
第21章 数据库编程
本章主题
♦ 介绍
♦ 数据库和Python,以及Python的RDBMS、ORM
♦ 数据库应用程序程序员接口(DB-API)
♦ 关系型数据库(RDBM)
♦ 对象-关系管理器(ORM)
♦ 相关模块
♦ 练习
本章的主题是如何通过Python访问数据库。前面我们已经了解了简单持久存储,但是在更多场合下,我们的应用程序需要的是一个功能齐全的关系型数据库(Relational Database Management System,RDBMS)。
21.1 介绍
21.1.1 持久存储
在任何的应用程序中,都需要持久存储。一般说来,有三种基本的存储机制:文件、关系型数据库或其他的一些变种,例如现有系统的API、ORM、文件管理器、电子表格、配置文件等。
在前面的章节中,我们研究了通过基于常规文件的Python和DBM接口来实现持久存储、比如*dbm、dbhas/bsddb文件、helve (pickle和DBM的结合)。这些接口都提供了类似字典的对象接口。本章的主题是如何在中大型项目中使用关系型数据库(对这些项目而言,那些接口力不从心)。
21.1.2 基本的数据库操作和SQL语言
在深入主题之前,下面先简单介绍一下基本的数据库概念和结构化查询语言(Structured QueryLanguage, SQL)。如果你有足够的经验,可以跳过,也可以通过阅读正文来复习一下。
1.底层存储
数据库的底层存储通常使用文件系统,它可以是普通操作系统文件、专用操作系统文件,甚至有可能是磁盘分区。
2.用户界面
大部分的数据库系统会提供一个命令行工具来执行SQL命令和查询,当然也有一些使用图形界面的漂漂亮亮的客户端程序来干同样的事。
3.数据库
关系型数据库管理系统通常通常都支持多个数据库,例如销售库、市场库、客户支持库等。如果你使用的关系数据库管理系统是基于服务器的,这些数据库就都在同一台服务器上(一些简单的关系型数据库没有服务器,如sqlite)。本章的例子中,MySQL是一种基于服务器的关系数据库管理系统(只要服务器在运行,它就一直在等待运行指令),SQLite和Gadfly则是另一种轻量型的基于文件的关系数据库(它们没有服务器)。
4.组件
你可以将数据库存储想像为一个表格,每行数据都有一个或多个字段对应着数据库中的列。每个表每个列及其数据类型的集合构成数据库结构的定义。数据库能够被创建,也可以被删除,表也一样。往数据库里增加一条记录称为插入(inserting),修改库中一条已有的记录则称为更新(updating).,删除表中已经有的数据行称为删除(deleting)。这些操作通常作为数据库操作命令来提交。从一个数据库中请求符合条件的数据称为查询(querying)。当你对一个数据库进行查询时,你可以一步取回所有符合条件的数据,也可以循环逐条取出每一行。有些数据库使用游标的概念来表示SQL命令、查询、取回结果集等。
5. SQL
数据库命令和查询操作需要通过SQL语句来执行,不是所有的数据库都使用SQL,但所有主流的关系型数据库都使用SQL。下面是一些SQL命令的例子,绝大多数数据库被配置为大小写不敏感,除了数据库操作命令以外。被广为接受的书写SQL的基本风格是关键字大写。绝大多数命令行程序要求用一个分号来结束一条SQL语句。
(1)创建数据库

第一行创建一个名为”test”的数据库,第二行将该数据库的权限赋给具体用户(或者全部用户),以便它们可以执行下面的数据库操作。
(2)选择要使用的数据库
USE test;

如果在登录数据库时没有指定要使用那个数据库,这条简单的语句就可以指定你打算访问的数据库。
(3)删除数据库

这条短短的语句具有极大的威力,它用来删除数据库(包括数据库中所有的表及表中的数据)。在输入完这条语句按下回车之前,好好想想你是否真的打算这么做。
(4)创建表

这个语句用于创建表users,它有一个类型为字符串的列login和两个类型为整型的字段uid和prid。
(5)删除表

这个简单的语句删除数据库中的一个表和它的所有数据。
(6)插入行
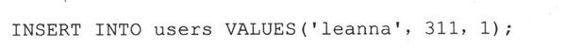
INSERT语句用来向数据库中添加新的数据行。语句中必须指定要插入的表及该表中各个字段的值。上例中,表名是users,字符串’leanna’对应着login字段,311和1分别对应着uid和prid。
(7)更新行

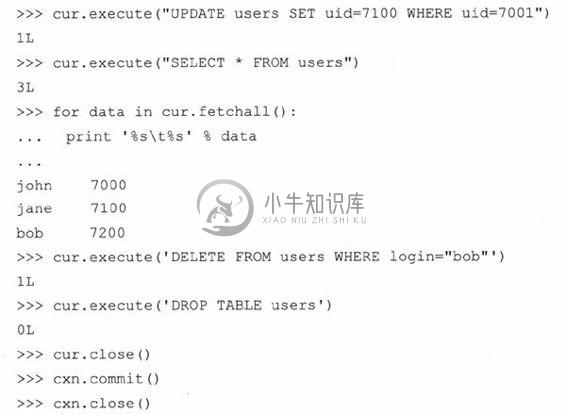
UPDATE语句用来改变数据库中的已有记录。使用SET关键字来指定你要修改的字段及新值,你可以指定条件来筛选出需要更新的记录。在第一个例子中,所有prid字段值为2的记录,其prid字段的值都变更为4。在第二个例子里,uid字段值为311的用户,其prid字段的新值被置为1。
(8)删除行

