种方式。从前面的例子中,技工可能比顾客多个汽车技能属性,但单独的来看,每个都“是一个”人,所以,不管对谁而言调用talk()都是合法得,因为它是人的所有实例共有的。继承结构表示多“代”派生,可以描述成一个“族谱”,连续的子类,与祖先类都有关系。
5. 泛化/特化
泛化表示所有子类与其父类及祖先类有一样的特点,所以子类可以认为同祖先类是“是一个”(is-a)的关系,因为一个派生对象(实例)是祖先类的一个“例子”。比如,技工“是一个”人,车“是一个”交通工具等。在上面我们间接提到的族谱图中,我们可以从子类到祖先类画一条线,表示“是一个”的关系。特化描述所有子类的自定义,也就是,什么属性让它与其祖先类不同。
6. 多态
多态的概念指出了对象如何通过他们共同的属性和动作来操作及访问,而不需考虑他们具体的类。多态表明了动态(后来又称运行时)绑定的存在,允计重载及运行时类型确定和验证。
7. 自省/反射
自省表示给予你,程序员,某种能力来进行像“手工类型检查”的工作,它也被称为反射。这个性质展示了某对象是如何在运行期取得自身信息的。如果传一个对象给你,你可以查出它有什么能力,这样的功能不是很好吗?这是一项强大的特性,在本章中,你会时常遇到。如果Python不支持某种形式的自省功能,dir()和type()内建函数,将很难正常工作。请密切关注这些调用,还有那些特殊属性,像__dict__,__name__及__doc__。可能你对其中一些已经很熟悉了!
13.3 类
回想一下,类是一种数据结构,我们可以用它来定义对象,后者把数据值和行为特性融合在一起。类是现实世界的抽象的实体以编程形式出现。实例是这些对象的具体化。可以类比一下,类是蓝图或者模型,用来产生真实的物体(实例)。因此为什么是术语“class” ?这个术语很可能起源于使用类来识别和归类特定生物所属的生物种族,类还可以派生出相似但有差异的子类。编程中类的概念就应用了很多这样的特征。
在Python中,类声明与函数声明很相似,头一行用一个相应的关键字,接下来是一个作为它的定义的代码体,如下所示:

二者都允许你在他们的声明中创建函数,闭包或者内部函数(即函数内的函数),还有在类中定义的方法。最大的不同在于你运行函数,而类会创建一个对象。类就像一个Python容器类型。在这部分,我们将特别留意类及它们有什么类型的属性。这只要记住,尽管类是对象(在Python中,一切皆对象),但正被定义时,它们还不是对象的实现。在下节中会讲到实例,所以拭目以待吧。不过现在,我们集中讲解类对象。
当你创建一个类,实际你也就创建了一个自己的数据类型。所以这个类的实例都是相似的,但类彼此之间是有区别的(因此,不同类的实例自然也不可能相同了)。与其玩那些从玩具商那买来的玩具礼物,为什么不设计并创造你自己的玩具来玩呢?
类还允许派生。你可以创建一个子类,它也是类,而且继续了父类所有的特征和属性。从Python 2. 2开始,你也可以从内建类型中派生子类,而不是仅仅从其他类。
13.3.1 创建类
Python类使用class关键字来创建。简单的类的声明可以是关键字后紧跟类名:

本章前面的概述中提到,基类是一个或多个用于继承的父类的集合;类体由所有声明语句,类成员定义,数据属性和函数组成。类通常在一个模块的顶层进行定义,以便类实例能够在类所定义的源代码文件中的任何地方被创建。
13.3.2 声明与定义
对于Python函数来说,声明与定义类没什么区别,因为他们是同时进行的,定义(类体)紧跟在声明(含class关键字的头行[header line])和可选(但总是推荐使用)的文档字符串后面。同时,所有的方法也必须同时被定义。如果对OOP很熟悉,请注意Python并不支持纯虚函数(像C++)或者抽象方法(如在Java中),这些都强制程序员在子类中定义方法。作为替代方法,你可以简单地在基类方法中引发NotImplementedError异常,这样可以获得类似的效果。
13.4 类属性
什么是属性呢?属性就是属于另一个对象的数据或者函数元素,可以通过我们熟悉的句点属性标识法来访问。一些Python类型比如复数有数据属性(实部和虚部),而另外一些,像列表和字典,拥有方法(函数属性)。
有关属性的一个有趣的地方是,当你正访问一个属性时,它同时也是一个对象,拥有它自己的属性,可以访问,这导致了一个属性链,比如,myThing、subThing、subSubThing。等。常见例子如下:

类属性仅与其被定义的类相绑定,并且因为实例对象在日常OOP中用得最多,实例数据属性是你将会一直用到的主要数据属性。类数据属性仅当需要有更加“静态”数据类型时才变得有用,它和任何实例都无关,因此,这也是为什么下一节被标为高级主题,你可以选读(如果你对静态不熟,它表示一个值,不会因为函数调用完毕而消失,它在每两个函数调用的间隙都存在。或者说,一个类中的一些数据对所有的实例来说,都是固定的。有关静态数据详细内容,见下一小节)。
接下来的一小节中,我们将简要描述,在Python中,方法是如何实现及调用的。通常,Python中的所有方法都有一个限制:在调用前,需要创建一个实例。
13.4.1 类的数据属性
数据属性仅仅是所定义的类的变量。它们可以像任何其他变量一样在类创建后被使用,并且,要么是由类中的方法来更新,要么是在主程序其他什么地方被更新。
这种属性已为OO程序员所熟悉,即静态变量,或者是静态数据。它们表示这些数据是与它们所属的类对象绑定的,不依赖于任何类实例。如果你是一位Java或C++程序员,这种类型的数据相当于在一个变量声明前加上static关键字。
静态成员通常仅用来跟踪与类相关的值。大多数情况下,你会考虑用实例属性,而不是类属性。在后面,我们正式介绍实例时,将会对类属性及实例属性进行比较。
看下面的例子,使用类数据属性(foo):

注意,上面的代码中,看不到任何类实例的引用。
13.4.2 Methods
1. 方法
方法,比如下面,类MyClass中的myNoActionMethod方法,仅仅是一个作为类定义一部分定义的函数(这使得方法成为类属性)。这表示myNoActionMethod仅应用在MyClass类型的对象(实例)上。这里,myNoActionMethod是通过句点属性标识法与它的实例绑定的。

任何像函数一样对myNoActionMethod自身的调用都将失败:

引发了NameError异常,因为在全局名字空间中,没有这样的函数存在。这就告诉你myNoActionMethod是一个方法,表示它属于一个类,而不是全局空间中的名字。如果myNoActionMethod是在顶层作为函数被定义的,那么我们的调用则会成功。
下面展示的是,甚至由类对象调用此方法也失败了。


TypeError异常看起来很让人困惑,因为你知道这种方法是类的一个属性,因此,一定很想知道为何为失败吧?接下来将会解释这个问题。
2. 绑定(绑定及非绑定方法)
为与OOP惯例保持一致,Python严格要求,没有实例,方法是不能被调用的。这种限制即Python所描述的绑定概念(binding),在此,方法必须绑定(到一个实例)才能直接被调用。非绑定的方法可能可以被调用,但实例对象一定要明确给出,才能确保调用成功。然而,不管是否绑定,方法都是它所在的类的固有属性,即使它们几乎总是通过实例来调用的。在13.7节中,我们会更深入地探索本主题。
13.4.3 决定类的属性
要知道一个类有哪些属性,有两种方法。最简单的是使用dir()内建函数。另外是通过访问类的字典属性__dict__,这是所有类都具备的特殊属性之一。看一下下面的例子:

根据上面定义的类,让我们使用dir()和特殊类属性__dict__来查看一下类的属性:

在新式类中,还新增加了一些属性,dir()也变得更健壮。作为比较,可以看下经典类是什么样的:

从上面可以看到,dir()返回的仅是对象的属性的一个名字列表,而__dict__返回的是一个字典,它的键(key)是属性名,键值(value)是相应的属性对象的数据值。
结果还显示了MyClass类中两个熟悉的属性,showMyVersion和myVersion,以及一些新的属性。这些属性,__doc__及__module__,是所有类都具备的特殊类属性(另外还有__dict__)。内建的vars()函数接受类对象作为参数,返回类的__dict__属性的内容。
13.4.4 特殊的类属性
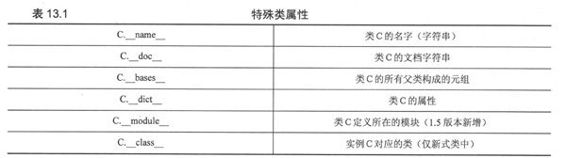
对任何类C,表13.1显示了类C的所有特殊属性:
根据上面定义的类MyClass,有如下结果:

__name__是给定类的字符名字。它适用于那种只需要字符串(类对象的名字),而非类对象本身的情况。甚至一些内建的类型也有这个属性,我们将会用到其中之一来展示__name__字符串的益处。
类型对象是一个内建类型的例子,它有__name__的属性。回忆一下,type()返回被调用对象的类型。这可能就是那种我们所说的仅需要一个字符串指明类型,而不需要一个对象的情况。我们能可以使用类型对象的__name__属性来取得相应的字符串名。如下例示:


__doc__是类的文档字符串,与函数及模块的文档字符串相似,必须紧随头行(header line)后的字符串。文档字符串不能被派生类继承,也就是说派生类必须含有它们自己的文档字符串。
本章后面会讲到,__bases__用来处理继承,它包含了一个由所有父类组成的元组。
前述的__dict__属性包含一个字典,由类的数据属性组成。访问一个类属性的时候,Python解释器将会搜索字典以得到需要的属性。如果在__dict__中没有找到,将会在基类的字典中进行搜索,采用“深度优先搜索”顺序。基类集的搜索是按顺序的,从左到右,按其在类定义时,定义父类参数时的顺序。对类的修改会仅影响到此类的字典;基类的__dict__属性不会被改动的。
Python支持模块间的类继承。为更清晰地对类进行描述,1.5版本中引入了__module__,这样类名就完全由模块名所限定。看一下下面的例子:

类C的全名是“__main__.C”,比如,source_module.class_name。如果类C位于一个导入的模块中,如mymod,像下面的:

在以前的版本中,没有特殊属性__module__,很难简单定位类的位置,因为类没有使用它们的全名。
最后,由于类型和类的统一性,当访问任何类的__class__属性时,你将发现它就是一个类型对象的实例。换句话说,一个类已是一种类型了。因为经典类并不认同这种等价性(一个经典类是一个类对象,一个类型是一个类型对象),对这些对象来说,这个属性并未定义。
13.5 实例
如果说类是一种数据结构定义类型,那么实例则声明了一个这种类型的变量。换言之,实例是有生命的类。就像设计完一张蓝图后,就是设法让它成为现实。实例是那些主要用在运行期时的对象,类被实例化得到实例,该实例的类型就是这个被实例化的类。在Python 2.2版本之前,实例是“实例类型”,而不考虑它从哪个类而来。
13.5.1 初始化:通过调用类对象来创建实例
很多其他的OO语言都提供new关键字,通过new可以创建类的实例。Python的方式更加简单。一旦定义了一个类,创建实例比调用一个函数还容易——不费吹灰之力。实例化的实现,可以使用函数操作符,如下示:

可以看到,仅调用“calling”类:MyClass(),就创建了类MyClass的实例mc。返回的对象是你所调用类的一个实例。当使用函数记法来调用“call”一个类时,解释器就会实例化该对象,并且调用Python所拥有与构造函数最相近的东西(如果你定义了的话)来执行最终的定制工作,比如设置实例属性,最后将这个实例返回给你。
 核心笔记:Python2.2前后的类和实例
核心笔记:Python2.2前后的类和实例
类和类型在2.2版本中就统一了,这使得Python的行为更像其他面向对象编程语言。任何类或者类型的实例都是这种类型的对象。比如,如果你让Python告诉你,类MyClass的实例mc是否是类MyClass的一个实例。回答是肯定的,Python不会说谎。同样,它会告诉你零是integer类型的一个实例:

但如果你仔细看,比较MyClass和int,你将会发现二者都是类型(type):

对比一下,如果在Python早于2.2版本时,使用经典类,此时类是类对象,实例是实例对象。在这两个对象类型之间没有任何关系,除了实例的__class__属性引用了被实例化以得到该实例的类。把MyClass在Python2.1版本中作为经典类重新定义,并运行相同的调用(注意:int()那时还不具备工厂功能……它还仅是一个通常的内建函数):

为了避免任何混淆,你只要记住当你定义一个类时,你并没有创建一个新的类型,而是仅仅一个类对象;而对2.2版本及后续版本,当你定义一个(新式的)类后,你已创建了一个新的类型。
13.5.2 __init__() “构造器”方法
当类被调用,实例化的第一步是创建实例对象。一旦对象创建了,Python检查是否实现了__init__()方法。默认情况下,如果没有定义(或覆盖)特殊方法__init__(),对实例不会施加任何特别的操作。任何所需的特定操作,都需要程序员实现__init__(),覆盖它的默认行为。如果__init__()没有实现,则返回它的对象,实例化过程完毕。
然而,如果__init__()已经被实现,那么它将被调用,实例对象作为第一个参数(self)被传递进去,像标准方法调用一样。调用类时,传进的任何参数都交给了__init__()。实际中,你可以想像成这样:把创建实例的调用当成是对构造器的调用。
总之,(a)你没有通过调用new来创建实例,你也没有定义一个构造器。是Python为你创建了对象;(b) __init__(),是在解释器为你创建一个实例后调用的第一个方法,在你开始使用它之前,这一步可以让你做些准备工作。
__init__()是很多为类定义的特殊方法之一。其中一些特殊方法是预定义的,缺省情况下,不进行任何操作,比如__init__(),要定制,就必须对它进行重载,还有些方法,可能要按需要去实现。本章中,我们会讲到很多这样的特殊方法。你将会经常看到__init__()的使用,在此,就不举例说明了。
13.5.3 __new__()“构造器”方法
与__init__()相比,__new__()方法更像一个真正的构造器。类型和类在版本2.2就统一了,Python用户可以对内建类型进行派生,因此,需要一种途径来实例化不可变对象,比如派生字符串、数字等。
在这种情况下,解释器则调用类的__new__()方法,一个静态方法,并且传入的参数是在类实例化操作时生成的。__new__()会调用父类的__new__()来创建对象(向上代理)。
为何我们认为__new__()比__init__()更像构造器呢?这是因为__new__()必须返回一个合法的实例,这样解释器在调用__init__()时,就可以把这个实例作为self传给它。调用父类的__new__()来创建对象,正像其他语言中使用new关键字一样。
__new__()和__init__()在类创建时,都传入了(相同)参数。13.11.3节中有个例子使用了__new__()。
13.5.4 __del__()“解构器”方法
同样,有一个相应的特殊解构器(destructor)方法名为__del__()。然而,由于Python具有垃圾对象回收机制(靠引用计数),这个函数要直到该实例对象所有的引用都被清除掉后才会执行。Python中的解构器是在实例释放前提供特殊处理功能的方法,它们通常没有被实现,因为实例很少被显式释放。
在下面的例子中,我们分别创建(并覆盖)__init__()和__del__()构造及解构函数,然后,初始化类并给同样的对象分配很多别名。id()内建函数可用来确定引用同一对象的三个别名。最后一步是使用del语句清除所有的别名,显示何时调用了多少次解构器。

