
第9章 文件和输入输出
本章主题
♦ 文件对象
♦ 文件内建函数
♦ 文件内建方法
♦ 文件内建属性
♦ 标准文件
♦ 命令行参数
♦ 文件系统
♦ 文件执行
♦ 持久存储
♦ 相关模块
本章将深入介绍Python的文件处理和相关输入输出能力。我们将介绍文件对象(它的内建函数、内建方法和属性)、标准文件,同时讨论文件系统的访问方法、文件执行,最后简洁地介绍持久存储和标准库中与文件有关的模块。
9.1 文件对象
文件对象不仅可以用来访问普通的磁盘文件,也可以访问任何其他类型抽象层面上的“文件”。一旦设置了合适的“钩子”,你就可以访问具有文件类型接口的其他对象,就好像访问的是普通文件一样。
随着使用Python经验的增长,会遇到很多处理“类文件”对象的情况。有很多这样的例子,例如实时地“打开一个URL”来读取Web页面,在另一个独立的进程中执行一个命令进行通信,就好像是两个同时打开的文件,一个用于读取,另一个用于写入。
内建函数open()返回一个文件对象(参见下一小节),对该文件进行后续相关的操作都要用到它。还有大量的函数也会返回文件对象或是类文件(file-like)对象。进行这种抽象处理的主要原因是许多的输入/输出数据结构更趋向于使用通用的接口。这样就可以在程序行为和实现上保持一致性。甚至像Unix这样的操作系统把文件作为通信的底层架构接口。请记住,文件只是连续的字节序列。数据的传输经常会用到字节流,无论字节流是由单个字节还是大块数据组成。
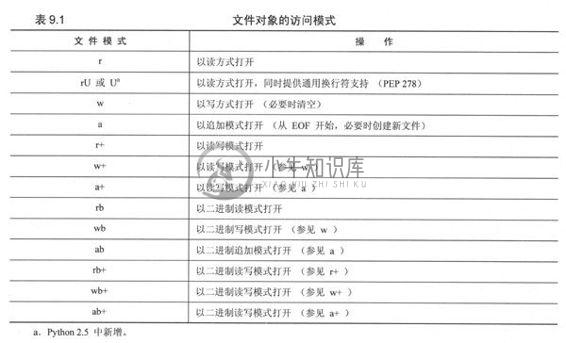
9.2 文件内建函数(open()和file())
作为打开文件之门的“钥匙”,内建函数open()[以及file()]提供了初始化输入/输出(I/O)操作的通用接口。open()内建函数成功打开文件后时候会返回一个文件对象,否则引发一个错误。当操作失败, Python会产生一个IOError异常——我们会在下一章讨论错误和异常的处理。内建函数open()的基本语法是:

file_name是包含要打开的文件名字的字符串,它可以是相对路径或者绝对路径。可选变量 access_mode也是一个字符串,代表文件打开的模式。通常,文件使用模式‘r’,‘W’,或是‘a’模式来打开,分别代表读取,写入和追加。还有个‘U’模式,代表通用换行符支持(见下)。
使用‘r’或‘U’模式打开的文件必须是已经存在的。使用‘W’模式打开的文件若存在则首先清空,然后(重新)创建。以‘a’模式打开的文件是为追加数据作准备的,所有写入的数据都将追加到文件的末尾。即使你seek到了其他的地方。如果文件不存在,将被自动创建,类似以“W”模式打开文件。如果你是一个C程序员,就会发现这些也是C库函数fopen()中使用的模式。
其他fopen()支持的模式也可以工作在Python的open()下。包括‘+’代表可读可写,‘b’代表二进制模式访问。关于‘b’有一点需要说明,对于所有POSIX兼容的Unix系统(包括Linux)来说,‘b’是可有可无的,因为它们把所有的文件当作二进制文件,包括文本文件。下面是从Linux手册的fopen()函数使用中摘录的一段,Python语言中的open()函数就是从它衍生出的。
指示文件打开模式的字符串中也可以包含字符“b”,但它不能作为第一个字符出现。这样做的目的是为了严格地满足ANSI C3.159-1989(即ANSI C)中的规定;事实上它没有任何效果,所有POSIX兼容系统,包括Linux,都会忽略“b”(其他系统可能会区分文本文件和二进制文件,如果你要处理一个二进制文件,并希望你的程序可以移植到其他非Unix的环境中,加上“b”会是不错的主意)。