DELETE FROM命令用来删除数据。必须指定你要删除的数据所在表名,如果未提供(可选的)筛选条件,就像第二个例子一样,表中所有的数据都会被删除。
现在你已经了解数据库的基本概念,有了这些基础,本章余下的部分学起来会更加容易。如果需要进一步了解数据库知识,市面上有数不清的数据库书籍可供选择。
21.1.3 数据库和Python
下面我们要详细了解Python数据库API。Python能够直接通过数据库接口,也可以通过ORM(不需要自己书写SQL)来访问关系数据库。
关于数据库原理、并发能力、视图、原子性、数据完整性、数据可恢复性、左连接、触发器、查询优化、事务支持及存储过程等主题,(市面上)有数不清的资源可供参考。本章不讨论这些主题,我们将从一个Python应用程序开始,了解在Python框架下如何将数据保存到数据库,如何将数据从数据库中取出来。之后你就可以决定哪种方式适用于你手头的项目。通过学习示例代码,你可以立刻动手把某种数据库整合到你的Python应用程序当中。
在Python世界里,无需怀疑,与数据库协同工作已经几乎是所有应用程序的核心部分了。在本章中,我们将不仅仅使用”万能”的Python标准库,尽管我们需要从标准库开始。
作为一个软件工程师,在你的职业生涯中,你可能永远不需要学习数据库知识:如何使用命令行工具、如何使用SQL、如何添加和更新数据等。但是如果Python是你的编程工具,那么为你的Python应用添加数据库支持会让它事半功倍。下面我们先来介绍一下Python的DB-API,然后给出使用这个标准的例子。
我们的例子会使用开源的数据库系统。不过我们不会去讨论是开源产品还是商业产品更好。要适应其他的数据库也相当容易,需要特别提到的是亚伦·沃特(Aaron Watter)的Gadfly数据库,一个完全由Python代码写成的数据库系统。
从Python中访问数据库需要接口程序,接口程序是一个Python模块,它提供数据库客户端库(通常是C语言写成的)的接口供你访问。需要提到一点,所有Python接口程序都一定程度上遵守PythonDB-API规范,这也是本章的第一个主要主题。
图21-1演绎了Python数据库应用程序的结构(包括使用和不使用ORM)。你可以看到DB-API是数据库客户端C库的接口。

图 21-1 数据库和应用程序之间的多层通讯
第一个框中一般是C/C++程序,你的程序通过DB-API兼容接口程序访问数据库。
ORM通过程序处理数据库细节来简化数据库开发。
21.2 Python数据库应用程序程序员接口(DB-API)
去哪儿找一个合适的接口访问数据库?很简单,去python.org找到数据库主题那一节,你会发现所有支持DB-API 2.0的各种数据库模块、文档、SIG等。从那时起,DB-API被移到PEP 249中(这个PEP废弃了老的DB-API 1.0,也就是PEP248标准)。那么,什么是DB-API?
DB-API是一个规范。它定义了一系列必需的对象和数据库存取方式,以便为各种各样的底层数据库系统和多种多样的数据库接口程序提供一致的访问接口。像绝大多数社区成果一样,这个API的产生来自于强烈的需求。
在过去,不同的人为各种各样的数据库实现了各种各样的数据库接口程序。同一个轮子被不同的人一遍又一遍地重复发明。这些接口由不同的人在不同的时间实现,功能接口各不兼容,这意味着使用这些接口的程序必须自定义他们选择的接口模块。当这个接口模块变化时,应用程序的代码也必须随之更新。
一个处理Python数据库事务的特殊事物小组(special interest group, SIG)因此诞生,最后DB-API1.0问世。DB-API为不同的数据库提供了一致的访问接口,在不同的数据库之间移植代码成为一件轻松的事情(一般来说,只修要修改几行代码)。接下来你会看到这样的例子。
21.2.1 模块属性
DB-API规范里的以下特性和属性必须提供。一个DB-API兼容的模块必须定义如下,表21.1中定义的所有全局属性。
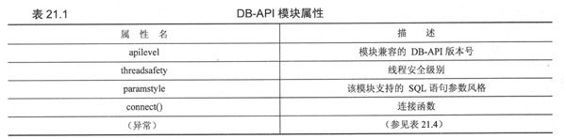
1.数据属性
(1) apilevel
apilevel这个字符串(不是浮点型)表示这个DB-API模块所兼容的DB-API最高版本号。如“1.0”,“2.0”等。如果未定义,则默认是“1.0”。
(2) Threadsafety
这是一个整型,取值范围如下:
0:不支持线程安全,多个线程不能共享此模块
1:初级线程安全支持:线程可以共享模块,但不能共享连接
2:中级线程安全支持:线程可以共享模块和连接,但不能共享游标
3:完全线程安全支持:线程可以共享模块、连接及游标
如果一个资源被共享,就必需使用自旋锁或者是信号量这样的同步原语对其进行原子目标锁定。对这个目标来说,磁盘文件和全局变量都不可靠,并且有可能妨碍mutex(互斥量)的操作。请参阅threading模块或第16章(多线程编程)来了解如何使用锁。
(3) Paramstyle
DB-API支持多种方式的SQL参数风格。这个参数是一个字符串,表明SQL语句中字符串替代的方式。(参阅表21.2)

2.函数属性
connect方法生成一个connect对象,我们通过这个对象来访问数据库。符合标准的模块都会实现connect方法。表21.3列出了connect()函数的参数。
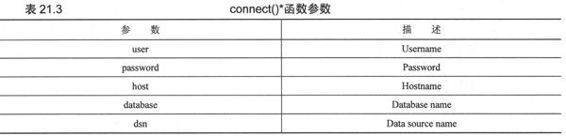
数据库连接参数可以以一个DSN字符串的形式提供,也可以以多个位置相关参数的形式提供(如果你明确知道参数的顺序的话),也可以以关键字参数的形式提供。下面是一个来自PEP 249的使用connect()的例子:

使用DSN字符串还是独立参数?这要看你连接的是哪种数据库。举例来说,如果你使用类似ODBC或JDBC的API,你就应该使用DSN字符串。如果你直接访问数据库,你就会更倾向于使用独立参数。另一个使用独立参数的原因是,很多数据库接口程序还不支持DSN参数。下面是一个非DSN的例子。
connect()调用。注意不是所有的接口程序都是严格按照规范实现的。MySQLdb就使用了db参数而不是规范推荐的database参数来表示要访问的数据库。