注意,在上面的例子中,解构器是在类C实例所有的引用都被清除掉后,才被调用的,比如,当引用计数已减少到0。如果你预期你的__del__()方法会被调用,却实际上没有被调用,这意味着,你的实例对象由于某些原因,其引用计数不为0,这可能有别的对它的引用,而你并不知道这些让你的对象还活着的引用所在。
另外,要注意,解构器只能被调用一次,一旦引用计数为0,则对象就被清除了。这非常合理,因为系统中任何对象都只被分配及解构一次。
总结:
不要忘记首先调用父类的__del__()。
调用del x不表示调用了x.__del__()——前面也看到,它仅仅是减少x的引用计数。
如果你有一个循环引用或其他的原因,让一个实例的引用逗留不去,该对象的__del__()可能永远不会被执行。
__del__()未捕获的异常会被忽略掉(因为一些在__del__()用到的变量或许已经被删除了)。不要在__del__()中干与实例没任何关系的事情。
除非你知道你正在干什么,否则不要去实现__del__()。
如果你定义了__del__,并且实例是某个循环的一部分,垃圾回收器将不会终止这个循环——你需要自己显式调用del。
 核心笔记:跟踪实例
核心笔记:跟踪实例
Python没有提供任何内部机制来跟踪一个类有多少个实例被创建了,或者记录这些实例是些什么东西。如果需要这些功能,你可以显式加入一些代码到类定义或者__init__()和__del__()中去。最好的方式是使用一个静态成员来记录实例的个数。靠保存它们的引用来跟踪实例对象是很危险的,因为你必须合理管理这些引用,不然你的引用可能没办法释放(因为还有其他的引用)!看下面一个例子:

13.6 实例属性
实例仅拥有数据属性(方法严格来说是类属性),后者只是与某个类的实例相关联的数据值,并且可以通过句点属性标识法来访问。这些值独立于其他实例或类。当一个实例被释放后,它的属性同时也被清除了。
13.6.1 “实例化”实例属性(或创建一个更好的构造器)
设置实例的属性可以在实例创建后任意时间进行,也可以在能够访问实例的代码中进行。构造器__init__()是设置这些属性的关键点之一。
 核心笔记:实例属性
核心笔记:实例属性
能够在“运行时”创建实例属性,是Python类的优秀特性之一,从C++或Java转过来的人会被小小地震惊一下,因为C++或Java中所有属性在使用前都必须明确定义/声明。Python不仅是动态类型,而且在运行时,允许这些对象属性的动态创建。这种特性让人爱不释手。当然,我们必须提醒读者,创建这样的属性时,必须谨慎。一个缺陷是,属性在条件语句中创建,如果该条件语句块并未被执行,属性也就不存在,而你在后面的代码中试着去访问这些属性,就会有错误发生。故事的精髓是告诉我们,Python让你体验从未用过的特性,但如果你使用它了,你还是要小心为好。
1. 在构造器中首先设置实例属性
构造器是最早可以设置实例属性的地方,因为__init__()是实例创建后第一个被调用的方法。再没有比这更早的可以设置实例属性的机会了。一旦__init__()执行完毕,返回实例对象,即完成了实例化过程。
2. 默认参数提供默认的实例安装
在实际应用中,带默认参数的__init__()提供一个有效的方式来初始化实例。在很多情况下,默认值表示设置实例属性的最常见的情况,如果提供了默认值,我们就没必要显式给构造器传值了。我们在11.5.2节中也提到默认参数的常见好处。需要明白一点,默认参数应当是不变的对象;像列表(list)和字典(dictionary)这样的可变对象可以扮演静态数据,然后在每个方法调用中来维护它们的内容。
例13.1描述了如何使用默认构造器行为来帮助我们计算在美国一些大都市中的旅馆中寄宿时,租房总费用。
代码的主要目的是来帮助某人计算出每日旅馆租房费用,包括所有州销售税和房税。缺省为旧金山附近的普通区域,它有8.5%销售税及10%的房间税。每日租房费用没有缺省值,因此在任何实例被创建时,都需要这个参数。
例13.1 使用缺省参数进行实例化
定义一个类来计算这个假想旅馆租房费用。__init__()构造器对一些实例属性进行初始化。calcTotal()方法用来决定是计算每日总的租房费用还是计算全部的租房费。


设置工作是由__init__()在实例化之后完成的,如上面的第4~8行,其余部分的核心代码是calcTotal()方法,从第10~14行。__init__()的工作即是设置一些参数值来决定旅馆总的基本租房费用(不包括住房服务,电话费,或其他偶发事情)。calcTotal()可以计算每日所有费用,如果提供了天数,那么将计算整个旅程全部的住宿费用。内建的round()函数可以大约计算出最接近的费用(两个小数位)。下面是这个类的用法:

最开始的两个假想例子都是在旧金山,使用了默认值,然后是在西雅图,这里我们提供了不同的销售税和房间税率。最后一个例子在华盛顿特区。经过计算更长的假想时间,来扩展通常的用法:停留5个工作日,外加一个周六,此时有特价,假定是星期天出发回家。
不要忘记,函数所有的灵活性,比如默认参数,也可以应用到方法中去。在实例化时,可变长度参数也是一个好的特性(当然,这要根据应用的需要)。
3. __init__()应当返回None
你也知道,采用函数操作符调用类对象会创建一个类实例,也就是说这样一种调用过程返回的对象就是实例,下面示例可以看出:

如果定义了构造器,它不应当返回任何对象,因为实例对象是自动在实例化调用后返回的。相应地,__init__()就不应当返回任何对象(应当为None);否则,就可能出现冲突,因为只能返回实例。试着返回非None的任何其他对象都会导致TypeError异常:

13.6.2 查看实例属性
内建函数dir()可以显示类属性,同样还可以打印所有实例属性:

与类相似,实例也有一个__dict__特殊属性(可以调用varsO并传入一个实例来获取),它是实例属性构成的一个字典:

13.6.3 特殊的实例属性
实例仅有两个特殊属性(见表13.2)。对于任意对象I:

现在使用类C及其实例C来看看这些特殊实例属性:

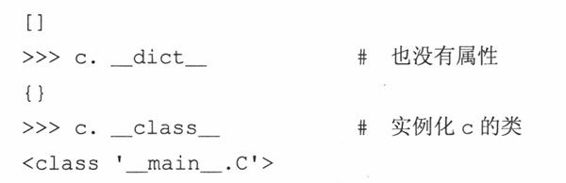
你可以看到,c现在还没有数据属性,但我们可以添加一些再来检查__dict__属性,看是否添加成功了:

__dict__属性由一个字典组成,包含一个实例的所有属性。键是属性名,值是属性相应的数据值。字典中仅有实例属性,没有类属性或特殊属性。
 核心风格:修改__dict__
核心风格:修改__dict__
对类和实例来说,尽管__dict__属性是可修改的,但还是建议你不要修改这些字典,除非你知道你在干什么。这些修改可能会破坏你的OOP,造成不可预料的副作用。使用熟悉的句点属性标识来访问及操作属性会更易于接受。需要你直接修改__dict__属性的情况很少,其中之一是你要重载__setattr__特殊方法。实现__setattr__()本身是一个冒险的经历,满是圈套和陷阱,例如无穷递归和破坏实例对象。这个故事还是留到下次说吧。
13.6.4 建类型属性
内建类型也是类,它们有没有像类一样的属性呢?那实例有没有呢?对内建类型也可以使用dir(),与任何其他对象一样,可以得到一个包含它属性名字的列表:

既然我们知道了一个复数有什么样的属性,我们就可以访问它的数据属性,调用它的方法了:

试着访问__dict__会失败,因为在内建类型中,不存在这个属性:

13.6.5 实例属性vs类属性
我们已在13.4.1节中描述了类数据属性。这里简要提一下,类属性仅是与类相关的数据值,和实例属性不同,类属性和实例无关。这些值像静态成员那样被引用,即使在多次实例化中调用类,它们的值都保持不变。不管如何,静态成员不会因为实例而改变它们的值,除非实例中显式改变它们的值(实例属性与类属性的比较,类似于自动变量和静态变量,但这只是笼统的类推。在你对自动变量和静态变量还不是很熟的情况下,不要深究这些)。
类和实例都是名字空间。类是类属性的名字空间,实例则是实例属性的。
关于类属性和实例属性,还有一些方面需要指出。你可采用类来访问类属性,如果实例没有同名的属性的话,你也可以用实例来访问。
1. 访问类属性
类属性可通过类或实例来访问。下面的示例中,类C在创建时,带一个version属性,这样通过类对象来访问它是很自然的了,比如C.version。当实例c被创建后,对实例c而言,访问c.version会失败,不过Python首先会在实例中搜索名字version,然后是类,再就是继承树中的基类。本例中,version在类中被找到了:

然而,我们只有当使用类引用version时,才能更新它的值,像上面的C.version递增语句。如果尝试在实例中设定或更新类属性会创建一个实例属性c.version,后者会阻止对类属性C.versioin的访问,因为第一个访问的就是c.version,这样可以对实例有效地“遮蔽”类属性C.version,直到c.version被清除掉。
2. 从实例中访问类属性须谨慎
与通常Python变量一样,任何对实例属性的赋值都会创建一个实例属性(如果不存在的话)并且对其赋值。如果类属性中存在同名的属性,有趣的副作用即产生(经典类和新式类都存在)。

在上面的代码片段中,创建了一个名为version的新实例属性,它覆盖了对类属性的引用。然而,类属性本身并没有受到伤害,仍然存在于类域中,还可以通过类属性来访问它,如上例可以看到的。好了,那么如果把这个新的version删除掉,会怎么样呢?为了找到结论,我们将使用del语句删除c.version。

所以,给一个与类属性同名的实例属性赋值,我们会有效地“隐藏”类属性,但一旦我们删除了这个实例属性,类属性又重见天日。现在再来试着更新类属性,但这次,我们只尝试一下“无辜”的增量动作:

还是没变。我们同样创建了一个新的实例属性,类属性原封不动(深入理解Python相关知识:属性已存于类字典[__dict__]中。通过赋值,其被加入到实例的__dict__中了)。赋值语句右边的表达式计算出原类的变量,增加0.2,并且把这个值赋给新创建的实例属性。注意下面是一个等价的赋值方式,但它可能更加清楚些:

但……在类属性可变的情况下,一切都不同了:


3. 类属性持久性
静态成员,顾名思义,任凭整个实例(及其属性)的如何进展,它都不理不睬(因此独立于实例)。同时,当一个实例在类属性被修改后才创建,那么更新的值就将生效。类属性的修改会影响到所有的实例:

 核心提示:使用类属性来修改自身(不是实例属性)
核心提示:使用类属性来修改自身(不是实例属性)
正如上面所看到的那样,使用实例属性来试着修改类属性是很危险的。原因在于实例拥有它们自已的属性集,在Python中没有明确的方法来指示你想要修改同名的类属性,比如,没有global关键字可以用来在一个函数中设置一个全局变量(来代替同名的局部变量)。修改类属性需要使用类名,而不是实例名。
13.7 绑定和方法调用
现在我们需要再次阐述Python中绑定(binding)的概念,它主要与方法调用相关连。我们先来回顾一下与方法相关的知识。首先,方法仅仅是类内部定义的函数(这意味着方法是类属性而不是实例属性)。
其次,方法只有在其所属的类拥有实例时,才能被调用。当存在一个实例时,方法才被认为是绑定到那个实例了。没有实例时方法就是未绑定的。
最后,任何一个方法定义中的第一个参数都是变量self,它表示调用此方法的实例对象。
 核心笔记:self是什么?
核心笔记:self是什么?
self变量用于在类实例方法中引用方法所绑定的实例。因为方法的实例在任何方法调用中总是作为第一个参数传递的,self被选中用来代表实例。你必须在方法声明中放上self(你可能已经注意到了这点),但可以在方法中不使用实例(self)。如果你的方法中没有�用到self,那么请考虑创建一个常规函数,除非你有特别的原因。毕竟,你的方法代码没有使用实例,没有与类关联其功能,这使得它看起来更像一个常规函数。在其他面向对象语言中,self可能被称为this。
13.7.1 调用绑定方法
方法,不管绑定与否,都是由相同的代码组成的。唯一的不同在于是否存在一个实例可以调用此方法。在很多情况下,程序员调用的都是一个绑定的方法。假定现在有一个MyClass类和此类的一个实例mc,而你想调用MyClass.foo()方法。因为已经有一个实例,你只需要调用mc.foo()就可以。记得self在每一个方法声明中都是作为第一个参数传递的。当你在实例中调用一个绑定的方法时,self不需要明确地传入了。这算是“必须声明self作为第一个参数”对你的报酬。当你还没有一个实例并且需要调用一个非绑定方法的时候你必须传递self参数。
13.7.2 调用非绑定方法
调用非绑定方法并不经常用到。需要调用一个还没有任何实例的类中的方法的一个主要的场景是:你在派生一个子类,而且你要覆盖父类的方法,这时你需要调用那个父类中想要覆盖掉的构造方法。这里是一个本章前面介绍过的例子:

EmplAddrBookEntry是AddrBookEntry的子类,我们重载了构造器__init__()。我们想尽可能多地重用代码,而不是去从父类构造器中剪切,粘贴代码。这样做还可以避免bug传播,因为任何修复都可以传递给子类。这正是我们想要的——没有必要一行一行地复制代码。只需要能够调用父类的构造器即可,但该怎么做呢?
我们在运行时没有AddrBookEntry的实例。那么我们有什么呢?我们有一个EmplAddrBookEntry的实例,它与AddrBookEntry是那样地相似,我们难道不能用它代替呢?当然可以!
当一个EmplAddrBookEntry被实例化,并且调用__init__()时,其与AddrBookEntry的实例只有很少的差别,主要是因为我们还没有机会来自定义我们的EmplAddrBookEntry实例,以使它与AddrBookEntry不同。
这是调用非绑定方法的最佳地方了。我们将在子类构造器中调用父类的构造器并且明确地传递(父类)构造器所需要的self参数(因为我们没有一个父类的实例)。子类中__init__()的第一行就是对父类__init__()的调用。我们通过父类名来调用它,并且传递给它self和其他所需要的参数。一旦调用返回,我们就能定义那些与父类不同的仅存在我们的(子)类中的(实例)定制。
13.8 静态方法和类方法
静态方法和类方法在Python 2.2中被引入。经典类及新式(new-style)类中都可以使用它。一对内建函数被引入,用于将作为类定义的一部分的某一方法声明“标记”(tag), “强制类型转换”(cast)或者”转换”(convert)为这两种类型的方法之一。
如果你有一定的C++或者Java经验,静态方法和这些语言中的是一样的。它们仅是类中的函数(不需要实例)。事实上,在静态方法加入到Python之前,用户只能在全局名字空间中创建函数,作为这种特性的替代实现——有时在这样的函数中使用类对象来操作类(或者是类属性)。使用模块函数比使用静态类方法更加常见。
回忆一下,通常的方法需要一个实例(self)作为第一个参数,并且对于(绑定的)方法调用来说,self是自动传递给这个方法的。而对于类方法而言,需要类而不是实例作为第一个参数,它是由解释器传给方法。类不需要特别地命名,类似self,不过很多人使用cls作为变量名字。
13.8.1 staticmethod()和classmethod()内建函数
现在让我们看一下在经典类中创建静态方法和类方法的一些例子(你也可以把它们用在新式类中):

对应的内建函数被转换成它们相应的类型,并且重新赋值给了相同的变量名。如果没有调用这两个函数,二者都会在Python编译器中产生错误,显示需要带self的常规方法声明。现在,我们可以通过类或者实例调用这些函数,这没什么不同:

13.8.2 使用函数修饰符
现在,看到像foo=staticmethod(foo)这样的代码会刺激一些程序员。很多人对这样一个没意义的语法感到心烦,即使van Rossum曾指出过,它只是临时的,有待社区对些语义进行处理。在第11章的11.3.6节中,我们了解了函数修饰符,一种在Python2.4中加入的新特征。你可以用它把一个函数应用到另个函数对象上,而且新函数对象依然绑定在原来的变量。我们正是需要它来整理语法。通过使用解构器,我们可以避免像上面那样的重新赋值:

13.9 组合
一个类被定义后,目标就是要把它当成一个模块来使用,并把这些对象嵌入到你的代码中去,同其他数据类型及逻辑执行流混合使用。有两种方法可以在你的代码中利用类。第一种是组合(composition)。就是让不同的类混合并加入到其他类中,来增加功能和代码重用性。你可以在一个大点的类中创建你自己的类的实例,实现一些其他属性和方法来增强对原来的类对象。另一种方法是通过派生,我们将在下一节中讨论它。
举例来说,让我们想象一个对本章一开始创建的地址本类的加强性设计。如果在设计的过程中,为names、addresses等创建了单独的类,那么最后我们可能想把这些工作集成到AddrBookEntry类中去,而不是重新设计每一个需要的类。这样就节省了时间和精力,而且最后的结果是容易维护的代码——一块代码中的bug被修正,将反映到整个应用中。
这样的类可能包含一个Name实例,以及其他如StreetAddress、Phone (home、work、telefacsimile、pager、mobile等)、Email (home、work等),还可能需要一些Date实例(birthday、wedding、anniversary等)。下面是一个简单的例子:

NewAddrBookEntry类由它自身和其他类组合而成。这就在一个类和其他组成类之间定义了一种“有一个”(has-a)的关系。比如,我们的NewAddrBookEntry类“有一个” Name类实例和一个Phone实例。
创建复合对象就可以实现这些附加的功能,并且很有意义,因为这些类都不相同。每一个类管理它们自己的名字空间和行为。不过当对象之间有更接近的关系时,派生的概念可能对你的应用程序来说更有意义,特别是当你需要一些相似的对象,但却有少许不同功能的时候。
13.10 子类和派生
当类之间有显著的不同,并且(较小的类)是较大的类所需要的组件时,组合表现得很好,但当你设计“相同的类但有一些不同的功能”时,派生就是一个更加合理的选择了。
OOP的更强大功能之一是能够使用一个已经定义好的类,扩展它或者对其进行修改,而不会影响系统中使用现存类的其他代码片段。OOD允许类特征在子孙类或子类中进行继承。这些子类从基类(或称祖先类、超类)继承它们的核心属性。而且,这些派生可能会扩展到多代。在一个层次的派生关系中的相关类(或者是在类树图中垂直相邻)是父类和子类关系。从同一个父类派生出来的这些类(或者是在类树图中水平相邻)是同胞关系。父类和所有高层类都被认为是祖先。
使用前一节中的例子,如果我们必须创建不同类型的地址本,即不仅仅是创建地址本的多个实例,在这种情况下,所有对象几乎是相同的。如果我们希望EmplAddrBookEntry类中包含更多与工作有关的属性,如员工ID和电子邮件地址呢?这跟PersonalAddrBookEntry类不同,它包含更多基于家庭的信息,比如家庭地址、关系、生日等。
两种情况下,我们都不想到从头开始设计这些类,因为这样做会重复创建通用的AddressBook类时的操作。包含AddressBook类所有的特征和特性并加入需要的定制特性不是很好吗?这就是类派生的动机和要求。
创建子类
创建子类的语法看起来与普通(新式)类没有区别,一个类名,后跟一个或多个需要从其中派生的父类:

如果你的类没有从任何祖先类派生,可以使用object作为父类的名字。经典类的声明唯一不同之处在于其没有从祖先类派生——此时,没有圆括号:

至此,我们已经看到了一些类和子类的例子,下面还有一个简单的例子:


13.11 继承
继承描述了基类的属性如何“遗传”给派生类。一个子类可以继承它的基类的任何属性,不管是数据属性还是方法。
举个例子如下。P是一个没有属性的简单类。C从P继承而来(因此是它的子类),也没有属性:

因为P没有属性,C没有继承到什么。下面我们给P添加一些属性:

现在所创建的P有文档字符串(__doc__)和构造器,当我们实例化P时它被执行,如下面的交互会话所示:

“created an instance”是由__init__()直接输出的。我们也可显示更多关于父类的信息。我们现在来实例化C,展示__init__()(构造)方法在执行过程中是如何继承的:


C没有声明__init__()方法,然而在类C的实例c被创建时,还是会有输出信息。原因在于C继承了P的__init__()。__bases__元组列出了其父类P。需要注意的是文档字符串对类,函数/方法,还有模块来说都是唯一的,所以特殊属性__doc__不会从基类中继承过来。
13.11.1 __bases\_类属性
在第13.4.4节中,我们概要地介绍了__bases__类属性,对任何(子)类,它是一个包含其父类(parent)的集合的元组。注意,我们明确指出“父类”是相对所有基类(它包括了所有祖先类)而言的。那些没有父类的类,它们的__bases__属性为空。下面我们看一下如何使用__bases__的。

在上面的例子中,尽管C是A和B的子类(通过B传递继承关系),但C的父类是B,这从它的声明中可以看出,所以,只有B会在C.__bases__中显示出来。另一方面,D是从两个类A和B中继承而来的(多重继承参见13.11.4节)。
13.11.2 通过继承覆盖方法
我们在P中再写一个函数,然后在其子类中对它进行覆盖。

现在来创建子类C,从父类P派生:

尽管C继承了P的foo()方法,但因为C定义了它自己的foo()方法,所以P中的foo()方法被覆盖(Overrid)。覆盖方法的原因之一是,你的子类可能需要这个方法具有特定或不同的功能。所以,你接下来的问题肯定是:“我还能否调用那个被我覆盖的基类方法呢?”
答案是肯定的,但是这时就需要你去调用一个未绑定的基类方法,明确给出子类的实例,例如下边:

注意,我们上面已经有了一个P的实例p,但上面的这个例子并没有用它。我们不需要P的实例调用P的方法,因为已经有一个P的子类的实例c可用。典型情况下,你不会以这种方式调用父类方法,你会在子类的重写方法里显式地调用基类方法。

注意,在这个(未绑定)方法调用中我们显式地传递了self。一个更好的办法是使用super()内建方法:

super()不但能找到基类方法,而且还为我们传进self,这样我们就不需要做这些事了。现在我们只要调用子类的方法,它会帮你完成一切:

 核心笔记:重写__init不会自动调用基类的init__
核心笔记:重写__init不会自动调用基类的init__
类似于上面的覆盖非特殊方法,当从一个带构造器__init__()的类派生,如果你不去覆盖__init__(),它将会被继承并自动调用。但如果你在子类中覆盖了__init__(),子类被实例化时,基类的__init__()就不会被自动调用。这可能会让了解Java的朋友感到吃惊。

如果你还想调用基类的__init__(),你需要像上边我们刚说的那样,明确指出,使用一个子类的实例去调用基类(未绑定)方法。相应地更新类C,会出现下面预期的执行结果:

上边的例子中,子类的__init__()方法首先调用了基类的__init__()方法。这是相当普遍(不是强制)的做法,用来设置初始化基类,然后可以执行子类内部的设置。这个规则之所以有意义的原因是,你希望被继承的类的对象在子类构造器运行前能够很好地被初始化或作好准备工作,因为它(子类)可能需要或设置继承属性。对C++熟悉的朋友,可能会在派生类构造器声明时,通过在声明后面加上冒号和所要调用的所有基类构造器这种形式来调用基类构造器。而在Java中,不管程序员如何处理,子类构造器都会去调用基类的构造器。
Python使用基类名来调用类方法,对应在Java中,是用关键字super来实现的,这就是super()内建函数引入到Python中的原因,这样你就可以“依葫芦画瓢”了:

使用super()的漂亮之处在于,你不需要明确给出任何基类名字……“跑腿儿”的事,它帮你干了!使用super()的重点,使你不需要明确提供父类。这意味着如果你改变了类继承关系,你只需要改一行代码(class语句本身)而不必在大量代码中去查找所有被修改的那个类的名字。
13.11.3 从标准类型派生
经典类中,一个最大的问题是,不能对标准类型进行子类化。幸运的是,在2.2以后的版本中,随着类型(types)和类(class)的统一和新式类的引入,这一点已经被修正。下面,介绍两个子类化Python类型的相关例子,其中一个是可变类型,另一个是不可变类型。
1. 不可变类型的例子
假定你想在金融应用中,应用一个处理浮点型的子类。每次你得到一个贷币值(浮点型给出的),你都需要通过四舍五入,变为带两位小数位的数值。(当然,Decimal类比起标准浮点类型来说是个用来精确保存浮点值的更佳方案,但你还是需要[有时候]对其进行舍入操作!)你的类开始可以这样写:

我们覆盖了__new__()特殊方法来定制我们的对象,使之和标准Python浮点型(float)有一些区别:我们使用round()内建函数对原浮点型进行舍入操作,然后实例化我们的float, RoundFloat。我们是通过调用父类的构造器来创建真实的对象的,float__new__()。注意,所有的__new__()方法都是类方法,我们要显式地传入类作为第一个参数,这类似于常见的方法如__init__()中需要的self。
现在的例子还非常简单,比如,我们知道有一个float,我们仅仅是从一种类型中派生而来等。通常情况下,最好是使用super()内建函数去捕获对应的父类以调用它的__new__()方法,下面,对它进行这方面的修改:

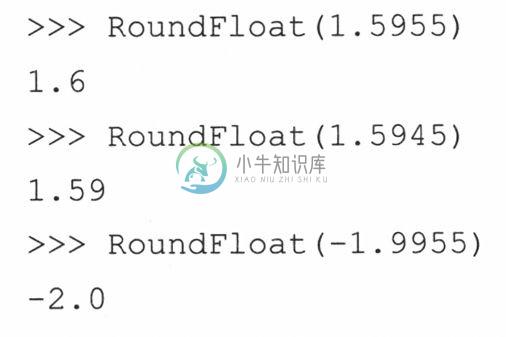
这个例子还远不够完整,所以,请留意本章我们将使它有更好的表现。下面是一些样例输出:
2. 可变类型的例子
子类化一个可变类型与此类似,你可能不需要使用__new__()(或甚至__init__()),因为通常设置不多。一般情况下,你所继承到的类型的默认行为就是你想要的。下例中,我们简单地创建一个新的字典类型,它的keys()方法会自动排序结果:

回忆一下,字典(dictionary)可以由dict()、dict(mapping)、dict(sequence_of_2__tuples)或dict(**kwargs)来创建,看看下面使用新类的例子:

把上面的代码全部加到一个脚本中,然后运行,可以得到下面的输出:

在上例中,通过keys迭代过程是以散列顺序的形式,而使用我们(重写的)keys()方法则将keys变为字母排序方式了。
一定要谨慎,而且要意识到你正在干什么。如果你说“你的方法调用super()过于复杂”,取而代之的是,你更喜欢keys()简简单单(也容易理解),如下所示:

这是本章后面的练习13-19。
13.11.4 多重继承
同C++一样,Python允许子类继承多个基类。这种特性就是通常所说的多重继承。概念容易,但最难的工作是,如何正确找到没有在当前(子)类定义的属性。当使用多重继承时,有两个不同的方面要记住。首先,还是要找到合适的属性。另一个就是当你重写方法时,如何调用对应父类方法以“发挥他们的作用”,同时,在子类中处理好自己的义务。我们将讨论两个方面,但侧重后者,讨论方法解析顺序。
1. 方法解释顺序(MRO)
在Python 2.2以前的版本中,算法非常简单:深度优先,从左至右进行搜索,取得在子类中使用的属性。其他Python算法只是覆盖被找到的名字,多重继承则取找到的第一个名字。
由于类,类型和内建类型的子类,都经过全新改造,有了新的结构,这种算法不再可行。这样一种新的MRO (Method Resolution Order)算法被开发出来,在2.2版本中初次登场,是一个好的尝试,但有一个缺陷(看下面的核心笔记)。这在2.3版本中立即被修改,也就是今天还在使用的版本。
精确顺序解释很复杂,超出了本文的范畴,但你可以去阅读本节后面的参考书目提到的有关内容。这里提一下,新的查询方法是采用广度优先,而不是深度优先。
 核心笔记:Python 2.2使用一种唯一但不完善的MRO
核心笔记:Python 2.2使用一种唯一但不完善的MRO
Python 2.2是首个使用新式MRO的版本,它必须取代经典类中的算法,原因在上面已谈到过。在2.2版本中,算法基本思想是根据每个祖先类的继承结构,编译出一张列表,包括搜索到的类,按策略删除重复的。然而,在Python核心开发人员邮件列表中,有人指出,在维护单调性方面失败过(顺序保存),必须使用新的C3算法替换,也就是从2.3版开始使用的新算法。
下面的示例,展示经典类和新式类中,方法解释顺序有什么不同。
2. 简单属性查找示例
下面这个例子将对两种类的方案不同处做一展示。脚本由一组父类,一组子类,还有一个子孙类组成。


在图13-2中,我们看到父类、子类及子孙类的关系。P1中定义了foo(), P2定义了foo()和bar(),C2定义了bar()。下面举例说明一下经典类和新式类的行为。
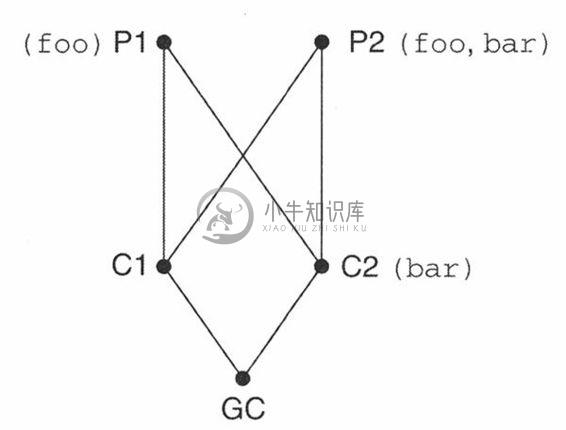
图 13-2 父类,子类及子孙类的关系图,还有它们各自定义的方法
(1)经典类
首先来使用经典类。通过在交互式解释器中执行上面的声明,我们可以验证经典类使用的解释顺序,深度优先,从左至右:

当调用foo()时,它首先在当前类(GC)中查找。如果没找到,就向上查找最亲的父类,C1。查找未遂,就继续沿树上访到父类P1,foo()被找到。
同样,对bar()来说,它通过搜索GC, C1, P1然后在P2中找到。因为使用这种解释顺序的缘故,C2.bar()根本就不会被搜索了。
现在,你可能在想,“我更愿意调用C2的bar()方法,因为它在继承树上和我更亲近些,这样才会更合适”。在这种情况下,你当然还可以使用它,但你必须调用它的合法的全名,采用典型的非绑定方式去调用,并且提供一个合法的实例:

(2)新式类
取消类P1和类P2声明中的对(object)的注释,重新执行一下。新式方法的查询有一些不同:

与沿着继承树一步一步上溯不同,它首先查找同胞兄弟,采用一种广度优先的方式。当查找foo(),它检查GC,然后是C1和C2,然后在P1中找到。如果P1中没有,查找将会到达P2。foo()的底线是,包括经典类和新式类都会在P1中找到它,然而它们虽然是同归,但殊途!
然而,bar()的结果是不同的。它搜索GC和C1,紧接着在C2中找到了。这样,就不会再继续搜索到祖父P1和P2。这种情况下,新的解释方式更适合那种要求查找GC更亲近的bar()的方案。当然,如果你还需要调用上一级,只要按前述方法,使用非绑定的方式去做,即可。

新式类也有一个__mro__属性,告诉你查找顺序是怎样的:

3. *菱形效应引起MRO问题
经典类方法解释不会带来很多问题。它很容易解释,并理解。大部分类都是单继承的,多重继承只限用在对两个完全不相关的类进行联合。这就是术语mixin类(或者“mix-ins”)的由来。
为什么经典类MRO会失败
在版本2.2中,类型与类的统一,带来了一个新的“问题”,波及所有从object(所有类型的祖先类)派生出来的(根)类,一个简单的继承结构变成了一个菱形。从Guido van Rossum的文章中得到下面的灵感,打个比方,你有经典类B和C, C覆盖了构造器,B没有,D从B和C继承而来:

当我们实例化D,得到:

图13-3为B, C和D的类继承结构,现在把代码改为采用新式类的方式,问题也就产生了:
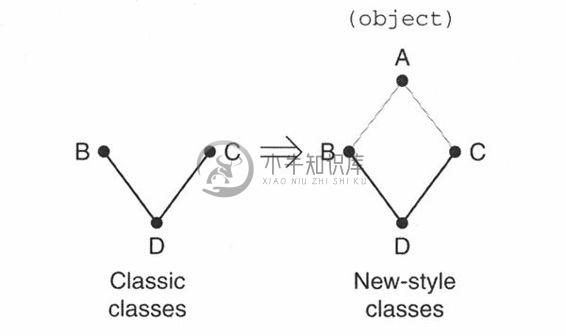
图 13-3 继承的问题是由于在新式类中,需要出现基类,这样就在继承结构中,形成了一个菱形。D的实例上溯时,不应当错过C,但不能两次上溯到A(因为B和C都从A派生)。去读读贵铎·范·罗萨姆的文章中有关“协作方法”的部分,可以得到更深地理解。

代码中仅仅是在两个类声明中加入了(object),对吗?没错,但从图中,你可以看出,继承结构已变成了一个菱形;真正的问题就存在于MRO了。如果我们使用经典类的MRO,当实例化D时,不再得到C.__init__()之结果…..而是得到object.__init__()!这就是为什么MRO需要修改的真正原因。
尽管我们看到了,在上面的例子中,类GC的属性查找路径被改变了,但你不需要担心会有大量的代码崩溃。经典类将沿用老式MRO,而新式类将使用它自己的MRO。还有,如果你不需要用到新式类中的所有特性,可以继续使用经典类进行开发,不会有问题的。
4. 总结
经典类,使用深度优先算法。因为新式类继承自object,新的菱形类继承结构出现,问题也就接着而来了,所以必须新建一个MRO。
你可以在下面的链接中读在更多有关新式类、MRO的文章。
Guido van Rossum有关类型和类统一的文章:
http://www.python.org/download/releases/2.2.3/descrintro
PEP 252:使类型看起来更像类
http://www.python.org/doc/peps/pep-0252
“Python 2.2新亮点”文档
http://www.python.org/doc/2.2.3/whatsnew
论文:Python 2.3方法解释顺序
http://python.org/download/releases/2.3/mro/
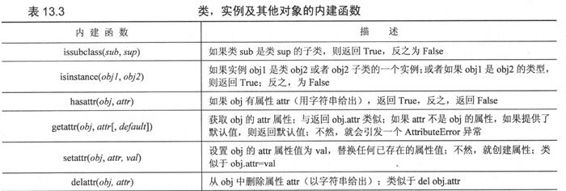
13.12 类、实例和其他对象的内建函数
13.12.1 issubclass()
issubclass()布尔函数判断一个类是另一个类的子类或子孙类。它有如下语法:
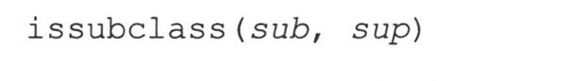
issubclass()返回True的情况:给出的子类sub确实是父类sup的一个子类(反之,则为False)。这个函数也允许“不严格”的子类,意味着,一个类可视为其自身的子类,所以,这个函数如果当sub就是sup,或者从sup派生而来,则返回True(一个“严格的”子类是严格意义上的从一个类派生而来的子类)。
从Python 2.3开始,issubclass()的第二个参数可以是可能的父类组成的元组(tuple),这时,只要第一个参数是给定元组中任何一个候选类的子类时,就会返回True。
13.12.2 isinstance()
isinstance()布尔函数在判定一个对象是否是另一个给定类的实例时,非常有用。它有如下语法:
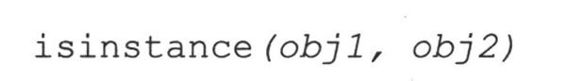
isinstance()在obj1是类obj2的一个实例,或者是obj2的子类的一个实例时,返回True(反之,则为False),看下面的例子:

注意:第二个参数应当是类;不然,你会得到一个TypeError。但如果第二个参数是一个类型对象,则不会出现异常。这是允许的,因为你也可以使用isinstance()来检查一个对象obj1是否是obj2的类型,比如:

如果你对Java有一定的了解,那么你可能知道Java中有个等价函数叫instanceof(),但由于性能上的原因,instanceof()并不推荐使用。调用Python的isinstance()不会有性能上的问题,主要是因为它只用来快速搜索类族集成结构,以确定调用者是哪个类的实例,还有更重要的是,它是用C写的!
同issubclass()一样,isinstance()也可以使用一个元组作为第二个参数。这个特性是从Python 2.2版本中引进的。如果第一个参数是第二个参数中给定元组的任何一个候选类型或类的实例时,就会返回True。你还可以在第13.16.1节中了解到更多有isinstance()的内容。
13.12.3 hasattr()、getattr()、setattr()、delattr()
*attr()系列函数可以在各种对象下工作,不限于类(class)和实例(instances)。然而,因为在类和实例中使用极其频繁,就在这里列出来了。需要说明的是,当使用这些函数时,你传入你正在处理的对象作为第一个参数,但属性名,也就是这些函数的第二个参数,是这些属性的字符串名字。换句话说,在操作obj.attr时,就相当于调用*attr(obj,‘attr’…)系列函数——下面的例子讲得很清楚。
hasattr()函数是布朗型的,它的目的就是为了决定一个对象是否有一个特定的属性,一般用于访问某属性前先作一下检查。getattr()和setattr()函数相应地取得和赋值给对象的属性,getattr()会在你试图读取一个不存在的属性时,引发AttributeError异常,除非给出那个可选的默认参数。setattr()将要么加入一个新的属性,要么取代一个已存在的属性。而delattr()函数会从一个对象中删除属性。
下面一些例子使用到了*attr()系列内建函数:


13.12.4 dir()
前面用到dir()是在练习2-12、练习2-13和练习4-7。在这些练习中,我们用dir()列出一个模块所有属性的信息。现在你应该知道dir()还可以用在对象上。
在Python 2.2中,dir()得到了重要的更新。因为这些改变,那些__members和methods__数据属性已经被宣告即将不支持。dir()提供的信息比以前更加详尽。根据文档,“除了实例变量名和常用方法外,它还显示那些通过特殊标记来调用的方法,像__iadd__(+=),__len__(len()),__ne__(!=)”。在Python文档中有详细说明。
dir()作用在实例上(经典类或新式类)时,显示实例变量,还有在实例所在的类及所有它的基类中定义的方法和类属性。
dir()作用在类上(经典类或新式类)时,则显示类以及它的所有基类的__dict__中的内容。但它不会显示定义在元类(metaclass)中的类属性。
dir()作用在模块上时,则显示模块的__dict__的内容。(这没改动)。
dir()不带参数时,则显示调用者的局部变量。(也没改动)。关于更多细节:对于那些覆盖了__dict或__class\_属性的对象,就使用它们;出于向后兼容的考虑,如果已定义了__members和methods__,则使用它们。
13.12.5 super()
super()函数在Python2.2版本新式类中引入。这个函数的目的就是帮助程序员找出相应的父类,然后方便调用相关的属性。一般情况下,程序员可能仅仅采用非绑定方式调用祖先类方法。使用super()可以简化搜索一个合适祖先的任务,并且在调用它时,替你传入实例或类型对象。
在第13.11.4节中,我们描述了方法解释顺序(MRO),用于在祖先类中查找属性。对于每个定义的类,都有一个名为__mro__的属性,它是一个元组,按照他们被搜索时的顺序,列出了备搜索的类。语法如下:
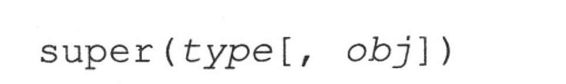
给出type,super()“返回此type的父类”。如果你希望父类被绑定,你可以传入obj参数(obj必须是type类型的)。否则父类不会被绑定。obj参数也可以是一个类型,但它应当是type的一个子类。通常,当给出obj时:
如果obj是一个实例,isinstance (obj,type)就必须返回True
如果obj是一个类或类型,issubclass (obj,type)就必须返回True
事实上,super()是一个工厂函数,它创造了一个super object,为一个给定的类使用__mro__去查找相应的父类。很明显,它从当前所找到的类开始搜索MRO。更多详情,请再看一下贵铎·范·罗萨姆有关统一类型和类的文章,他甚至给出了一个super()的纯Python实现,这样,你可以加深其印象,知道它是如何工作的!
最后想到…super()的主要用途,是来查找父类的属性,比如super (MyClass,self).__init__()。如果你没有执行这样的查找,你可能不需要使用super()。
有很多如何使用super()的例子分散在本章中。记得阅读一下第13.11.2节中有关super()的重要提示,尤其是核心笔记。
13.12.6 vars()
vars()内建函数与dir()相似,只是给定的对象参数都必须有一个__dict__属性。vars()返回一个字典,它包含了对象存储于其__dict__中的属性(键)和值。如果提供的对象没有这样一个属性,则会引发一个TypeError异常。如果没有提供对象作为vars()的一个参数,它将显示一个包含本地名字空间的属性(键)及其值的字典,也就是,locals()。我们来看一下例子,使用类实例调用vars():

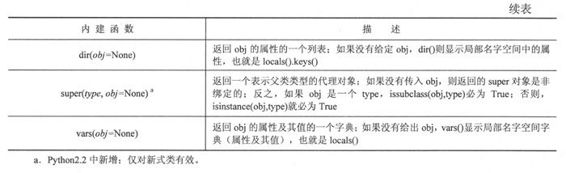
表13.3概括了类和类实例的内建函数。
13.13 用特殊方法定制类
我们已在本章前面部分讲解了方法的两个重要方面:首先,方法必须在调用前被绑定(到它们相应类的某个实例中);其次,有两个特殊方法可以分别作为构造器和解构器的功能,分别名为__init__()和__del__()。
事实上,__init__()和__del__()只是可自定义特殊方法集中的一部分。它们中的一些有预定义的默认行为,而其他一些则没有,留到需要的时候去实现。这些特殊方法是Python中用来扩充类的强有力的方式。它们可以实现:
模拟标准类型
重载操作符
特殊方法允许类通过重载标准操作符+, *,甚至包括分段下标及映射操作操作[]来模拟标准类型。如同其他很多保留标识符,这些方法都是以双下划线(__)开始及结尾的。表13.4列出了所有特殊方法及其他的描述。
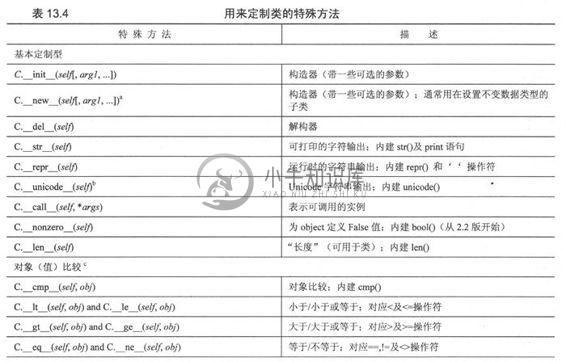
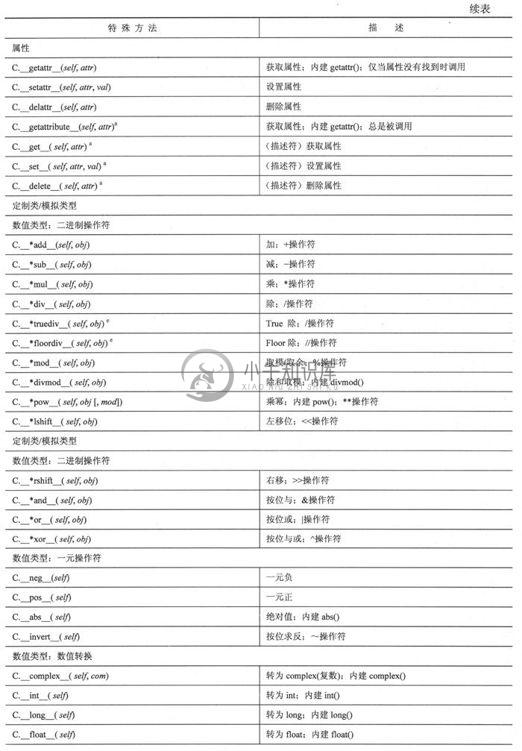

基本的定制和对象(值)比较特殊方法在大多数类中都可以被实现,且没有同任何特定的类型模型绑定。延后设置,也就是所谓的富比较(Rich Comparison),在Python2.1中加入。属性组帮助管理你的类的实例属性。这同样独立于模型。还有一个,__getattribute__(),它仅用在新式类中,我们将在后面的章节中对它进行描述。
特殊方法中数值类型部分可以用来模拟很多数值操作,包括那些标准(一元和二进制)操作符、类型转换、基本表示法及压缩。还有用来模拟序列和映射类型的特殊方法。实现这些类型的特殊方法将会重载操作符,以使它们可以处理你的class类型的实例。
另外,除操作符__*truediv__()和__*floordiv__()在Python 2.2中加入,用来支持Python除操作符中待定的更改——可查看5.5.3节。基本上,如果解释器启用新的除法,不管是通过一个开关来启动Python,还是通过“from__future__import division”,单斜线除操作(/)表示的将是”真”除法,意思是它将总是返回一个浮点值,不管操作数是否为浮点型或者整型(复数除法保持不变)。双斜线除操作(//)将提供大家熟悉的浮点除法,从标准编译型语言像C/C++及Java过来的工程师一定对此非常熟悉。同样,这些方法只能处理实现了这些方法并且启用了新的除操作的类的那些符号。
表格中,在它们的名字中,用星号通配符标注的数值二进制操作符则表示这些方法有多个版本,在名字上有些许不同。星号可代表在字符串中没有额外的字符,或者一个简单的“r”指明是一个右结合操作。没有“r”,操作则发生在对于selfOP obj的格式;“r”的出现表明格式obj OP self。比如,__add__(self, obj)是针对self+obj的调用,而__radd__(self, obj)则针对obj+self来调用。
增量赋值,起于Python 2.0,介绍了“原位”操作符。一个“i”代替星号的位置,表示左结合操作与赋值的结合,相当是在self=self OP obj。举例,__iadd__(self, obj)相当于self=self+obj的调用。
随着Python 2.2中新式类的引入,有一些更多的方法增加了重载功能。然而,在本章开始部分提到过,我们仅关注经典类和新式类都适应的核心部分,本章的后续部分,我们介绍新式类的高级特性。
13.13.1 简单定制(RoundFloat2)
我们的第一个例子很普通。在某种程度上,它基于我们前面所看到的从Python类型中派生出的派生类RoundFloat。这个例子很简单。事实上,我们甚至不想去派生任何东西(当然,除object外)……我们也不想采用与floats有关的所有“好东西”。不,这次,我们想创建一个苗条的例子,这样你可以对类定制的工作方式有一个更好的理解。这种类的前提与其他类是一样的:我们只要一个类来保存浮点型,四舍五入,保留两位小数位。

这个类仅接收一个浮点值——它断言了传递给构造器的参数类型必须为一个浮点型——并且将其保存为实例属性值。让我们来试试,创建这个类的一个实例:

你已看到,它因输入非法,而“噎住”,但如果输入正确时,就没有任何输出了。可是,当把这个对象转存在交互式解释器中时,看一下发生了什么。我们得到一些信息,却不是我们要找的。(我们想看到数值,对吧?)调用print语句同样没有明显的帮助。
不幸的是,print(使用str())和真正的字符串对象表示(使用repr())都没能显示更多有关我们对象的信息。一个好的办法是,去实现__str__()和__repr__()二者之一,或者两者都实现,这样我们就能“看到”我们的对象是个什么样子了。换句话说,当你想显示你的对象,实际上是想看到有意义的东西,而不仅仅是通常的Python对象字符串(<object object at id>)。让我们来添加一个__str__()方法,以覆盖默认的行为:

现在我们得到下面的:

我们还有一些问题……一个问题是仅仅在解释器中转储(dump)对象时,仍然显示的是默认对象符号,但这样做也算不错。如果我们想修复它,只需要覆盖__repr__()。因为字符串表示法也是Python对象,我们可以让__repr__()和__str__()的输出一致。
为了完成这些,只要把__str__()的代码复制给__repr__()。这是一个简单的例子,所以它没有真正对我们造成负面影响,但作为程序员,你知道那不是最好的办法。如果__str__()中存在bug,那么我们会将bug也复制给__repr__()了。
最好的方案,在__str__()中的代码也是一个对象,同所有对象一样,引用可以指向它们,所以,我们可以仅仅让__repr__()作为__str__()的一个别名:
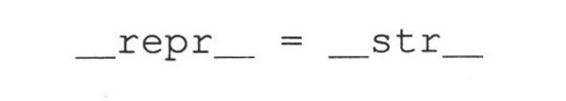
在带参数5.5964的第二个例子中,我们看到它舍入值刚好为5.6,但我们还是想显示带两位小数的数。来一个更妙的方法吧,看下面:

这里就同时具备str()和repr()的输出了:

例13.2 基本定制(roundFloat2.py)


在本章开始部分,最初的RoundFloat例子,我们没有担心所有细致对象的显示问题;原因是__str__()和__repr__()作为float类的一部分已经为我们定义好了。我们所要做的就是去继承它们。增强版本“手册”中需要另外的工作。你发现派生是多么的有益了吗?我们甚至不需要知道解释器在继承树上要执行多少步才能找到一个已声明的你正在使用却没有考虑过的方法。我们将在例13.2中列出这个类的全部代码。
现在开始一个稍复杂的例子。
13.13.2 数值定制(Time60)
作为第一个实际的例子,我们可以想象需要创建一个简单的应用,用来操作时间,精确到小时和分。我们将要创建的这个类可用来跟踪职员工作时间,ISP用户在线时间,数据库总的运行时间(不包括备份及升级时的停机时间),在扑克比赛中玩家总时间,等等。
在Time60类中,我们将整型的小时和分钟作为输入传给构造器。

1.显示
同样,如前面的例子所示,在显示我们的实例的时候,我们需要一个有意义的输出,那么就要覆盖__str__()(如果有必要的话,__repr__()也要覆盖)。我们都习惯看小时和分,用冒号分隔开的格式,比如,“4:30”,表示4个小时,加半个小时(4个小时又30分钟):

用此类,可以实例化一些对象。在下面的例子中,我们启动一个工时表来跟踪对应构造器的计费小时数:

输出不错,正是我们想看到的。下一步干什么呢?可考虑与我们的对象进行交互。比如在时间片的应用中,有必要把Time60的实例放到一起让我们的对象执行所有有意义的操作。我们更喜欢像这样的:

2. 加法
Python的重载操作符很简单。像加号(+),我们只需要重载__add__()方法,如果合适,还可以用__radd__()及__iadd__()。稍后有更多有关这方面的描述。实现__add__()听起来不难——只要把分和小时加在一块。大多数复杂性源于我们怎么处理这个新的总数。如果我们想看到“21:45”,就必须认识到这是另一个Time60对象,我们没有修改mon或tue,所以,我们的方法就应当创建另一个对象并填入计算出来的总数。
实现__add__()特殊方法时,首先计算出个别的总数,然后调用类构造器返回一个新的对象:

和正常情况下一样,新的对象通过调用类来创建。唯一的不同点在于,在类中,你一般不直接调用类名,而是使用self的__class__属性,即实例化self的那个类,并调用它。由于self.__class__与Time60相同,所以调用self.__class__()与调用Time60()是一回事。
不管怎样,这是一个更面向对象的方式。另一个原因是,如果我们在创建一个新对象时,处处使用真实的类名,然后,决定将其改为别的名字,这时,我们就不得不非常小心地执行全局搜索并替换。如果靠使用self.__class__,就不需要做任何事情,只需要直接改为你想要的类名。
好了,我们现在来使用加号重载,“增加” Time60对象:

哎哟,我们忘记添加一个别名__repr给str__了,这很容易修复。你可能会问,“当我们试着在重载情况下使用一个操作符,却没有定义相对应的特殊方法时还有很多需要优化和重要改良的地方,会发生什么事呢?”答案是一个TypeError异常:

3. 原位加法
有了增量赋值(在Python 2.0中引入),我们也许还有希望覆盖“原位”操作,比如,__iadd__()。这是用来支持像mon+= tue这样的操作符,并把正确的结果赋给mon。重载一个__i*__()方法的唯一秘密是它必须返回self。把下面的片段加到我们例子中,以修复上面的repr()问题,并支持增量赋值:

下面是结果输出:


注意,使用id()内建函数是用来确定一下,在原位加的前后,我们确实是修改了原来的对象,而没有创建一个新的对象。对一个具有巨大潜能的类来说,这是很好的开始。在例13.3中给出了Time60的类的完全定义。
例13.3 中级定制(time60.py)

例13.4 随机序列迭代器(randSeq.py)


4. 进一步优化
现在暂时告一段落,但在这个类中,还有很多需要优化和改良的地方。比如,如果我们不传入两个分离的参数,而传入一个2元组给构造器作为参数,是不是更好些呢?如果是像“10:30”这样的字符串的话,结果会怎样?
答案是肯定的,你可以这样做,在Python中很容易做到,但不是像很多其他面向对象语言一样通过重载构造器来实现。Python不允许用多个签名重载可调用对象。所以实现这个功能的唯一的方式是使用单一的构造器,并由isinstance()和(可能的)type()内建函数执行自省功能。
能支持多种形式的输入,能够执行其他操作像减法等,可以让我们的应用更健壮、灵活。当然这些是可选的,就像“如虎添翼”,但我们首先应该担心的是两个中等程度的缺点:首先当比十分钟还少时,这种格式并不是我们所希望的。其次不支持60进制(sexagesimal [1])(基数60,以60为分母)的操作:

显示wed结果是“12:05”,把thu和fri加起来结果会是”19:15”。修改这些缺陷,实现上面的改进建议可以实际性地提高你编写定制类技能。这方面的更新,更详细的描述在本章的练习13-20中。
我们希望你现在对于操作符重载、为什么要使用操作符重载及如何使用特殊方法来实现它已有了一个更好的理解了。接下来为选看章节内容,让我们来了解更多复杂的类定制的情况。
13.13.3 迭代器(RandSeq和AnyIter)
1. RandSeq
我们正式介绍迭代器是在第8章,但在全书中都在用它。它可以一次一个的遍历序列(或者是类似序列对象)中的项。在第8章中,我们描述了如何利用一个类中的__iter__()和next()方法,来创建一个迭代器。我们在此展示两个例子。
第一个例子是RandSeq (RANDom SEQuence的缩写)。我们给我们的类传入一个初始序列,然后让用户通过next()去迭代(无穷)。
__init__()方法执行前述的赋值操作。__iter__()仅返回self,这就是如何将一个对象声明为迭代器的方式,最后,调用next()来得到迭代器中连续的值。这个迭代器唯一的亮点是它没有终点。
这个例子展示了一些我们可以用定制类迭代器来做的与众不同的事情。一个是无穷迭代。因为我们无损地读取一个序列,所以它是不会越界的。每次用户调用next()时,它会得到下一个迭代值,但我们的对象永远不会引发Stoplteration异常。我们来运行它,将会看到下面的输出:

例13.5 任意项的迭代器(anylter.py)

2. AnyIter
在第二个例子中,我们的确创建了一个迭代器对象,我们传给next()方法一个参数,控制返回条目的数目,而不是去一次一个地迭代每个项。下面是我们的代码(ANY number of items ITERator)(笔者这里的注释是告诉读者类“Anylter”是如何命名的,译者注):
和RandSeq类的代码一样,类Anylter很容易领会。我们在上面描述了基本的操作…它同其他迭代器一样工作,只是用户可以请求一次返回N个迭代的项,而不仅是一个项。
我们给出一个迭代器和一个安全标识符(safe)来创建这个对象。如果这个标识符(safe)为真(True),我们将在遍历完这个迭代器前,返回所获取的任意条目,但如果这个标识符为假(False),则在用户请求过多条目时,将会引发一个异常。错综复杂的核心在于next(),特别是它如何退出的(14~21行)。
在next()的最后一部分中,我们创建用于返回的一个列表项,并且调用对象的next()方法来获得每一项条目。如果我们遍历完列表,得到一个Stoplteration异常,这时则检查安全标识符(safe)。如果不安全(即,self.safe=False),则将异常抛还给调用者(raise);否则,退出(break)并返回(return)已经保存过的所有项

上面程序的运行没有问题,因为迭代器正好符合项的个数。当情况出现偏差,会发生什么呢?让我们首先试试“不安全(unsafe)”的模式,这也就是紧随其后创建我们的迭代器:

因为超出了项的支持量,所以出现了Stoplteration异常,并且这个异常还被重新引发回调用者(第20行)。如果我们使用“安全(safe)”模式重建迭代器,再次运行一次同一个例子的话,我们就可以在项失控出现前得到迭代器所得到的元素:

13.13.4 *多类型定制(NumStr)
现在创建另一个新类,NumStr,由一个数字-字符对组成,相应地,记为n和s,数值类型使用整型(integer)。尽管这组顺序对的“合适的”记号是(n,s),但我们选用[n::s]来表示它,有点不同。暂不管记号,这两个数据元素只要我们模型考虑好了,就是一个整体。可以创建我们的新类了,叫做NumStr,有下面的特征:
1.初始化
类应当对数字和字符串进行初始化;如果其中一个(或两)没有初始化,则使用0和空字符串,也就是,n=0且s=‘’,作为默认。
2.加法
我们定义加法操作符,功能是把数字加起来,把字符连在一起;要点部分是字符串要按顺序相连。比如,NumStr1=[nl::sl]且NumStr2=[n2::s2]。则NumStr1+NumStr2表示[n1+n2::s1+s2],其中,+代表数字相加及字符相连接。
3.乘法
类似的,定义乘法操作符的功能为数字相乘、字符累积相连,也就是NumStrl *NumStr2=[nl*n::sl*n]。
4. False值
当数字的数值为0且字符串为空时,也就是当NumStr=[0::“”]时,这个实体即有一个false值。
5.比较
比较一对NumStr对象,比如,[n1::s1] vs.[n2::s2],我们可以发现九种不同的组合(即nl>n2和s1<s2、n1==n2和s1>s2等)。对数字和字符串,我们一般按照标准的数值和字典顺序的进行比较,即,如果obj1<obj2,普通比较cmp(obj1,obj2)的返回值是一个小于0的整型,当obj1>obj2时,比较的返回值大于0,当两个对象有相同的值时,比较的返回值等于0。
我们的类的解决方案是把这些值相加,然后返回结果。有趣的是cmp()不会总是返回-1、0或1。上面提到过,它是一个小于、等于或大于0的整数。
为了能够正确的比较对象,我们需要让__cmp__()在(n1>n2)且(s1>s2)时返回-1,在(nl<n2)且(s1<s2)时返回-1,而当数值和字符串都一样时,或是两个比较的结果正相反时(即(n1<n2)且(s1>s2),或相反)返回0,反之亦然。
例13.6 多类型类定制(numstr.py)


根据上面的特征,我们列出numstr.py的代码,执行一些例子:


6.逐行解释
1 ~ 7行
脚本的开始部分为构造器__init__(),通过调用NumStr()时传入的值来设置实例,完成自身初始化。如果有参数缺失,属性则使用false值,即默认的0或空字符,这取决于参数情况。
一个值得注意的偏好是命名属性时,使用双下划线。我们在下一节中会看到,这是在信息隐藏时强加一个级别——尽管不够成熟。程序员导入一个模块时,就不能直接访问到这些数据元素。我们正试着执行一种OO设计中的封装特性,只有通过存取函数才能访问。如果这种语法让你感觉有点怪异,不舒服的话,你可以从实例属性中删除所有双下划线,程序同样可以良好地运行。
所有的由双下划线(__)开始的属性都被“混淆”(mangled)了,导致这些名字在程序运行时很难被访问到。但是它们并没有用一种难于被逆向工程的方法来“混淆”。事实上,“混淆”属性的方式已众所周知,很容易被发现。这里主要是为了防止这些属性在被外部模块导入时,由于被意外使用而造成的名字冲突。我们将名字改成含有类名的新标识符,这样做,可以确保这些属性不会被无意“访问”。更多信息,请参见13.14节中关于私有成员的内容。
9 ~ 12行
我们把顺序对的字符串表示形式确定为“[num::‘str’]”,这样不论我们的实例用str()还是包含在print语句中时候,我们都可以用__str__()来提供这种表示方式。我们想强调一点,第二个元素是一个字符串,如果用户看到由引号标记的字符串时,会更加直观。要做到这点,我们使用“reprO”表示法对代码进行转换,把“%s”替换成“%r”。这相当于调用repr()或者使用单反引号来给出字符串的可求值版本——可求值版本的确要有引号:

如果在self.__string中没有调用repr()(去掉单反引号或使用“%s”)将导致字符串引号丢失:

现在对实例再次调用print,结果:

没有引号,看起来会如何呢?不能信服“foo”是一个字符串,对吧?它看起来更像一个变量。连作者可能也不能确定(我们快点悄悄回到这一变化之前,假装从来没看到这个内容)。
代码中__str__()函数后的第一行是把这个函数赋给另一个特殊方法名,__repr__。我们决定我们的实例的一个可求值的字符串表示应当与可打印字符串表示是一样的,而不是去定义一个完整的新函数,成为__str__()的副本,我们仅去创建一个别名,复制其引用。当你实现__str__()后,一旦使用那个对象作为参数来应用内建str()函数,解释器就会调用这段代码,对__repr__()及repr()也一样。
如果不去实现__repr__(),我们的结果会有什么不同呢?如果赋值被取消,只有调用str()的print语句才会显示对象的内容。而可求值字符串表示恢复成默认的Python标准形式<…some_object_information…>