你可以在表9.1中找到关于文件访问模式的详细列表,包括‘b’的使用——如果你选择使用它的话。如果没有给定access_mode,它将自动采用默认值‘r’。
另外一个可选参数buffering用于指示访问文件所采用的缓冲方式。其中0表示不缓冲,1表示只缓冲一行数据,任何其他大于1的值代表使用给定值作为缓冲区大小。不提供该参数或者给定负值代表使用系统默认缓冲机制,既对任何类电报机(tty)设备使用行缓冲,其他设备使用正常缓冲。一般情况下使用系统默认方式即可。
这里是一些打开文件的例子:

9.2.1 工厂函数file()
在Python 2.2中,类型和类被统一了起来,这时加入了内建函数file()。当时,很多内建类型没有对应的内建函数来创建对象的实例,例如dict()、bool()、file()等。然而,另一些却有对应的内建函数,例如list()、str()等。
open()和file()函数具有相同的功能,可以任意替换。您所看到任何使用open()的地方,都可以使用file()替换它。
可以预见,在将来的Python版本中,open()和file()函数会同时存在,完成相同的功能。一般说来,我们建议使用open()来读写文件,在您想说明您在处理文件对象时使用file(),例如if instance(f, file)。
9.2.2 通用换行符支持(UNS)
在下一个核心笔记中,我们将介绍如何使用OS模块的一些属性来帮助你在不同平台下访问文件,不同平台用来表示行结束的符号是不同的,例如\n,\r,或者\r\n。所以,Python的解释器也要处理这样的任务,特别是在导入模块时分外重要。你难道不希望Python用相同的方式处理所有文件吗?
这就是UNS(Universal NEWLINE Support,通用换行符支持)的关键所在,作为PEP 278的结果,Python 2.3引入了UNS。当你使用‘U’标志打开文件的时候,所有的行分隔符(或行结束符,无论它原来是什么)通过Python的输入方法(例如read*())返回时都会被替换为换行符NEWLINE(\n)。(‘rU’模式也支持‘rb’选项)。这个特性还支持包含不同类型行结束符的文件。文件对象的newlines属性会记录它曾“看到的”文件的行结束符。
如果文件刚被打开,程序还没有遇到行结束符,那么文件的newlines为None。在第一行被读取后,它被设置为第一行的结束符。如果遇到其他类型的行结束符,文件的newlines会成为一个包含每种格式的元组。注意UNS只用于读取文本文件。没有对应的处理文件输出的方法。
在编译Python的时候,UNS默认是打开的。如果你不需要这个特性,在运行configure脚本时,你可以使用--without-universal-newlines开关关闭它。如果你非要自己处理行结束符,请查阅核心笔记,使用os模块的相关属性。
9.3 文件内建方法
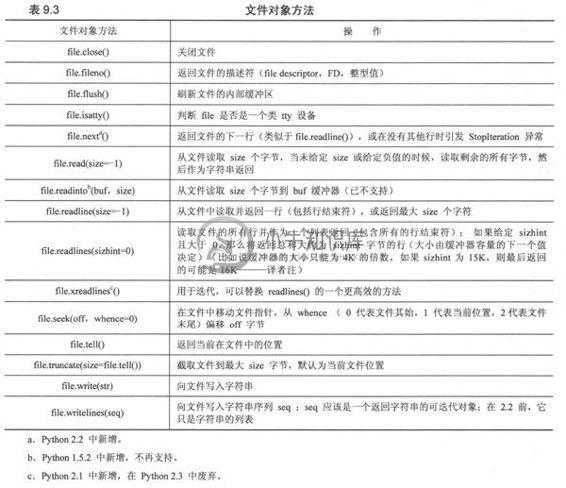
open()成功执行并返回一个文件对象之后,所有对该文件的后续操作都将通过这个“句柄”进行。文件方法可以分为四类:输入、输出、文件内移动及杂项操作。所有文件对象的总结被列在了表9.3中。我们现在来讨论每个类的方法。
9.3.1 输入
read()方法用来直接读取字节到字符串中,最多读取给定数目个字节。如果没有给定size参数(默认值为-1)或者size值为负,文件将被读取直至末尾。未来的某个版本可能会删除此方法。
readline()方法读取打开文件的一行(读取下个行结束符之前的所有字节)。然后整行,包括行结束符,作为字符串返回。和read()相同,它也有一个可选的size参数,默认为-1,代表读至行结束符。如果提供了该参数,那么在超过size个字节后会返回不完整的行。