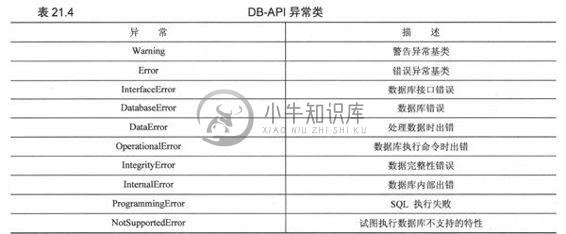
3.异常
兼容标准的模块也应该提供这些异常类。见表21.4。表21.4 DB-API异常类
21.2.2 连接对象
要与数据库进行通信,必须先和数据库建立连接。连接对象处理将命令送往服务器,以及从服务器接收数据等基础功能。连接(或一个连接池)成功后你就能够向数据库服务器发送请求,得到响应。
方法
连接对象没有必须定义的数据属性,但是它至少应该定义表21.5中的这些方法。

一旦执行了close()方法,再试图使用连接对象的方法将会导致异常。
对不支持事务的数据库,或者虽然支持事务但设置了自动提交(auto-commit)的数据库系统来说,commit()方法什么也不做。如果你确实需要,可以实现一个自定义方法来关闭自动提交行为。由于DB-API要求必须实现此方法,所以对那些没有事务概念的数据库来说,这个方法只需要有一条pass语句就可以了。
类似commit()、rollback()方法仅对支持事务的数据库有意义。执行完rollback(),数据库将恢复到提交事务前的状态。根据PEP249,在提交commit()之前关闭数据库连接将会自动调用rollback()方法。
对不支持游标的数据库来说,cursor()方法仍然会返回一个尽量模仿游标对象的对象。这是最低要求。特定数据库接口程序的开发者可以任意为他们的接口程序添加额外的属性,只要他们愿意。
DB-API规范建议但不强制接口程序的开发者为所有数据库接口模块编写异常类。如果没有提供异常类,则假定该连接对象会引发一致的模块级异常。一旦你完成了数据库连接,并且关闭了游标对象,你应该执行commit()提交你的操作,然后关闭这个连接。
21.2.3 游标对象
当你建立连接之后,就可以与数据库进行交互。就像我们在前一小节提到的,一个游标允许用户执行数据库命令和得到查询结果。一个Python DB-API游标对象总是扮演游标的角色,无论数据库是否真正支持游标。从这一点讲,数据库接口程序必须实现游标对象。只有这样,才能保证无论使用何种后端数据库你的代码都不需要做任何改变。
创建游标对象之后,你就可以执行查询或其他命令(或者多个查询和多个命令),也可以从结果集中取出一条或多条记录。表21.6列举了游标对象拥有的属性和方法。
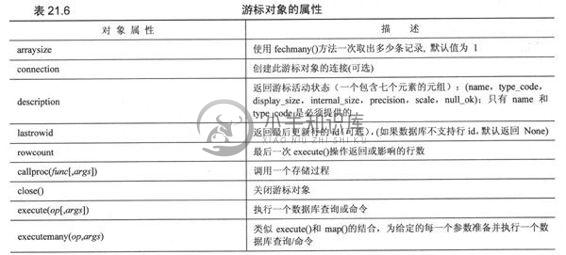
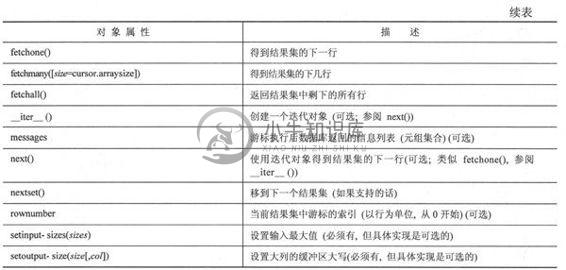
游标对象最重要的属性是execute*()和fetch*()方法。所有对数据库服务器的请求都由它们来完成。对fetchmany()方法来说,设置一个合理的arraysize属性会很有用。当然,在不需要时关掉游标对象也是个好主意。如果你的数据库支持存储过程,你就可以使用callproc()方法。
21.2.4 类型对象和构造器
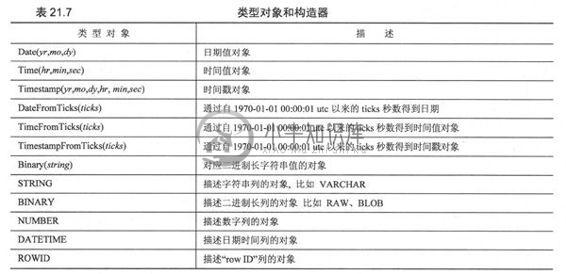
通常两个不同系统的接口要求的参数类型是不一致的,譬如Python调用C函数时Python对象和C类型之间就需要数据格式的转换,反之亦然。类似地,在Python对象和原生数据库对象之间也是如此。对于Python DB-API的开发者来说,你传递给数据库的参数是字符串形式的,但数据库会根据需要将它转换为多种不同的形式。以确保每次查询能被正确执行。
举例来说,一个Python字符串可能被转换为一个VARCHAR或一个TEXT,或一个BLOB,或一个原生BINARY对象,或一个DATE或TIME对象。一个字符串到底会被转换成什么类型?必须小心地尽可能以数据库期望的数据类型来提供输入,因此另一个DB-API的需求是创建一个构造器以生成特殊的对象,以便能够方便地将Python对象转换为合适的数据库对象。表21.7描述了可以用于此目的的类。SQL的NULL值被映射为Pyhton的NULL对象,也就是None。
DB-API版本变更
有几个重要的变更发生在DB-API从1.0(1996)升级到2.0(1999)时:
从API中移除了原来必须的dbi模块;
更新了类型对象;
增加了新的属性以提供更易用的数据库绑定;
变更了callproc()的语义并重定义了execute()的返回值;
基于异常的错误处理。
自从DB-API 2.0发布以来,曾经在2002年加入了一些可选的DB-API扩展,但一直没有什么重大的变更。在DB-SIG邮件列表中一直在讨论DB-API的未来版本——暂时命名为DB-API 3.0。它将包括以下特性:
当有一个新的结果集时nextset()会有一个更合适的返回值;
float变更为Decimal;
支持更灵活的参数风格;
预备语句或语句缓存;
优化事务模型;
确定DB-API可移值性的角色;
增加单元测试。
如果你对这些API特别感兴趣,欢迎积极参与。下面有一些手边的资源。
21.2.5 关系数据库
现在我们准备开始,一个问题摆在面前,在Pyhton里我可以使用哪种数据库接口?换言之,Python支持哪些平台?答案是几乎所有的平台。下面是一个不怎么完整的数据库支持列表。
商业关系数据库管理系统
Informix;
Sybase;
Oracle;
MS SQL Server;
DB/2;
SAP;
Interbase;
Ingres。
开源关系数据库管理系统
MySQL;
PostgreSQL;
SQLite;
Gadfly。
数据库API
JDBC;
ODBC。
想要了解Python都支持哪些数据库,请参阅下面网址:
http://python.org/topics/database/modules.html
21.2.6 数据库和Python:接口程序
对每一种支持的数据库,都有一个或多个Python接口程序允许你连接到目标数据库系统。某些数据库,比如Sybase、SAP、Oracle和SQLServer,都有两个或更多个接口程序可供选择。你要做的就是挑选一个最能满足你需求的接口程序。你挑选接口程序的标准可以是,性能如何、文档或WEB站点的质量如何、是否有一个活跃的用户或开发社区、接口程序的质量和稳定性如何等。记住绝大多数接口程序只提供基本的连接功能,你可能需要一些额外的特性。高级应用代码,如线程和线程管理及数据库连接池的管理等,需要你自己来完成。
如果你不想处理这些,比方说你不喜欢自己写SQL,也不想参与数据库管理的细节——那么本章后面讲到的ORM (Object-Relational Mappers,对象-关系管理器)应该可以满足你的要求。现在来看一些使用接口程序访问数据库的例子,关键之处在于设置数据库连接。在建立连接之后,不管后端是何种数据库,对DB-API对象的属性和方法进行操作都是一样的。
21.2.7 使用数据库接口程序举例
首先,我们来看一下例子代码:创建数据库、创建表、使用表。我们分别提供了使用MySQL、PostgreSQL和SQLite的例子。
1. MySQL
这里我们以MySQL数据库为例,使用唯一的MySQL接口程序MySQLdb,这个接口程序又名MySQL-python。在这部分代码里,我们故意在例子里埋下一个错误。
首先我们以管理员身份登录,创建一个数据库,并赋予相应权限,之后我们再以普通用户身份登录数据库,以便你能了解你希望得到什么,这样你会想到为它创建一个事件处理程序。