14 ~ 21行
我们想加到我们的类中的一个特征就是加法操作,前面已提到过。Python用于定制类的特征之一是,我们可以重载操作符,以使定制的这些类型更“实用”。调用一个函数,像“add(obj1,obj2)”是为“add”对象obj1和ojb2,这看起来好像加法,但如果能使用加号(+)来调用相同的操作是不是更有说服力呢?像这样,obj1+obj2。
重载加号,需要去为self(SELF)和其他操作数实现(OTHER)__add__()。__add__()函数考虑Self+Other的情况,但我们不需要定义__radd__()来处理Other+Self,因为这可以由Other的__add__()去考虑。数值加法不像字符串那样结果受到(操作数)顺序的影响。
加法操作把两个部分中的每一部分加起来,并用这个结果对形成一个新的对象——通过将结果作为参数调用self.__class__()来实例化(同样,在前面已解释过)。碰到任何类型不正确的对象时,我们会引发一个TypeError异常。
23 ~ 29行
我们也可以重载星号[靠实现__mul__()],执行数值乘法和字符串重复,并同样通过实例化来创建一个新的对象。因为重复只允许整型在操作数的右边,因此也必执行此规则。基于同样的原因,我们在此也没有实现__rmul__()。
31 ~ 32行
Python对象任何时候都有一个布朗值。对标准类型而言,对象有一个false值的情况为:它是一个类似于0的数值,或是一个空序列,或者映射。就我们的类而言,我们选择的数值必须为0,字符串要为空作为一个实例有一个false值的条件。覆盖__nonzero__()方法,就是为此目的。其他对象,像严格模拟序列或映射类型的对象,使用一个长度为0作为false值。这些情况,你需要实现__len__()方法,以实现那个功能。
34 ~ 41行
__norm__cval()(“normalize cmp() value的缩写”)不是一个特殊方法。它是一个帮助我们重载__cmp__()的助手函数:唯一的目的就是把cmp()返回的正值转为1,负值转为-1。cmp()基于比较的结果,通常返回任意的正数或负数(或0),但为了我们的目的,需要严格规定返回值为-1、0和1。对整型调用cmp()及与0比较,结果即是我们所需要的,相当于如下代码片段:

两个相似对象的实际比较是比较数字,比较字符串,然后返回这两个比较结果的和。
13.14 私有化
默认情况下,属性在Python中都是“公开的”,类所在模块和导入了类所在模块的其他模块的代码都可以访问到。很多00语言给数据加上一些可见性,只提供访问函数来访问其值。这就是熟知的实现隐藏,是对象封装中的一个关键部分。
大多数面向对象语言提供“访问控制符”来限定成员函数的访问。
1.双下划线(__)
Python为类元素(属性和方法)的私有性提供初步的形式。由双下划线开始的属性在运行时被“混淆”,所以直接访问是不允许的。实际上,会在名字前面加上下划线和类名。比如,以例13.6(numstr.py)中的self.__num属性为例,被“混淆”后,用于访问这个数据值的标识就变成了self.__NumStr__num。把类名加上后形成的新的“混淆”结果将可以防止在祖先类或子孙类中的同名冲突。
尽管这样做提供了某种层次上的私有化,但算法处于公共域中并且很容易被“击败”。这更多的是一种对导入源代码无法获得的模块或对同一模块中的其他代码的保护机制。
这种名字混淆的另一个目的,是为了保护XXX变量不与父类名字空间相冲突。如果在类中有一个XXX属性,它将不会被其子类中的XXX属性覆盖。(回忆一下,如果父类仅有一个XXX属性,子类也定义了这个,这时,子类的XXX就是覆盖了父类的XXX,这就是为什么你必须使用PARENT.XXX来调用父类的同名方法。)使用XXX,子类的代码就可以安全地使用XX,而不必担心它会影响到父类中的XXX。
2.单下划线(_)
与我们在第12章发现的那样,简单的模块级私有化只需要在属性名前使用一个单下划线字符。这就防止模块的属性用“from mymodule import*”来加载。这是严格基于作用域的,所以这同样适合于函数。
在Python2.2中引进的新式类,增加了一套全新的特征,让程序员在类及实例属性提供保护的多少上拥有大量重要的控制权。尽管Python没有在语法上把private, protected、 friend或protected friend等特征内建于语言中,但是可以按你的需要严格地定制访问权。我们不可能涵盖所有的内容,但会在本章后面给你一些有关新式类属性访问的建议。
13.15 *授权
13.15.1 包装
“包装”在Python编程世界中经常会被提到的一个术语。它是一个通用的名字,意思是对一个已存在的对象进行包装,不管它是数据类型还是一段代码,可以是对一个已存在的对象增加新的、删除不要的或修改其他已存在的功能。
在Python 2.2版本前,从Python标准类型子类化或派生类都是不允许的。即使你现在可以对新式类这样做,这一观念仍然很流行。你可以包装任何类型作为一个类的核心成员,以使新对象的行为模仿你想要的数据类型中已存在的行为,并且去掉你不希望存在的行为;它可能会要做一些额外的事情。这就是“包装类型”。在附录中,我们还将讨论如何扩充Python,包装的另一种形式。
包装包括定义一个类,它的实例拥有标准类型的核心行为。换句话说,它现在不仅能唱能跳,还能够像原类型一样步行,说话。图13-4举例说明了在类中包装的类型看起像个什么样子。在图的中心为标准类型的核心行为,但它也通过新的或最新的功能,甚至可能通过访问实际数据的不同方法得到提高。
类对象(其表现像类型)
你还可以包装类,但这不会有太多的用途,因为已经有用于操作对象的机制,并且在上面已描述过,对标准类型有对其进行包装的方式。你如何操作一个已存的类,模拟你需要的行为,删除你不喜欢的,并且可能让类表现出与原类不同的行为呢?我们前面已讨论过,就是采用派生。

图 13-4 包装类型
13.15.2 实现授权
授权是包装的一个特性,可用于简化处理相关命令性功能,采用已存在的功能以达到最大限度的代码重用。
包装一个类型通常是对已存在的类型的一些定制。我们在前面提到过,这种做法可以新建、修改或删除原有产品的功能。其他的则保持原样,或者保留已存功能和行为。授权的过程,即是所有更新的功能都是由新类的某部分来处理,但已存在的功能就授权给对象的默认属性。
实现授权的关键点就是覆盖__getattr__()方法,在代码中包含一个对getattr()内建函数的调用。特别地,调用getattrO以得到默认对象属性(数据属性或者方法)并返回它以便访问或调用。特殊方法__getattr__()的工作方式是,当搜索一个属性时,任何局部对象首先被找到(定制的对象)。如果搜索失败了,则__getattr__()会被调用,然后调用getattrO得到一个对象的默认行为。
换言之,当引用一个属性时,Python解释器将试着在局部名称空间中查找那个名字,比如一个自定义的方法或局部实例属性。如果没有在局部字典中找到,则搜索类名称空间,以防一个类属性被访问。最后,如果两类搜索都失败了,搜索则对原对象开始授权请求,此时,__getattr__()会被调用。
1.包装对象的简例
看一个例子。这个类已乎可以包装任何对象,提供基本功能,比如使用repr()和str()来处理字符串表示法。另外定制由get()方法处理,它删除包装并且返回原始对象。所以保留的功能都授权给对象的本地属性,在必要时,可由__getattr__()获得。
下面是包装类的例子:

在第一个例子中,我们将用到复数,因为所有Python数值类型,只有复数拥有属性:数据属性和conjugate()内建方法(求共轭复数,译者注)。记住,属性可以是数据属性,还可以是函数或方法:

一旦我们创建了包装的对象类型,只要由交互解释器调用repr(),就可以得到一个字符串表示。然后我们继续访问了复数的三种属性,我们的类中一种都没有定义。在例子中,寻找实部,虚部及共轭复数的定义……杳无踪影!
对这些属性的访问,是通过getattr()方法,授权给对象。最终调用get()方法没有授权,因为它是为我们的对象定义的——它返回包装的真实的数据对象。
下一个使用我们的包装类的例子用到一个列表。我们将会创建对象,然后执行多种操作,每次授权给列表方法。

注意,尽管我们正在我们的例子中使用实例,它们展示的行为与它们包装的数据类型非常相似。然后,需要明白,只有已存在的属性是在此代码中授权的。
特殊行为没有在类型的方法列表中,不能被访问,因为它们不是属性。一个例子是,对列表的切片操作,它是内建于类型中的,而不是像append()方法那样作为属性存在的。从另一个角度来说,切片操作符是序列类型的一部分,并不是通过__getitem__()特殊方法来实现的。

AttributeError异常出现的原因是切片操作调用了__getitem__()方法,且__getitme__()没有作为一个类实例方法进行定义,也不是列表对象的方法。回忆一下,什么时候调用getattr()呢?当在实例或类字典中的完整搜索失败后,就调用它来查找一个成功的匹配。你在上面可以看到,对getattrO的调用就是失败的那个,触发了异常。
然而,我们还有一种“作弊”的方法,访问实际对象[通过我们的get()方法]和它的切片能力。

你现在可能知道为什么我们实现get()方法了——仅仅是为了我们需要取得对原对象进行访问这种情况,我们可以从访问调用中直接访问对象的属性,而忽略局部变量(realList):

get()方法返回一个对象,随后被索引以得到切片片段。

一旦你熟悉了对象的属性,你就能够开始理解一些信息片段从何而来,能够利用新得到的知识来重复功能:
这总结了我们的简单包装类的例子。我们还刚开始接触使用类型模拟来进行类自定义。你将会发现你可以进行无限多的改进,来进一步增加你的代码的用途。一种改进方法是为对象添加时间戳。在下一小节中,我们将对我们的包装类增加另一个维度(dimension):
2.更新简单的包裹类
创建时间、修改时间和访问时间是文件的几个常见属性,但并不是说你不能为对象加上这类信息,毕竟一些应用能因有这些额外信息而受益。
如果你对使用这三类时间顺序(chronological)数据还不熟,我们将会对它们进行解释。创建时间(或‘ctime’)是实例化的时间,修改时间(或‘mtime’)指的是核心数据升级的时间[通常会调用新的set()方法],而访问时间(或‘atime’)是最后一次对象的数据值被获取或者属性被访问时的时间戳。
更新我们前面定义的类,可以创建一个模块twrapme.py,看例13.7。
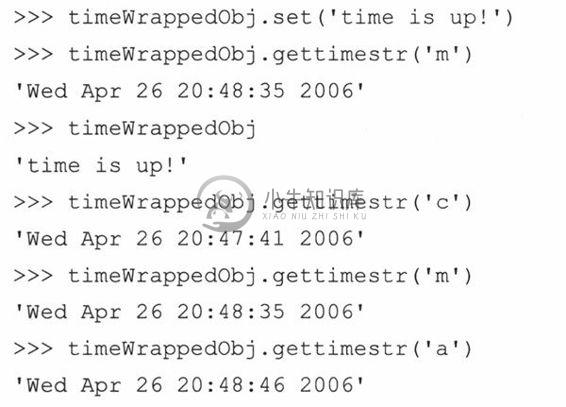
如何更新这些代码呢?好,首先,你将会发现增加了三个新方法:gettimeval()、gettimestr()和set()。我们还增加数行代码,根据所执行的访问类型,更新相应的时间戳。
例13.7 包装标准类型(twrapme.py)
类定义包装了任何内建类型,增加时间属性;get(),set(),还有字符串表示的方法;授权所有保留的属性,访问这些标准类型。

gettimeval()方法带一个简单的字符参数,“c”、“m”或“a”,相应地,对应于创建、修改或访问时间,并返回相应的时间,以一个浮点值保存。gettimestr()仅仅返回一个经time.ctime()函数格式化的打印良好的字符串形式的时间。
为新的模块作一个测试驱动。我们已看到授权是如何工作的,所以,我们将包装没有属性的对象,来突出刚加入的新的功能。在例子中,我们包装了一个整型,然后将其改为字符串。

你将注意到,一个对象在第一次被包装时,创建、修改及最后一次访问时间都是一样的。一旦对象被访问,访问时间即被更新,但其他的没有动。如果使用set()来置换对象,则修改和最后一次访问时间会被更新。例子中,最后是对对象的读访问操作。
改进包装一个特殊对象
下一个例子,描述了一个包装文件对象的类。我们的类与一般带一个异常的文件对象行为完全一样:在写模式中,字符串只有全部为大写时才写入文件。
这里我们要解决的问题是,当你正在写一个文本文件,其数据可能会被一台大型机读取。很多老式机器在处理时严格要求大写字母,所以我们要实现一个文件对象,其中所有写入文件的文本会自动转化为大写,程序员就不必担心了。
事实上,唯一值得注意的不同点是并不使用open()内建函数,而是调用CapOpen类时行初始化,尽管参数同open()完全一样。
例13.8展示那段代码,文件名是capOpen.py。下面看一下例子中是如何使用这个类的:


例13.8 包装文件对象(capOpen.py)
这个类扩充了《Python FAQ》中的一个例子,提供一个文件类对象,定制write()方法,同时,给文件对象授权其他的功能。

可以看到,唯一不同的是第一次对CapOpen()的调用,而不是open()。如果你正与一个实际文件对象,而非行为像文件对象的类实例进行交互,那么其他所有代码与你本该做的是一样的。除了write(),所有属性都已授权给文件对象。为了确定代码是否正确,我们加载文件,并显示其内容(注:可以使用open()或CapOpen(),这里因在本例中用到,所以选用CapOpen())。

13.16 新式类的高级特性(Python 2.2+)
13.16.1 新式类的通用特性
我们已提讨论过有关新式类的一些特性。由于类型和类的统一,这些特性中最重要的是能够子类化Python数据类型。其中一个副作用是,所有的Python内建的“casting”或转换函数现在都是工厂函数。当这些函数被调用时,你实际上是对相应的类型进行实例化。
下面的内建函数,追随Python多日,都已“悄悄地(也许不是)”转化为工厂函数:

还有,加入了一些新的函数来管理这些“散兵游勇”:
basestring() [2]
dict()
bool()
set() [3]
object()
classmethod()
staticemethod()
super()
property()
file()
这些类名及工厂函数使用起来,很灵活。不仅能够创建这些类型的新对象,它们还可以用来作为基类,去子类化类型,现在还可以用于isinstance()内建函数。使用isinstance()能够用于替换用烦了的旧风格,而使用只需少量函数调用就可以得到清晰代码的新风格。比如,为测试一个对象是否是一个整型,旧风格中,我们必须调用type()两次或者import相关的模块并使用其属性;但现在只需要使用isinstance(),甚至在性能上也有所超越:

记住:尽管isinstance()很灵活,但它没有执行“严格匹配”比较——如果obj是一个给定类型的实例或其子类的实例,也会返回True。但如果想进行严格匹配,你仍然需要使用is操作符。
请复习13.12.2节中有关isinstance()的深入解释,还有在第4章中介绍这些调用是如何随同Python的变化而变化的。
13.16.2 __slots__类属性
字典位于实例的“心脏”。__dict__属性跟踪所有实例属性。举例来说,你有一个实例inst,它有一个属性foo,那使用inst.foo来访问它与使用inst.__dict__[‘foo’]来访问是一致的。
字典会占据大量内存,如果你有一个属性数量很少的类,但有很多实例,那么正好是这种情况。为内存上的考虑,用户现在可以使用__slots属性来替代dict__。
基本上,__slots__是一个类变量,由一序列型对象组成,由所有合法标识构成的实例属性的集合来表示。它可以是一个列表,元组或可迭代对象。也可以是标识实例能拥有的唯一的属性的简单字符串。任何试图创建一个其名不在__slots__中的名字的实例属性都将导致AttributeError异常:

这种特性的主要目的是节约内存。其副作用是某种类型的“安全”,它能防止用户随心所欲的动态增加实例属性。带__slots属性的类定义不会存在dict__了(除非你在__slots__中增加‘__dict__’元素)。更多有关__slots__的信息,请参见《Python(语言)参考手册》(Python(Language)Reference Manual)中有关数据模型章节。
13.16.3 __getattribute__()特殊方法
Python类有一个名为__getattr__()的特殊方法,它仅当属性不能在实例的__dict__或它的类(类的__dict__),或者祖先类(其__dict__)中找到时,才被调用。我们曾在实现授权中看到过使用__getattr__()。
很多用户碰到的问题是,他们想要一个适当的函数来执行每一个属性访问,不光是当属性不能找到的情况。这就是__getattribute__()用武之处了。它使用起来,类似__getattr__(),不同之处在于,当属性被访问时,它就一直都可以被调用,而不局限于不能找到的情况。
如果类同时定义了__getattribute__()及__getattr__()方法,除非明确从get-attribute()调用,或__getattribute__()引发了AttributeError异常,否则后者不会被调用。
如果你将要在此(译者注:__getattribute__()中)访问这个类或其祖先类的属性,请务必小心。如果你在__getattribute__()中不知何故再次调用了__getattribute__(),你将会进入无穷递归。为避免在使用此方法时引起无穷递归,为了安全地访问任何它所需要的属性,你总是应该调用祖先类的同名方法;比如,super(obj,self).__getattribute__(attr)。此特殊方法只在新式类中有效。同__slots__一样,你可以参考《Python(语言)参考手册》中数据模型章节,以得到更多有关__getattribute__()的信息。
13.16.4 描述符
描述符是Python新式类中的关键点之一。它为对象属性提供强大的API。你可以认为描述符是表示对象属性的一个代理。当需要属性时,可根据你遇到的情况,通过描述符(如果有)或者采用常规方式句点属性标识法)来访问它。
如你的对象有代理,并且这个代理有一个“get”属性(实际写法为__get__),当这个代理被调用时,你就可以访问这个对象了。当你试图使用描述符(set)给一个对象赋值或删除一个属性(delete)时,这同样适用。
1. __get__()、__set__()和__delete__()特殊方法
严格来说,描述符实际上可以是任何(新式)类,这种类至少实现了三个特殊方法__get__()、__set__()和__delete__()中的一个,这三个特殊方法充当描述符协议的作用。刚才提到过,__get__()可用于得到一个属性的值,__set__()是为一个属性进行赋值的,在采用del语句(或其他,其引用计数递减)明确删除掉某个属性时会调用__delete__()方法。在三者中,后者很少被实现。
还有,也不是所有的描述符都实现了__set__()方法。它们被当作方法描述符,或者更准确地说,是非数据描述符来被引用。那些同时覆盖__get__()和__set__()的类被称作数据描述符,它比非数据描述符要强大些。
__get__()__set__()及__delete__()的原型如下所示:

如果你想要为一个属性写个代理,必须把它作为一个类的属性,让这个代理来为我们做所有的工作。当你用这个代理来处理对一个属性的操作时,你会得到一个描述符来代理所有的函数功能。我们在前面的一节中已经讲过封装的概念。这里我们会进一步来探讨封装的问题。现在让我们来处理更加复杂的属性访问问题,而不是将所有任务都交给你所写的类中的对象们。
2. __getattribute__()特殊方法(2)
使用描述符的顺序很重要,有一些描述符的级别要高于其他的。整个描述符系统的心脏是__getattribute__(),因为对每个属性的实例都会调用到这个特殊的方法。这个方法被用来查找类的属性,同时也是你的一个代理,调用它可以进行属性的访问等操作。
回顾一下上面的原型,如果一个实例调用了__get__()方法,这就可能传入了一个类型或类的对象。举例来说,给定类X和实例x,x.foo由__getattribute__()转化成:
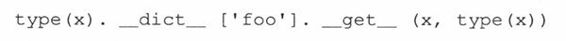
如果类调用了__get__()方法,那么None将作为对象被传入(对于实例,传入的是self):
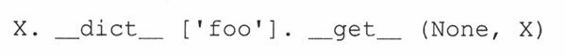
最后,如果super()被调用了,比如,给定Y为X的子类,然后用super(Y,obj).foo在obj.__class__.__mro__中紧接类Y沿着继承树来查找类X,然后调用:
然后,描述符会负责返回需要的对象。
3.优先级别
由于__getattribute__()的实现方式很特别,我们在此对__getattribute__()方法的执行方式做一个介绍。因此了解以下优先级别的排序就非常重要了:
类属性
数据描述符
实例属性
非数据描述符
默认为__getattr__()
描述符是一个类属性,因此所有的类属性皆具有最高的优先级。你其实可以通过把一个描述符的引用赋给其他对象来替换这个描述符。比它们优先级别低一等的是实现了__get__()和__set__()方法的描述符。如果你实现了这个描述符,它会像一个代理那样帮助你完成所有的工作!
否则,它就默认为局部对象的__dict__的值,也就是说,它可以是一个实例属性。接下来是非数据描述符。可能第一次听起来会吃惊,有人可能认为在这条“食物链”上非数据描述符应该比实例属性的优先级更高,但事实并非如此。非数据描述符的目的只是当实例属性值不存在时,提供一个值而已。这与以下情况类似:当在一个实例的__dict__中找不到某个属性时,才去调用__getattr__()。
关于__getattr__()的说明,如果没有找到非数据描述符,那么__getattribute__()将会抛出一个AttributeError异常,接着会调用__getattr__()作为最后一步操作,否则AttributeError会返回给用户。
4.描述符举例
让我们来看一个简单的例子……用一个描述符禁止对属性进行访问或赋值的请求。事实上,以下所有示例都忽略了全部请求,但它们的功能逐步增多,我们希望你通过每个示例逐步掌握描述符的使用:

我们建立一个类,这个类使用了这个描述符,给它赋值并显示其值:

这并没有什么有趣的……让我们来看看在这个描述符中写一些输出语句会怎么样?

现在我们来看看修改后的结果:

最后,我们在描述符所在的类中添加一个占位符,占位符包含有关于这个描述符的有用信息:


下面的输出结果表明我们前面提到的优先级层次结构的重要性,尤其是我们说过,一个完整的数据描述符比实例的属性具有更高的优先级:

请注意我们是如何给实例的属性赋值的。给实例属性c3.foo赋值为一个字符串“bar”。但由于数据描述符比实例属性的优先级高,所赋的值“bar”被隐藏或覆盖了。
同样地,由于实例属性比非数据描述符的优先级高,你也可以将非数据描述符隐藏。这就和你给一个实例属性赋值,将对应类的同名属性隐藏起来是同一个道理:

这是一个直白的示例。我们将foo作为一个函数调用,然后又将它作为一个字符串访问,但我们也可以使用另一个函数,而且保持相同的调用机制:

要强调的是:函数是非数据描述符,实例属性有更高的优先级,我们可以遮蔽任一个非数据描述符,只需简单的把一个对象赋给实例(使用相同的名字)就可以了。
我们最后这个示例完成的功能更多一些,它尝试用文件系统保存一个属性的内容,这是个雏形版本。
1 ~ 10行
在引入相关模块后,我们编写一个描述符类,类中有一个类属性(saved),它用来记录描述符访问的所有属性。描述符创建后,它将注册并且记录所有从用户处接收的属性名。
12 ~ 26行
在获取描述符的属性之前,我们必须确保用户给它们赋值后才能使用。如果上述条件成立,接着我们将尝试打开pickle文件以读取其中所保存的值。如果文件打开失败,将引发一个异常。文件打开失败的原因可能有以下几种:文件已被删除了(或从未创建过),或是文件已损坏,或是由于某种原因,不能被pickle模块反串行化。
18 ~ 38行
将属性保存到文件中需要经过以下几个步骤:打开用于写入的pickle文件(可能是首次创建一个新的文件,也可能是删掉旧的文件),将对象串行化到磁盘,注册属性名,使用户可以读取这些属性值。如果对象不能被pickle,将引发一个异常。注意,如果你使用的是Python2.5以前的版本,你就不能合并try-except和try-finally语句(第30~38行)。
例13.9 使用文件来存储属性(descr.py)
这个类是一个雏形,但它展示了描述符的一个有趣的应用——可以在一个文件系统上保存属性的内容。


40 ~ 45行
最后,如果属性被删除了,文件会被删除,属性名字也会被注销。以下是这个类的用法示例:


属性访问没有什么特别的,程序员并不能准确判断一个对象是否能被打包后存储到文件系统中(除非如最后示例所示,将模块pickle,我们不该这样做)。我们也编写了异常处理的语句来处理文件损坏的情况。在本例中,我们第一次在描述符中实现__delete__()方法。
请注意,在示例中,我们并没有用到obj的实例。别把obj和self搞混淆,这个self是指描述符的实例,而不是类的实例。
5.描述符总结
你已经看到描述符是怎么工作的。静态方法、类方法、属性(见下面一节),甚至所有的函数都是描述符。想一想:函数是Python中常见的对象。有内置的函数、用户自定义的函数、类中定义的方法、静态方法、类方法。这些都是函数的例子。它们之间唯一的区别在于调用方式的不同。通常,函数是非绑定的。虽然静态方法是在类中被定义的,它也是非绑定的。但方法必须绑定到一个实例上,类方法必须绑定到一个类上。一个函数对象的描述符可以处理这些问题,描述符会根据函数的类型确定如何“封装”这个函数和函数被绑定的对象,然后返回调用对象。它的工作方式是这样的:函数本身就是一个描述符,函数的__get__()方法用来处理调用对象,并将调用对象返回给你。描述符具有非常棒的适用性,因此从来不会对Python自己的工作方式产生影响。
6.属性和property()内建函数
属性是一种有用的特殊类型的描述符。它们是用来处理所有对实例属性的访问,其工作方式和我们前面说过的描述符相似。“一般”情况下,当你使用点属性符号来处理一个实例属性时,其实你是在修改这个实例的__dict__属性。
表面上来看,你使用property()访问和一般的属性访问方法没有什么不同,但实际上这种访问的实现是不同的——它使用了函数(或方法)。在本章的前面,你已看到在Python的早期版本中,我们一般用__getattr__()和__setattr__()来处理和属性相关的问题。属性的访问会涉及以上特殊的方法(和__getattribute__()),但是如果我们用property()来处理这些问题,你就可以写一个和属性有关的函数来处理实例属性的获取(getting)、赋值(setting)和删除(deleting)操作,而不必再使用那些特殊的方法了(如果你要处理大量的实例属性,使用那些特殊的方法将使代码变得很臃肿)。
property()内建函数有四个参数,它们是:
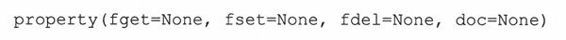
请注意property()的一般用法是,将它写在一个类定义中,property()接受一些传进来的函数(其实是方法)作为参数。实际上,property()是在它所在的类被创建时被调用的,这些传进来的(作为参数的)方法是非绑定的,所以这些方法其实就是函数!
下面的例子在类中建立一个只读的整型属性,用逐位异或操作符将它隐藏起来:

我们来运行这个例子,会发现它只保存我们第一次给出的值,而不允许我们对它做第二次修改:

下面是另一个关于setter的例子:

本示例的输出结果:


属性成功保存到x中并显示出来,是因为在调用构造器给x赋初始值前,在getter中已经将~x赋给了self.__x。
你还可以给自己写的属性添加一个文档字符串,参见下面这个例子:

为了说明这是可行的实现方法,我们在property中使用的是一个函数而不是方法。注意在调用函数时self作为第一个(也是唯一的)参数被传入,所以我们必须加一个伪变量把self丢弃。下面是本例的输出:

你明白properties是如何把你写的函数(fget、fset和fdel)影射为描述符的__get__()、__set__()和__delete__()方法的吗?你不必写一个描述符类,并在其中定义你要调用的这些方法。只要把你写的函数(或方法)全部传递给property()就可以了。
在你写的类定义中创建描述符方法的一个弊端是它会搞乱类的名字空间。不仅如此,这种做法也不会像property()那样很好地控制属性访问。如果不用property()这种控制属性访问的目的就不可能实现。我们的第二个例子没有强制使用property(),因为它允许对属性方法的访问(由于在类定义中包含属性方法):

APNPC(ActiveState Programmer Network Python Cookbook, http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/205183)上的一个聪明的办法解决了以下问题:
“借用”一个函数的名字空间;
编写一个用作内部函数的方法作为property()的(关键字)参数;
(用locals())返回一个包含所有的(函数/方法)名和对应对象的字典;
把字典传入property();
然后,去掉临时的名字空间。
这样,方法就不会再把类的名字空间搞乱了,因为定义在内部函数中的这些方法属于其他的名字空间。由于这些方法所属的名字空间已超出作用范围,用户是不能够访问这些方法的,所以通过使用属性property()来访问属性就成为了唯一可行的办法。根据APNPC上的方法,我们来修改这个类:


我们的代码工作如初,但有两点明显不同:(1)类的名字空间更加简洁,只有[‘__doc__’,‘__init__’,‘__module__’,‘x’];(2)用户不能再通过inst.set_x(40)给属性赋值,必须使用init.x=40。我们还使用函数修饰符(@property)将函数中的x赋值到一个属性对象。由于修饰符是从Python2.4版本开始引入的,如果你使用的是Python的早期版本2.2.x或2.3.x,请将修饰符@property去掉,在x()的函数声明后添加x=property(**x())。
13.16.5 元类和__metaclass__
1.元类(Metaclasses)是什么
元类可能是添加到新风格类中最难以理解的功能了。元类让你来定义某些类是如何被创建的,从根本上说,赋予你如何创建类的控制权(你甚至不用去想类实例层面的东西)。早在Python1.5的时代,人们就在谈论这些功能(当时很多人都认为不可能实现),但现在终于实现了。
从根本上说,你可以把元类想成是一个类中类,或是一个类,它的实例是其他的类。实际上,当你创建一个新类时,你就是在使用默认的元类,它是一个类型对象(对传统的类来说,它们的元类是types.ClassType)。当某个类调用type()函数时,你就会看到它到底是谁的实例:

2.什么时候使用元类
元类一般用于创建类。在执行类定义时,解释器必须要知道这个类的正确的元类。解释器会先寻找类属性__metaclass__,如果此属性存在,就将这个属性赋值给此类作为它的元类。如果此属性没有定义,它会向上查找父类中的__metaclass__。所有新风格的类如果没有任何父类,会从对象或类型中继承(type(object)当然是类型)。
如果还没有发现__metaclass__属性,解释器会检查名字为__metaclass__的全局变量;如果它存在,就使用它作为元类。否则,这个类就是一个传统类,并用types.ClassType作为此类的元类。(注意:在这里你可以运用一些技巧……如果你定义了一个传统类,并且设置它的__metaclass__=type,其实你是在将它升级为一个新风格的类!)
在执行类定义的时候,将检查此类正确的(一般是默认的)元类,元类(通常)传递三个参数(到构造器):类名、从基类继承数据的元组和(类的)属性字典。
3.谁在用元类
元类这样的话题对大多数人来说属于理论化或纯面向对象思想的范畴,认为它在实际编程中没有什么实际意义。从某种意义上讲这种想法是正确的;但最重要的请铭记在心的是,元类的最终使用者不是用户,正是程序员自己。你通过定义一个元类来“迫使”程序员按照某种方式实现目标类,这将既可以简化他们的工作,也可以使所编写的程序更符合特定标准。
4.元类何时被创建
前面我们已提到创建的元类用于改变类的默认行为和创建方式。大多数Python用户都无须创建或明确地使用元类。创建一个新风格的类或传统类的通用做法是使用系统自己所提供的元类的默认方式。
用户一般都不会觉察到元类所提供的创建类(或元类实例化)的默认模板方式。虽然一般我们并不创建元类,还是让我们来看下面一个简单的例子(关于更多这方面的示例请参见本节末尾的文档列表)。
元类示例1
我们第一个关于元类的示例非常简单(希望如此)。它只是在用元类创建一个类时,显示时间标签(你现在该知道,这发生在类被创建的时候)。
看下面这个脚本。它包含的print语句散落在代码各个地方,便于我们了解所发生的事情:

当我们执行此脚本时,将得到以下输出:

DONE
当你明白了一个类的定义其实是在完成某些工作的事实以后,你就容易理解这是怎么一回事情了。
元类示例2
在第二个示例中,我们将创建一个元类,要求程序员在他们写的类中提供一个__str__()方法的实现,这样用户就可以看到比我们在本章前面所见到的一般Python对象字符串(<object object at id>)更有用的信息。
如果你还没有在类中覆盖__repr__()方法,元类会(强烈)提示你这么做,但这只是个警告。如果未实现__str__()方法,将引发一个TypeError的异常,要求用户编写一个同名方法。以下是关于元类的代码:

我们编写了三个关于元类的示例,其中一个(Foo)重载了特殊方法__str__()和__repr__(),另一个(Bar)只实现了特殊方法__str__(),还有一个(FooBar)没有实现__str__()和__repr__(),这种情况是错误的。完整的程序见示例13.10。
执行此脚本,我们得到如下输出:


例13.10 将直线的两个端点元类示例(meta.py)
这个模块有一个元类和三个受此元类限定的类。每创建一个类,将打印一条输出语句。


注意我们是如何成功声明Foo定义的;定义Bar时,提示警告__repr__()未实现;FooBar的创建没有通过安全检查,以致程序最后没有打印出关于FooBar的语句。另外要注意的是我们并没有创建任何测试类的实例……这些甚至根本不包括在我们的设计中。但别忘了这些类本身就是我们自己的元类的实例。这个示例只显示了元类强大功能的一方面。
关于元类的在线文档众多,包括Python文档PEPs 252和PEPs 253,“What’s New in Python 2.2”文档,名为”Unifying Types and Classes in Python 2.2”的文章。在Python 2.2.3发布的主页上你也可以找到相关文档的链接地址。
13.17 相关模块和文档
我们在本章已经对核心语言做了讲述,而Python语言中有几个扩展了核心语言功能的经典类。这些类为Python数据类型的子类化提供了方便。
User*模块好比速食品,方便即食。我们曾提到类可以有特殊的方法,如果实现了这些特殊方法,就可以对类进行定制,这样当对一个标准类型封装时,可以给实例带来和类型一样的使用效果。
UserList和UserDict,还有新的UserString(从Python1.6版本开始引入)分别代表对列表、字典、字符串对象进行封装的类定义模块。这些模块的主要用处是提供给用户所需要的功能,这样你就不必自己动手去实现它们了,同时还可以作为基类,提供子类化和进一步定制的功能。Python语言已经为我们提供了大量有用的内建类型,但这种“由你自己定制”类型的附加功能使得Python语言更加强大。
在第4章里,我们介绍了Python语言的标准类型和其他内建类型。types模块是进一步学习Python类型方面知识的好地方,其中的一些内容已超出了本书的讨论范围。types模块还定义了一些可以用于进行比较操作的类型对象(这种比较操作在Python中很常见,因为它不支持方法的重载——这简化的语言本身,同时又提供了一些工具,为看似欠缺的地方添加功能)。
下面的代码检查传递到foo函数的数据对象是否是一个整型或一个字符串,不允许其他类型出现(否则会引发一个异常):

最后一个相关模块是operator模块。这个模块提供了Python中大多数标准操作符的函数版本。在某些情况下,这种接口类型比标准操作符的硬编码方式更通用。
请看下边的示例。在你阅读代码时,请设想一下如果此实现中使用的是一个个操作符的话,那会多写多少行代码啊?


上面这段代码定义了三个向量,前两个包含着操作数,最后一个代表程序员打算对两个操作数进行的一系列操作。最外层循环遍历每个操作运算,而最内层的两个循环用每个操作数向量中的元素组成各种可能的有序数据对。最后,print语句打印出将当前操作符应用在给定参数上所得的运算结果。
我们前面介绍过的模块都列在表13.5中。

在《Python FAQ》中,有许多与类和面向对象编程有关的问题。它对Python类库以及《Python语言参考手册》都是很好的补充材料。关于新风格的类,请参考PEP 252、PEP 253和Python2.2以后的相关文档。
13.18 练习
13-1.程序设计。请列举一些面向对象编程与传统旧的程序设计形式相比的先进之处。
13-2.函数和方法的比较。函数和方法之间的区别是什么?
13-3.对类进行定制。写一个类,用来将浮点型值转换为金额。在本练习里,我们使用美国货币,但读者也可以自选任意货币。
基本任务:编写一个dollarize()函数,它以一个浮点型值作为输入,返回一个字符串形式的金额数。比如说:
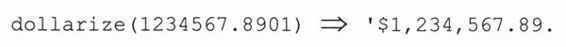
dollarize()返回的金额数里应该允许有逗号(比如1,000,000)和美元的货币符号。如果有负号,它必须出现在美元符号的左边。完成这项工作后,你就可以把它转换成一个有用的类,名为MoneyFmt。
MoneyFmt类里只有一个数据值(即金额),和5个方法(你可以随意编写其他方法)。__init__()构造器对数据进行初始化,update()方法把数据值替换成一个新值,__nonzero__()是布尔型的,当数据值非零时返回True,__repr__()方法以浮点型的形式返回金额;而__str__()方法采用和dollarize()一样的字符格式显示该值。
(a)编写update()方法,以实现数据值的修改功能。
(b)以你已经编写的dollarize()的代码为基础,编写__str__()方法的代码。
(c)纠正__nonzero__()方法中的错误,这个错误认为所有小于1的数值,例如,50美分($0.50),返回假值(False)。
(d)附加题:允许用户通过一个可选参数指定是把负数数值显示在一对尖括号里还是显示一个负号。默认参数是使用标准的负号。
13-4.用户注册。建立一个用户数据库(包括登录名、密码和上次登录时间戳)类(参考练习7-5和练习9-12),来管理一个系统,该系统要求用户在登录后才能访问某些资源。这个数据库类对用户进行管理,并在实例化操作时加载之前保存的用户信息,提供访问函数来添加或更新数据库的信息。在数据修改后,数据库会在垃圾回收时将新信息保存到磁盘(参见__del__())。
13-5.几何。创建一个由有序数值对(x, y)组成的Point类,它代表某个点的X坐标和Y坐标。X坐标和Y坐标在实例化时被传递给构造器,如果没有给出它们的值,则默认为坐标的原点。
13-6.几何。创建一个直线/直线段类。除主要的数据属性:一对坐标值(参见上一个练习)外,它还具有长度和斜线属性。你需要覆盖__repr__()方法(如果需要的话,还有__str__()方法),使得代表那条直线(或直线段)的字符串表示形式是由一对元组构成的元组,即((x1,y1)、(x2,y2))。总结:
__repr__ 将直线的两个端点(始点和止点)显示成一对元组。
length 返回直线段的长度-不要使用“len”,因为这样使人误解它是整型。
slope 返回此直线段的斜率(或在适当的时候返回None)
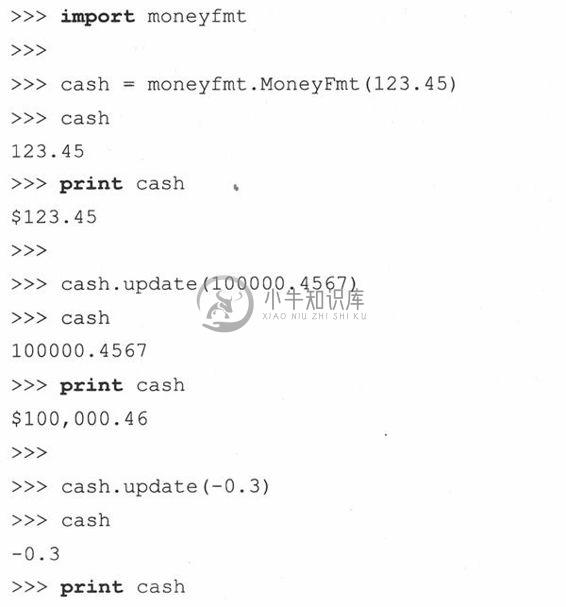
例13.11 金额转换程序(moneyfmt.py)
字符串格式类用来对浮点型值进行“打包”,使这个数值显示为带有正确符号的金额。


金额转换程序(moneyfmt.py)的主要代码如例13.11所示。网站上有带有充分文件证明(尚不完善)的版本moneyfmt.py。如果我们引入解释程序中的完整类,执行过程将和下面类似:

13-7.数据类。提供一个time模块的接口,允许用户按照自己给定时间的格式,比如:“MM/DD/YY”、“MM/DD/YYYY”、“DD/MM/YY”、“DD/MM/YYYY”、“Mon DD,YYYY”,或是标准的Unix日期格式、“Day Mon DD,HH:MM:SS YYYY”来查看日期。你的类应该维护一个日期值,并用给定的时间创建一个实例。如果没有给出时间值,程序执行时会默认采用当前的系统时间。还包括另外一些方法。

如果没有提供任何时间格式,默认使用系统时间或ctime()的格式。附加题:把这个类和练习6-15结合起来。
13-8.堆栈类。一个堆栈(Stack)是一种具有后进先出(last-in-first-out, LIFO)特性的数据结构。我们可以把它想象成一个餐盘架。最先放上去的盘子将是最后一个取下来的,而最后一个放上去的盘子是最先被取下来的。你的类中应该有push()方法(向堆栈中压入一个数据项)和pop()方法(从堆栈中移出一个数据项)。还有一个叫isempty()的布尔方法,如果堆栈是空的,返回布尔值1,否则返回0;一个名叫peek()的方法,取出堆栈顶部的数据项,但并不移除它。注意,如果你使用一个列表来实现堆栈,那么pop()方法从Pythonl.5.2版本起已经存在了。那就在你编写的新类里,加上一段代码检查pop()方法是否已经存在。如果经检查pop()方法存在,就调用这个内建的方法;否则就执行你自己编写的pop()方法。你很可能要用到列表对象;如果用到它时,不需要担心实现列表的功能(例如切片)。只要确保你写的堆栈类能够正确实现上面的两项功能就可以了。你可以用列表对象的子类或自己写个类似列表的对象,请参考例6.2。
13-9.队列类。一个队列(queue)是一种具有先进先出(first-in-first-out, FIFO)特性的数据结构。一个队列就像是一行队伍,数据从前端被移除,从后端被加入。这个类必须支持下面几种方法:
enqueue() 在列表的尾部加入一个新的元素。
dequeue() 在列表的头部取出一个元素,返回它并且把它从列表中删除。
请参见上面的练习和示例6.3。
13-10.堆栈和队列。编写一个类,定义一个能够同时具有堆栈(FIFO)和队列(LIFO)操作行为的数据结构。这个类和Perl语言中数组相像。需要实现四个方法:
shift() 返回并删除列表中的第一个元素,类似于前面的dequeue()函数。
unshift() 在列表的头部“压入”一个新元素。
push() 在列表的尾部加上一个新元素,类似于前面的enqueue()和push()方法。
pop() 返回并删除列表中的最后一个元素,与前面的pop()方法完全一样。
请参见练习13-8和练习13-9。
13-11.电子商务。
你需要为一家B2C(企业到消费者)零售商编写一个基础的电子商务引擎。你需要写一个针对顾客的类User,一个对应存货清单的类Item,还有一个对应购物车的类叫Cart。货物放到购物车里,顾客可以有多个购物车。同时购物车里可以有多个货物,包括多个同样的货物。
13-12.聊天室。你对目前的聊天室程序感到非常失望,并决心要自己写一个,创建一家新的因特网公司,获得风险投资,把广告集成到你的聊天室程序中,争取在六个月的时间里让收入翻五倍,股票上市,然后退休。但是,如果你没有一个非常酷的聊天软件,这一切都不会发生。你需要三个类:一个Message类,它包含一个消息字符串以及诸如广播、单方收件人等其他信息,一个User类,包含了进入你聊天室的某个人的所有信息。为了从风险投资者那里拿到启动资金,你加了一个Room类,它体现了一个更加复杂的聊天系统,用户可以在聊天时创建单独的“房间”,并邀请其他人加入。附加题:请为用户开发一个图廀¢化用户界面应用程序。
13-13.股票投资组合类。你的数据库中记录了每个公司的名字、股票代号、购买日期、购买价格和持股数量。需要编写的方法包括:添加新代号(新买的股票)、删除代号(所有卖出股票),根据当前价格(及日期)计算出的YTD或年回报率。请参见练习7-6。
13-14.DOS。为DOS机器编写一个Unix操作界面的shell。你向用户提供一个命令行,使得用户可以在那里输入Unix命令,你可以对这些命令进行解释,并返回相应的输出,例如:“ls”命令调用“dir”来显示一个目录中的文件列表,“more”调用同名命令(分页显示一个文件),“cat”调用“type”,“cp”调用“copy”,“mv”调用“ren”,“rm”调用“del”,等。
13-15.授权。示例13.8的执行结果表明我们的类CapOpen能成功完成数据的写入操作。在我们的最后评论中,提到可以使用CapOpen()或open()来读取文件中的文本。为什么呢?这两者使用起来有什么差异吗?
13-16.授权和函数编程。
(a)请为示例13.8中的CapOpen类编写一个writelinesO方法。这个新函数将可以一次读入多行文本,然后将文本数据转换成大写的形式,它与write()方法的区别和通常意思上的writelinesO与write()方法之间的区别相似。注意:编写完这个方法后,writelinesO将不再由文件对象“代理”。
(b)在writelines()方法中添加一个参数,用这个参数来指明是否需要为每行文本加上一个换行符。此参数的默认值是False,表示不加换行符。
13-17.数值类型子类化。在示例13.3中所看到的moneyfmt.py脚本基础上修改它,使得它可以扩展Python的浮点类型。请确保它支持所有操作,而且是不可变的。
13-18.序列类型子类化。模仿前面练习13-4中的用户注册类的解决方案,编写一个子类。要求允许用户修改密码,但密码的有效期限是12个月,过期后不能重复使用。附加题:支持“相似密码”检测的功能(任何算法皆可),不允许用户使用与之前12个月期间所使用的密码相似的任何密码。
13-19.映射类型子类化。假设在13.11.3节中字典的子类,若将keys()方法重写为:

(a)当方法keys()被调用,结果如何?
(b)为什么会有这样的结果?如何使我们的原解决方案顺利工作?
13-20.类的定制。改进脚本time60.py,见13.13.2节示例13.3。
(a)允许“空”实例化:如果小时和分钟的值没有给出,默认为零小时、零分钟。
(b)用零占位组成两位数的表示形式,因为当前的时间格式不符合要求。如下面的示例,wed应该输出为“12:05”。

(c)除了用hours(hr)和minutes (min)进行初始化外,还支持以下时间输入格式:
一个由小时和分钟组成的元组(10,30);
一个由小时和分钟组成的字典({‘hr’:10,‘min’:30});
一个代表小时和分钟的字符串(“10:30”)。
附加题:允许不恰当的时间字符串表示形式,如“12:5”。
(d)我们是否需要实现__radd__()方法?为什么?如果不必实现此方法,那我们什么时候可以或应该覆盖它?
(e) __repr__()函数的实现是有缺陷而且被误导的。我们只是重载了此函数,这样我们可以省去使用print语句的麻烦,使它在解释器中很好的显示出来。但是,这个违背了一个原则:对于可估值的Python表达式,repr()总是应该给出一个(有效的)字符串表示形式。12:05本身不是一个合法的Python表达式,但Time60(‘12:05’)是合法的。请实现它。
(f)添加六十进制(基数是60)的运算功能。下面示例中的输出应该是19:15,而不是18:75:

13-21.装饰符和函数调用语法。第13.16.4节末尾,我们使用过一个装饰函数符把x转化成一个属性对象,但由于装饰符是Python2.4才有的新功能,我们给出了另一个适用于旧版本的语法:

执行这个赋值语句时到底发生了什么呢?为什么它和使用装饰符语句是等价的?
[1]. “sexagesimal”是源自拉丁语的名字;有时我们也说”hexagesimal”,这是一个希腊词根”hexe”和拉丁语“gesmal”的混合。
[2]. Python2.3中新增。
[3]. Python2.4中新增。