readlines()方法并不像其他两个输入方法一样返回一个字符串。它会读取所有(剩余的)行然后把它们作为一个字符串列表返回。它的可选参数sizhint代表返回的最大字节大小。如果它大于0,那么返回的所有行应该大约有sizhint字节(可能稍微大于这个数字,因为需要凑齐缓冲区大小)。
Python 2.1中加入了一个新的对象类型用来高效地迭代文件的行:xreadlines对象(可以在 xreadlines模块中找到)。调用file.xreadlines()等价于xreadlines.xreadlines(file)。xreadlines()不是一次性读取所有的行,而是每次读取一块,所以用在for循环时可以减少对内存的占用。不过,随着Python 2.3中迭代器和文件迭代的引入,没有必要再使用xreadlines()方法,因为它和使用iter(file)的效果是一样的,或者在for循环中,使用for eachLine in file代替它。它来得容易,去得也快。
另一个废弃的方法是readinto(),它读取给定数目的字节到一个可写的缓冲器对象,和废弃的buffer()内建函数返回的对象是同个类型(由于buffer()已经不再支持,所以readinto()被废弃)。
9.3.2 输出
write()内建方法的功能与read()和readline()相反。它把含有文本数据或二进制数据块的字符串写入到文件中去。
和readlines()一样,writelines()方法是针对列表的操作,它接受一个字符串列表作为参数,将它们写入文件。行结束符并不会被自动加入,所以如果需要的话,你必须在调用writelines()前给每行结尾加上行结束符。
注意这里并没有“writeline()”方法,因为它等价于使用以行结束符结尾的单行字符串调用write()方法。
 核心笔记:保留行分隔符
核心笔记:保留行分隔符
当使用输入方法如read()或者readlines()从文件中读取行时,Python并不会删除行结束符,这个操作被留给了程序员。例如这样的代码在Python程序中很常见:

类似地,输出方法write()或writelines()也不会自动加入行结束符。你应该在向文件写入数据前自己完成。
9.3.3 文件内移动
seek()方法(类似C中的fseek()函数)可以在文件中移动文件指针到不同的位置。offset字节代表相对于某个位置偏移量。位置的默认值为0,代表从文件开头算起(即绝对偏移量),1代表从当前位置算起, 2代表从文件末尾算起。如果你是一个C程序员,并且使用过了fseek(),那么,0、1、2分别对应着常量 SEEK_SET、SEEK_CUR和SEEK_END。当人们打开文件进行读写操作的时候就会接触到seek()方法。
text()方法是对seek()的补充;它告诉你当前文件指针在文件中的位置——从文件起始算起,单位为字节。
9.3.4 文件迭代
一行一行访问文件很简单:

:
在这个循环里,eachLine代表文本文件的一行(包括末尾的行结束符),你可以使用它做任何想做的事情。
在Python 2.2之前,从文件中读取行的最好办法是使用file.readlines()来读取所有数据,这样程序员可以尽快释放文件资源。如果不需要这样做,那么程序员可以调用file.readline()一次读取一行。曾有一段很短的时间,file.xreadlines()是读取文件最高效的方法。
在Python 2.2中,我们引进了迭代器和文件迭代,这使得一切变得完全不同,文件对象成为了它们自己的迭代器,这意味着用户不必调用read*()方法就可以在for循环中迭代文件的每一行。另外我们也可以使用迭代器的next方法,file.next()可以用来读取文件的下一行。和其他迭代器一样,Python也会在所有行迭代完成后引发Stoplteration异常。