在上面的代码中,我们没有使用cursor对象。某些(但不是所有的)接口程序拥有连接对象,这些连接对象拥有query()方法,可以执行SQL查询。我们建议你不要使用这个方法,或者事先检查该方法在当前接口程序当中是否可用。之后我们以普通用户身份再次连接这个新数据,创建表,然后通过Python执行SQL查询和命令,来完成我们的工作。这次我们使用游标对象(cursors)和它们的execute()方法,下一个交互集演示了创建表。
下面的代码演示了如何创建一个表。在删除一个表之前如果试图重建这个表将产生错误。

现在我们来插入几行数据到数据库,然后再将它们取出来。
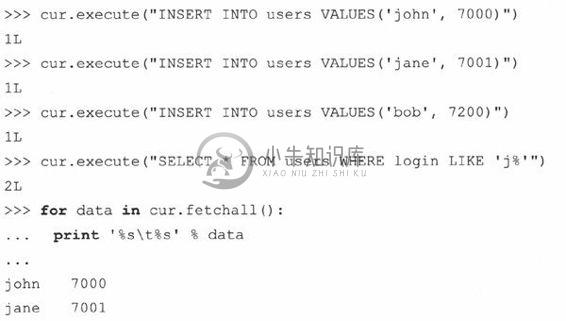
最后一个特性是更新表,包括更新或删除数据。
MySQL是最流行的开源数据库之一。毫无疑问会有一个针对MySQL的Python接口程序。不过Python标准库中并没有集成这个接口程序,这是一个第三方包,你需要单独下载并安装它。在本章末尾的索引页,你可以找到如何下载它。
2. PostgreSQL
另一个著名的开源数据库是PostgreSQL。与MySQL不同,有至少3个Python接口程序可以访问PosgreSQL: psycopg, PyPgSQL和PyGreSQL,第四个,PoPy,现在已经被废弃(2003年,它贡献出自己的代码,与PygreSQL整合在一起)。这三个接口程序各有长处,各有缺点,根据实践结果来选择使用哪个接口更为明智。
多亏他们都支持DB-API,所以他们的接口基本一致,你只需要写一个应用程序,然后分别测试这三个接口的性能(如果性能对你的程序很重要的话)。下面我给出这三个接口的连接代码:


好,下面的代码就能够在所有接口程序下工作了。

最后,你会发现他们的输出有一点点轻微的不同。

3. SQLite
对非常简单的应用来说,使用文件进行持久存储通常就足够了。但对于绝大多数数据驱动的应用程序必须使用全功能的关系数据库。SQLite介于二者之间,它定位于中小规模的应用。它是相当轻量级的全功能关系型数据库,速度很快,几乎不用配置,并且不需要服务器。
SQLite正在迅速流行起来。并且在各个平台上都能用。Python2.5中就集成了前面介绍的pysqlite数据库接口程序,作为Python2.5的sqlite3模块。这是Python第一次将一个数据库接口程序纳入标准库,也许这标志着一个新的开始。
它被打包到Python当中并不是因为他比其他的数据库接口程序更优秀,而是因为他足够简单,使用文件(或内存)作为它的后端存储,就像DBM模块做的那样,不需要服务器,而且也不存在授权问题。它是Python中其他的持久存储解决方案的一个替代品,一个拥有SQL访问界面的优秀替代品。在标准库中有这么一个模块,就能方便用户使用Python和SQLite进行软件开发,等到软件产品正式上市发布时,只要有需要,就能够很容易的将产品使用的数据库后端变更为一个全功能的、更强大的类似MySQL、PostgreSQL、Oracle或SQL Server那样的数据库。当然,对那些不需要那么大马力的应用程序来说,SQLite已经足够使用。
尽管标准库已经提供了数据库接口程序,你仍然需要自己下载真正的数据库软件。一旦安装好之后,你就只需要打开Python解释器,下面是一个例子:
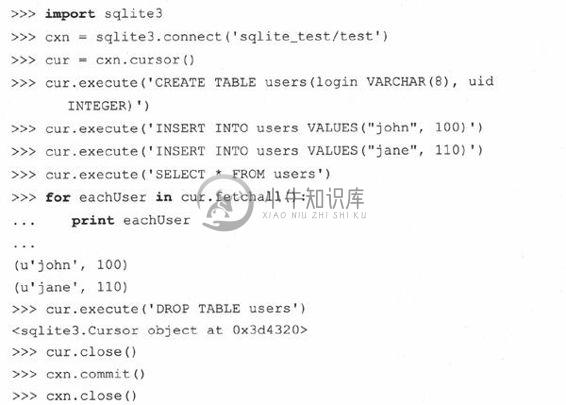
OK,这个小例子已经足够了。接下来,我们来看一个小程序,它类似前面使用MySQL的例子,但完成几种新的功能:
创建一个数据库(如果必要)
创建一个表
在表中插入行
在表中更新行
在表中删除行
删除表
这个例子中,我们仍然使用两个其他的开源数据库。SQLite现如今已经相当流行。它体积小,而且足够快,是一个拥有几乎全部功能的相当轻量级的数据库。这个例子中用到的另一个数据库是Gadfly,一个基本兼容SQL的纯Python写成的关系数据库。(某些关键的数据库结构有一个C模块,不过Gadfly没有它也一样可以运行(当然,会慢不少,嘿嘿))。
在进入代码之前,有几件事要提醒。SQLite和Gadfly需要用户指定保存数据库文件的位置(MySQL有一个默认区域保存数据,在使用MySQL数据库时无需指定这个)。另外,Gadfly目前的版本还不兼容DB-API 2.0,也就是说,它缺失一些功能,尤其是缺少我们例子中用到的cursor属性rowcount。
4.数据库接口程序应用程序举例
在下面这个例子里,我们演示了Python如何访问数据库。事实上,我们的程序支持三种不同的数据库系统:Gadfly、SQLite和MySQL。我们将要创建一个数据库(如果它不存在的话),然后进行多种数据库操作,比如创建表、删除表、插入数据、更新数据、删除数据等。在下一小节中的ORM中我们将重复例子21.1的这些功能。
5.逐行解释
第1 ~ 18行
脚本的第一部分导入必须的模块,创建一些”全局常量”(列的显示大小及我们的程序支持的数据库)。其中setup()函数提供一个简单界面让用户选择使用哪种数据库。
值得留意的是DB_EXC常量,它代表数据库异常。他最终的值由用户最终选择使用的数据库决定。也就是说,如果用户选择MySQL, DB_EXC将是_mysql_exceptions,依此类推。如果我们用流行的面向对象的方式来开发这个应用,它将会以一个实例属性的方式表示,比如self.db_exc_module或者什么别的名字。
第20 ~ 75行
这里的connect()函数表现了数据库存取一致性。在每一小节的开头,我们尝试载入需要的数据库模块。如果找不到合适的模块,None值被返回,表示这个数据库系统暂不支持。
在数据库连接建立以后,其余的代码对数据库和接口程序来说都是透明的(不区分哪种数据库、哪种接口程序,代码都可以工作)。有一个唯一的例外,就是脚本的insert()函数。在这部分代码的所有3小段中,数据库连接成功后会返回一个连接对象cxn。
如果选中了SQLite(24行~36行),我们尝试载入一个数据库接口程序。我们首先尝试载入标准库模块sqlite3(Python2.5及更高版本支持),如果载入失败,就会去寻找第三方pysqlite2包。这个包支持Python2.4.x或更老些的系统。
如果成功导入合适的接口程序,由于SQLite是基于文件的数据库系统,同我们需要确认一下数据库文件所在的目录是否存在(当然,你也可以选择在内存里创建一个数据库)。当调用connect()函数时,如果这个数据库文件已经存在,SQLite会使用这个数据库,如果文件不存,它就会创建一个新文件。
例21.1 数据库接口程序示例
这段脚本使用同样的接口对多种数据库执行了一些数据库基本操作。





MySQL(38~57行)的数据文件会存保在默认的数据存储区域,所以不需要用户指定存储位置。我们的代码尝试连接指定的数据库。如果发生错误,有可能是数据库不存在,或者虽然数据库存在但我们没有权限访问它。由于这仅仅是一个测试应用程序,我们选择完全先删掉这个数据库(忽略掉如果数据库不存在可能引发的错误),然后重建该库,然后给访问它的用户赋予权限。
我们的应用程序支持的最后一个数据库是Gadfly(第59~75行)。在本书写作的时候,这个数据库已经几乎但还没有完全兼容DB-API,你也会在这个程序里看到这一点。)它使用类似SQLite的启动机制:它的启动目录是数据文件所在的目录。如果数据文件在那儿,那没有问题,如果那儿没有数据文件,你必须重新启动一个新的数据库(为什么非要这样,我们也不十分清楚。我们认为startup()函数应该被合并到构造器函数gadfly.gadfly()当中去)。
77 ~ 89行
create()函数在数据库中创建一个新的users表,如果中间产生问题,几乎肯定是因为这个表已经存在。如果正是这个原因的话,删掉这个表,然后递归调用create()函数来重新创建它。这个代码有一个缺陷,就是当重建表仍然失败的话,你将陷入死循环,直至内存耗尽。在本章最后有一道习题就是这个问题,你可以试着修复这个潜在的bug。
91 ~ 103行
这可能是除了数据库操作之外最有趣的代码部分了。它由一组固定用户名及ID值的集合及一个生成器函数randName()构成。这个函数的代码也可以在11.10节找到。NAMES常量是一个元组,因为我们在randName()这个生成器里需要改变它的值,所以我们必须在randName()里先将它转换为一个列表。我们一次随机移除一个名字,直到列表为空为止。如果NAMES本身是一个列表,我们只能使用它一次(它就被消耗光了)。我们将它设计成为一个元组,这样我们就可以多次从这个元组生成一个列表供生成器使用。
105 ~ 115行
由于各种数据库之间有一些细微差别,insert()函数里的代码是依赖具体数据库的。举例来说,SQLite和MySQL的接口程序都是DB-API兼容的,所以它们的游标对象都拥有executemany()方法,可是Gadfly没有这个方法,因此它只能一次插入一行。
另一个不同之处在于SQLite和Gadfly的参数风格是qmark,而MySQL的参数风格是format。由于这些原因,格式字符串必须不同。如果你比较细心的话,你会看到他们的参数创建过程非常相似。
这段代码的功能是:对每个name-userlD数据对,随机分配一个项目小组ID,然后存入数据库。
117行
这独立的一行是有一个条件表达式(读作Python 3目操作符),它返回最后一步操作所影响的行数,如果游标对象不支持这个属性(也就是说这个接口程序不兼容DB-API)的话,它返回-1。python2.5中新增了条件表达式,如果你使用的是python 2.4.x或更老版本,你可能就需要将它转换为老风格的方式了,如下所示。