所以请记住,如果你见到这样的代码,这是“完成事情的老方法”,你可以安全地删除对readline()的调用。

:
文件迭代更为高效,而且写(和读)这样的Python代码更容易。如果你是Python新手,那么请使用这些新特性,不必担心它们过去是如何。
9.3.5 其他
close()通过关闭文件来结束对它的访问。Python垃圾收集机制也会在文件对象的引用计数降至零的时候自动关闭文件。这在文件只有一个引用时发生,例如fp=open(…),然后fp在原文件显式地关闭前被赋了另一个文件对象。良好的编程习惯要求在重新赋另一个文件对象前关闭这个文件。如果你不显式地关闭文件,那么你可能丢失输出缓冲区的数据。
fileno()方法返回打开文件的描述符。这是一个整型,可以用在如os模块(os.read())的一些底层操作上。
调用flush()方法会直接把内部缓冲区中的数据立刻写入文件,而不是被动地等待输出缓冲区被写入。isatty()是一个布尔内建函数,当文件是一个类tty设备时返回True,否则返回False。truncate()方法将文件截取到当前文件指针位置或者到给定size,以字节为单位。
9.3.6 文件方法杂项
我们现在重新实现第2章中的第一个文件例子:

我们曾经介绍过这个程序。与大多数标准的文件访问方法相比,它的不同在于它读完所有的行才开始向屏幕输出数据。很明显如果文件很大,这个方法并不好。这时最好还是回到最可靠的方法:使用文件迭代器,每次只读取和显示一行:

核心笔记:行分隔符和其他文件系统的差异
操作系统间的差异之一是它们所支持的行分隔符不同。在POSIX(Unix系列或MacOS X)系统上,行分隔符是换行符NEWLINE ( \n)字符。在旧的MacOS下是RETURN( \r),而DOS和Wind32系统下结合使用了两者 (\r\n)。检查一下你所使用的操作系统用什么行分隔符。
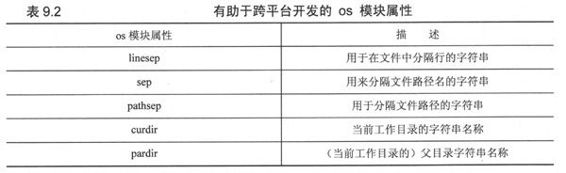
另一个不同是路径分隔符(POSIX使用“/”; DOS和Windows使用“\”;旧版本的MacOS使用“:”);它用来分隔文件路径名;标记当前目录和父目录。当我们创建要跨这3个平台的应用的时候;这些差异会让我们感觉非常麻烦(而且支持的平台越多越麻烦)。幸运的是Python的os模块设计者已经帮我们想到了这些问题。os模块有5个很有用的属性。它们被列在了表9.2中。
不管你使用的是什么平台,只要你导入了os模块,这些变量自动会被设置为正确的值,减少了你的麻烦。
还要提醒大家的是:print语句默认在输出内容末尾后加一个换行符,而在语句后加一个逗号就可以避免这个行为。readline()和readlines()函数不对行里的空白字符做任何处理(参见本章练习),所以你有必要加上逗号。如果你省略逗号,那么显示出的文本每行后会有两个换行符,其中一个是输入是附带的,另一个是print语句自动添加的。
文件对象还有一个truncate()方法,它接受一个可选的size作为参数。如果给定,那么文件将被截取到最多size字节处。如果没有传递size参数,那么默认将截取到文件的当前位置。例如:你刚打开了一个文件,然后立即调用truncate()方法,那么你的文件(内容)实际上被删除,这时候你其实是从0字节开始截取的(tell()将会返回这个数值)。
在学习下一小节之前,我们再来看两个例子,第一个展示了如何输出到文件,第二个展示了文件的输出和输入,以及用于文件定位的seek()和tell()方法的使用。
这里我们每次从用户接收一行输入,然后将文本保存到文件中。由于raw_input()不会保留用户输入的换行符,调用write()方法时必须加上换行符。而且,在键盘上很难输入一个EOF (end-of-file)字符,所以,程序使用句点(.)作为文件结束的标志,当用户输入句点后会自动结束输入并关闭文件。
第二个例子以可读可写模式创建一个新的文件(可能是清空了一个现有的文件).在向文件写入数据后,我们使用seek()方法在文件内部移动,使用tell()方法展示我们的移动过程。
表9.3文件对象的内建方法列表。
文件对象除了方法之外,还有一些数据属性。这些属性保存了文件对象相关的附加数据,例如文件名(file.name),文件的打开模式(file.mode),文件是否已被关闭(file.closed),以及一个标志变量,它可以决定使用print语句打印下一行前是否要加入一个空白字符(file.softspace)。表9.4列出了这些属性并做了简短说明。
一般说来,只要你的程序一执行,你就可以访问3个标准文件。它们分别是标准输入(一般是键盘)、标准输出(到显示器的缓冲输出)和标准错误(到屏幕的非缓冲输出)(这里所说的“缓冲”和“非缓冲”是指open()函数的第3个参数)。这些文件沿用的是C语言中的命名,分别为stdin, stdout和stderr。我们说“只要你的程序一执行就可以访问这3个标准文件”,意思是这些文件已经被预先打开了,只要知道它们的文件句柄就可以随时访问这些文件。
Python中可以通过sys模块来访问这些文件的句柄。导入sys模块以后,就可以使用sys.stdin、sys.stdout和sys.stderr访问。print语句通常是输出到sys.stdout;而内建raw_input()则通常从sys.stdin接收输入。
记得sys.*是文件,所以你必须自己处理好换行符。而print语句会自动在要输出的字符串后加上换行符。
sys模块通过sys.argv属性提供了对命令行参数的访问。命令行参数是调用某个程序时除程序名以外的其他参数。这样命名是有历史原因的,在一个基于文本的环境里(比如UNIX操作系统的shell环境或者DOS-shell),这些参数和程序的文件名一同被输入的。但在IDE或者GUI环境中可能就不会是这样了,大多IDE环境都提供一个用来输入“命令行参数”的窗口;这些参数最后会像命令行上执行那样被传递给程序。
熟悉C语言的读者可能会问了,“argc哪去了?”argc和argv分别代表参数个数(argument count)和参数向量(argument vector)。argv变量代表一个从命令行上输入的各个参数组成的字符串数组;argc变量代表输入的参数个数。在Python中,argc其实就是sys.argv列表的长度,而该列表的第一项sys.argv[0]永远是程序的名称。
总结如下:
sys.argv是命令行参数的列表;
len (sys.argv)是命令行参数的个数(也就是argc)。
我们来创建这个名为argv.py的测试程序:
下面是该脚本程运行的输出:
命令行参数有用吗? Unix操作系统中的命令通常会接受输入,执行一些功能,然后把结果作为流输出出来。这些输出的结果还可能被作为下一个程序的输入数据,在完成了一些其他处理后,再把新的输出送到下一个程序。如此延伸下去。各个程序的输出一般是不保存的,这样可以节省大量的磁盘空间,各个程序的输出通常使用“管道”实现到下个程序输入的转换。
这是通过向命令行提供数据或是通过标准输入实现的。当一个程序显示或是发送它的输出到标准输出文件时,内容就会出现在屏幕上——除非该程序被管道连接到下一个程序,那么此时程序的标准输出就成为下个程序的标准输入。你现在明白了吧?