如果你看不太明白这行代码,不用着急。看看FAQ就能知道为什么最终Python2.5中加入了条件表达式。如果你能弄明白,你就彻底搞明白了Python对象以及他们的布尔值。
119 ~ 129行
update()和delete()函数随机从一个组里选择了几条记录,如果是update操作,就将他们从当前小组移到另一个小组(也是随机选择的)。如果是delete操作,则删除它们。
131 ~ 137行
dbDump()函数从数据库中读取所有数据,并将数据进行格式化,然后显示给用户看。print语句显示每个用户不够清晰,所以我们将它分开显示。
首先,通过fetchall()方法读取数据,然后迭代遍历每个用户,将三列数据(login、uid、 prid)转换为字符串(如果它们还不是的话),并将姓和名的首字母大写,再格式化整个字符为左对齐的COLSIZ列(右边留白)。由代码生成的字符串是一个列表(通过列表解析),我们需要将它们转换成一个元组以支持%操作符。
139 ~ 174行
本部影片的导演main()出场。它将上面定义的这些函数组织起来,让它们尽情发挥。(假定它们没有因为找不到数据库接口程序或者不能得到有效连接对象而中途退出(第143~145行))。它的大部分代码都是能够自我解释的print语句。最后main()关闭游标对象,提交操作,然后关闭数据库连接。脚本的最后几行代码用来启动脚本的执行。
21.3 对象-关系管理器(ORM)
通过前一节我们知道,如今有很多种数据库系统,他们中的绝大多数都有Python接口,以方便你驾驭他们的能量。这些系统唯一的缺点是需要你懂得SQL。如果你喜欢折腾Python对象却讨厌SQL查询,又想使用关系型数据库作为你的数据存储的后端,你就完全具备成为一个ORM用户的天资。
21.3.1 考虑对象,而不是SQL
这些系统的创建者将绝大多数纯SQL层功能抽象为Python对象,这样你就无需编写SQL也能够完成同样的任务。如果你在某些情况下实在需要SQL,有些系统也允许你拥有这种灵活性。但绝大多数情况下,你应该尽量避免进行直接的SQL查询。
数据库的表被转换为Python类,它具有列属性和操作数据库的方法。让你的应用程序支持ORM非常类似使用那些标准的数据库接口程序。由于大部分工作由ORM代为处理,相比直接使用接口程序来说,一些事情可能实际需要更多的代码。令人欣慰的是,一点点额外的付出会回报你更高的生产率。
21.3.2 Python和ORM
如今最知名的Python ORM模块是SQLAlchemy和SQLObject。由于二者有着不同的设计哲学,我们会分别给出SQLAlchemy和SQLObject的例子。只要你能搞清楚这两种ORM的使用,转到其他的ORM将是相当简单的事。
其他的Python ORM包括pyDO/PyD02、PDO、Dejavu、Durus、QLime和ForgetSQL。一些大型的Web开发工具/框架也可以有自己的ORM组件,如WebWare MiddleKit和Django的数据库API。需要指出的是,知名的ORM并不意味着就是最适合你的应用程序的ORM。那些其他的ORM虽然没有纳入我们的讨论范围,但一样有可能是适合你的应用程序的选择。
21.3.3 雇员数据库举例
现在我们将shuffle应用程序ushuffle_db.py改造为使用SQLAlchemy和SQLObject实现。数据库后端仍然是MySQL。相对于直接使用原始SQL来讲,我们使用ORM时用类代替了函数,这样会更有对象的感觉。两个例子都使用了ushuffle_db.py中的NAMES集合和随机名字选择函数。这是为了避免将同样的代码到处复制粘贴,代码能够被有效重用是件好事情。
1.SQLAlchemy
与SQLObject相比,SQLAlchemy的接口在某种程度上更接近SQL,所以我们先从SQLAlchemy开始。SQLAlchemy的抽象层确实相当完美,而且在你必须使用SQL完成某些功能时,它提供了足够的灵活性。你会发现这两个ORM模块在设置及存取数据时使用的术语非常相似,代码长度也很接近,都比ushuffle_db.py少(包括共享的names列表和随机名字生成器)。
2.逐行解释
1 ~ 10行
和前面一样,第一件事是导入相关的模块和常量。我们提倡首先导入Python标准库模块,然后再导入第三方或扩展模块,最后导入本地模块这种风格。这些常量都是自解释的。
12 ~ 31行
12~31行是类的构造器,类似ushuffle_db.connect()。它确保数据库可用并返回一个有效连接(第18~31行)。这也是唯一能看到原始SQL的地方。这是一种典型的操作任务,不是面向应用的任务。
33 ~ 44行
这个try-except子句(33~40行)用来重新载入一个已有的表,或者在表不存在的情况下创建一个新表。最终我们得到一个合适的对象实例。
例21.2
这个user shuffle程序的主角是SQLAlchemy前端和MySQL数据库后端。