命令行参数使程序员可以在启动一个程序的时候对程序行为做出选择。在大多情况下,这些执行操作都不需要人为干预,通过批处理执行。命令行参数配合程序选项可以实现这样的处理功能。让计算机在夜里有空闲时完成一些需要大量处理的工作。
Python还提供了两个模块用来辅助处理命令行参数。其中一个(最原始的)是getopt模块,它更简单些,但是不是很精细。而Python 2.3引入的optparse模块提供了一个更强大的工具,而且它更面向对象。如果你只是用到一些简单的选项,我们推荐getopt,但如果你需要提供复杂的选项,那么请参阅 optparse。
对文件系统的访问大多通过Python的os模块实现。该模块是Python访问操作系统功能的主要接口。os模块实际上只是真正加载的模块的前端,而真正的那个“模块”明显要依赖与具体的操作系统。这个“真正”的模块可能是以下几种之一:posix (适用于Unix操作系统),nt (Win32), mac (旧版本的MacOS), dos (DOS), os2 (OS/2),等等。你不需要直接导入这些模块。只要导入os模块,Python会为你选择正确的模块,你不需要考虑底层的工作。根据你系统支持的特性,你可能无法访问到一些在其他系统上可用的属性。
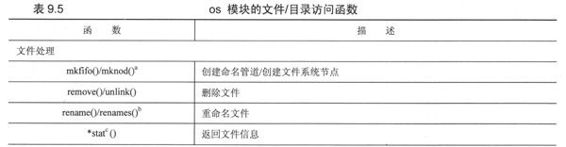
除了对进程和进程运行环境进行管理外,os模块还负责处理大部分的文件系统操作,应用程序开发人员可能要经常用到这些。这些功能包括删除/重命名文件,遍历目录树,以及管理文件访问权限等。表9.5列出os模块提供的一些常见文件或目录操作函数。
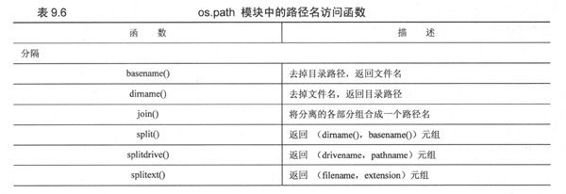
另一个模块os.path可以完成一些针对路径名的操作。它提供的函数可以完成管理和操作文件路径名中的各个部分,获取文件或子目录信息,文件路径查询等操作。表9.6列出了 os.path中的几个比较常用的函数。
这两个模块提供了与平台和操作系统无关的统一的文件系统访问方法。例9.1 (ospathex.py)展示了os和os.path模块中部分函数的使用。
例9.1 os和 os.path模块例子(ospathex.py)
这段代码练习使用一些os和os.path模块中的功能。它创建一个文本文件,写入少量数据,然后重命名,输出文件内容。同时还进行了一些辅助性的文件操作,比如遍历目录树和文件路径名处理。
os的子模块os.path更多用于文件路径名处理。比较常用的属性列于表9.6中。在Unix平台下执行该程序,我们会得到如下输出:
在 DOS窗口下执行这个例子我们会得到非常相似的输出:
这里就不逐行解释这个例子了,我们把这个留给读者做练习。下面我们来看看一个类似的交互式例子(包括错误),我们会把代码分成几个小段,然后依次进行讲解。
代码的第一部分导入了 os模块(同时也包含os.path模块)。然后检查并确认 ‘/tmp’是一个合法的目录,并切换到这个临时目录开始我们的工作。之后我们用getcwd()方法确认我们当前位置。
接下来,我们在临时目录里创建了一个子目录,然后用listdir()方法确认目录为空(因为我们刚创建它)。第一次调用listdir()调用时出现的问题是因为我们没有传递要列目录的路径名。我们马上在第二次调用时修正了这个失误。
这里我们创建了一个有两行内容的test文件,之后列目录确认文件被成功创建。
这一段代码使用了 os.path的一些功能,包括我们之前看到过的 join()、isfile()、isdir()、split()、basename()和splitext(),我们还调用了 os下的rename()函数。接下来,我们显示文件的内容,之后,删除之前创建的文件和目录。