46 ~ 70行
这4个方法处理数据库核心功能:创建表(46~52行、插入数据(54~57行)、更新数据(59~64行)、删除数据(66~70行)。我们也有一个方法用来删除表。

不过,我们还是决定提供另一种授权处理方式(曾在第13章中介绍)。授权就是指一个方法调用不存在时,转交给另一个拥有此方法的对象去处理。参见第79~80行的解释。
72 ~ 77行
输出内容由dbDumpO方法完成。它从数据库中得到数据,就像ushuffle_db.py中那样对数据进行美化,事实上,这部分代码几乎完全相同。
79 ~ 80行
应该尽量避免为一个表创建一个drop()方法,因为这总是会调用table自身的drop()方法。同样,既然没有新增功能,那我们有什么必要创建另一个函数?无论属性查找是否成功,特殊方法getattr()总是会被调用。如果调用orm.drop()却发现这个对象并没有drop()方法,getattr(orm,’drop’)就会被调用。发生这种情况时,__getattr__()被调用,之后将这个属性名委托给self.users。解释器会发现self.users有一个drop属性并执行。
例21.3 SQLObject ORM示例(ushuffle_so.py)
这个user shuffle应用程序的主角前端是SQLObject,后端是MySQL数据库。



82 ~ 84行
最后一个方法是finish,它来提交整个事务。
86 ~ 114行
main()函数是整个应用程序的入口,它创建了一个MySQLAlchemy对象并通过它完成所有的数据库操作。这段脚本和ushuffle_db.py功能一样。你会注意到数据库参数db是可选的,而且在ushuffle_sa.py和即将碰到的ushuffle_so.py中,它不起任何作用。它只是一个占位符以方便你对这个应用程序添加其他的数据库支持(参见本章后面的习题)。
运行这段脚本,你会看到类似下面的输出:
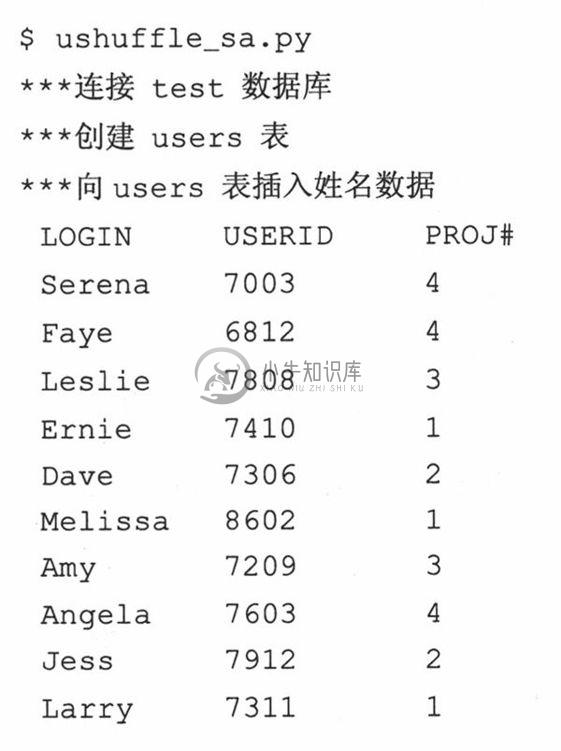
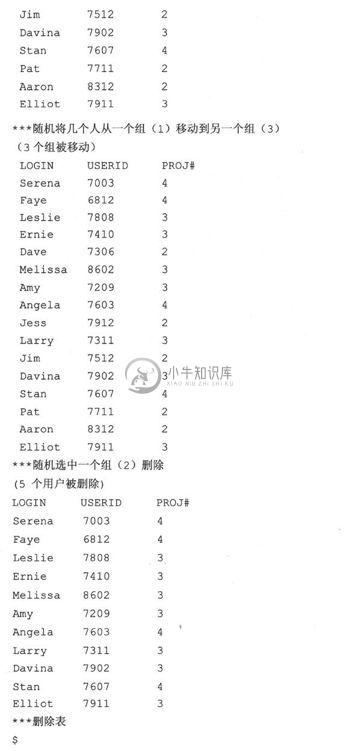
3.逐行解释
1 ~ 10行
除了我们使用的是SQLObject而不是SQLAlchemy以外,导入模块和常量声明几乎与ushuffle_sa.py相同。
12 ~ 42行
类似我们的SQLAlchemy例子,类的构造器做大量工作以确保有一个数据库可用,然后返回一个连接。同样的,这也是你能在程序里看到SQL语句的唯一位置。我们这个程序,如果因为某种原因造成SQLObject无法成功创建用户表,就会陷入无限循环当中。
我们尝试能够聪明地处理错误,解决掉这个重建表的问题。因为SQLObject使用元类,我们知道类的创建幕后发生特殊事件,所以我们不得不定义两个不同的类,一个用于表已经存在的情况,一个用于表不存在的情况。代码工作原理如下。
1.尝试建立一个连接到一个已经存在的表。如果正常工作,成功(第23〜29行).
2.如果第一步不成功,则从零开始为这个表创建一个类,如果成功,成功(第31〜36行).
3.如果第二步仍不成功,我们的数据库可能遇到麻烦,那就重新创建一个新的数据库(第37〜40行).
4.重新开始新的循环。
希望程序最终能在第一步或第二步成功完成。当循环结束时,类似ushuffle_sa.py,我们得到合适的对象实例。
44 ~ 67行、77 ~ 78行
这些行处理数据库操作。我们在44〜47行创建了表,并在77行删掉了表。在49〜52行插入数据,在54〜60行更新数据,在62〜67行删除了数据。78行调用了finish()方法来关闭数据库连接。我们不能像SQLAlchemy那样使用授权删表代理,因为SQLObject的删表代理名为dropTable()而不是drop().
69 ~ 75行
使用dbDump()方法,我们从数据库中得到数据,并将它显示在屏幕上。
80 ~ 108行
又到了main()函数。它工作的方式非常类似ushuffle_sa.py。同样,构造器的db参数仅仅是一个占位符,用以支持其他的数据库系统(参阅本章最后的习题).
当你运行这段脚本时,你的输出可能类似这样:
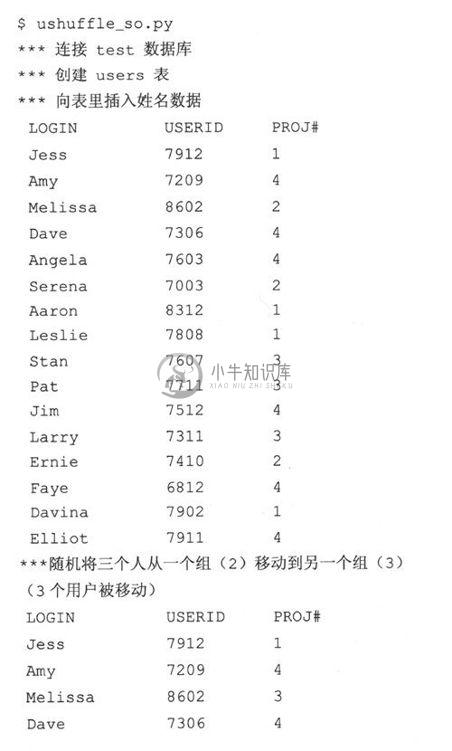
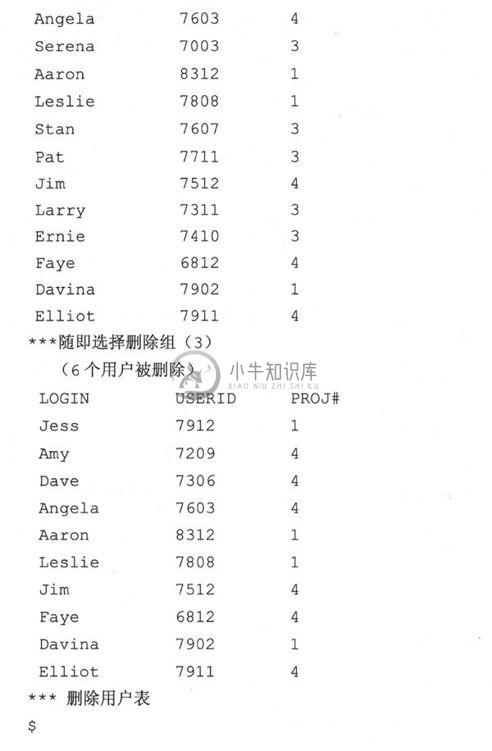
21.3.4 总结
关于如何在Python中使用关系型数据库,希望我们前面介绍的东西对你有用。当你应用程序的需求超出纯文本或类似DBM等特殊文件的能力时,有多种数据库可供选择,别忘了还有一个完全由Python实现的真正的免安装维护和管理的真实数据库系统。你能在下面找到多种Python数据库接口程序和ORM系统。我们也建议你研究一下互联网上的DB-SIG的网页和邮件列表。类似其他的软件开发领域,只不过Python更简单易学,用户体验更好。
21.4 相关模块
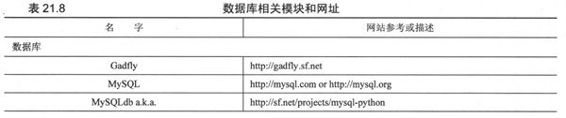
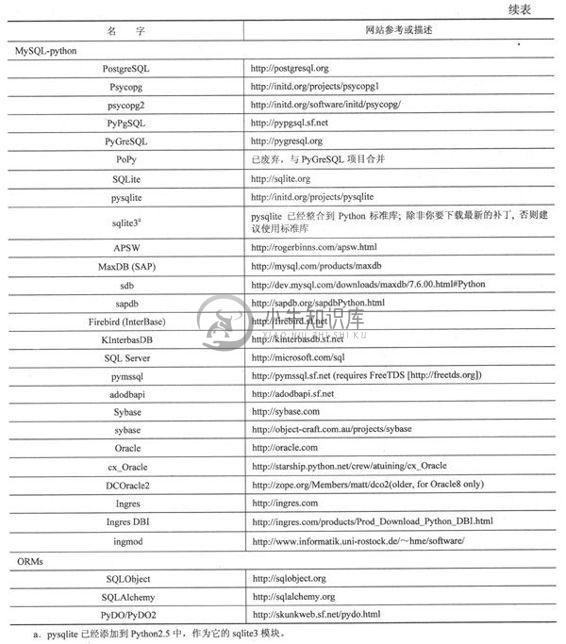
表21.8列出了常见的Python数据库接口程序,注意不是所有的接口程序都是DB-API兼容的。
21.5 练习
21-1.什么是Python DB-API?它是一个好东西吗?为什么是(或为什么不是)?
21-2.描述一下数据库模块参数风格之间的不同在哪儿?
21-3.游标对象的executed()系列方法有何区别?
21-4.游标对象的fetch*()系列方法有何区别?
21-5.研究一下你使用的数据库及相应的Python模块。它是否与DB-API兼容?该模块是否提供了DB-API必须功能之外的更多特性?
21-6.针对你使用的数据库和DB-API接口程序,学习使用Type对象写一段小的脚本,至少要用到其中的一个对象。
21-7.重构。例21.1 (ushuffle_db.py)中的create()函数,一个table会先被删除,然后递归调用create()函数重建这个table。如果在重建这个table时失败,就会陷入无限循环之中。通过在异常处理中不再调用create命令(cur.execute())修复这个问题,搞一个更实用的解决方案出来。附加题:实现如果创建table失败,在返回失败之前最多重试3次。
21-8.数据库和HTML。利用现有数据库的一个表和你在第20章学到的开发知识,读出数据库表的内容,将它放到一个HTML table中去。
21-9.数据库网站开发。给我们的user shuffle例子写一个网页界面。
21-10.数据库界面编程。给我们的user shuffle例子写一个图形界面。
21-11.股票投资组合类。修改第13章股票数据的例子,将它改造为使用某一种关系数据库保存数据。
21-12.切换ORM后端为其他的数据库。将SQLAlchemy(ushuffle_sa.py)或SQLObject (ushuffle_so.py)应用程序后端数据库由MySQL切换为另一种数据库系统。