核心模块:os (和 os.path)
从上面这些长篇讨论可以看出,os和os.path模块提供了访问计算机文件系统的不同方法。我们在本章学习的只是文件访问方面,事实上 os模块可以完成更多工作。我们可以通过它管理进程环境,甚至可以让一个Python程序直接与另外一个执行中的程序“对话”。你很快就会发现自己离不开这个模块了。更多关于os模块的内容请参阅第14章。
无论你只是想简单地运行一个操作系统命令,调用一个二进制可执行文件,或者其他类型的脚本(可能是shell脚本,Perl,或是Tcl/Tk),都需要涉及运行系统其他位置的其他文件。尽管不经常出现,但是有时甚至会需要启动另外一个Python解释器。我们将把这部分内容留到第14章去讨论。如果读者有兴趣了解如何启动其他程序,以及如何与它们进行通讯,或者是Python执行环境的一般信息,都可以在第14章找到答案。
在本书的很多练习里,都需要用户输入数据。这可能需要用户多次输入重复的数据,尤其是如果你要输入大批数据供以后使用时,你肯定会厌烦。这就是永久储存大显身手的地方了,它可以把用户的数据归档保存起来供以后使用,这样你就可以避免每次输入同样的信息。在简单的磁盘文件已经不能满足你的需要,而使用完整的关系数据库管理系统(relational database management systems,RDBMS)又有些大材小用时,简单的永久性储存就可以发挥它的作用。大部分永久性储存模块是用来储存字符串数据的,但是也有方法来归档Python对象。
9.9.1 pickle和 marshal模块
Python提供了许多可以实现最小化永久性储存的模块。其中的一组(marshal和pickle)可以用来转换并储存Python对象。该过程将比基本类型复杂的对象转换为一个二进制数据集合,这样就可以把数据集合保存起来或通过网络发送,然后再重新把数据集合恢复原来的对象格式。这个过程也被称为数据的扁平化、数据的序列化或者数据的顺序化。另外一些模块(dbhash/bsddb,dbm,gdbm,dumbdbm等)及它们的“管理器” (anydbm)只提供了 Python字符串的永久性储存。而最后一个模块(shelve)则两种功能都具备。
我们已经提到marshal和pickle模块都可以对Python对象进行储存转换。这些模块本身并没有提供“永久性储存”的功能,因为它们没有为对象提供名称空间,也没有提供对永久性储存对象的并发写入访问(concuirent write access)o它们只能储存转换Python对象,为保存和传输提供方便。数据储存是有次序的(对象的储存和传输是一个接一个进行的)。marshal和pickle模块的区别在于marshal只能处理简单的Python对象(数字、序列、映射以及代码对象),而pickle还可以处理递归对象,被不同地方多次引用的对象,以及用户定义的类和实例。pickle模块还有一个增强的版本叫cPickle,使用C实现了相关的功能。
9.9.2 DBM风格的模块
*db*系列的模块使用传统的DBM格式写入数据,Python提供了 DBM的多种实现:dbhash/bsddb、dbm、gdbm和dumbdbm等。你可以随便按照你的爱好使用,如果你不确定的话,那么最好使用anydbm模块,它会自动检测系统上已安装的DBM兼容模块,并选择“最好”的一个。 dumbdbm模块是功能最少的一个,在没有其他模块可用时,anydbm才会选择。这些模块为用户的对象提供了一个命名空间,这些对象同时具备字典对象和文件对象的特点。不过不足之处在于它们只能储存字符串,不能对Python对象进行序列化。
9.9.3 shelve模块
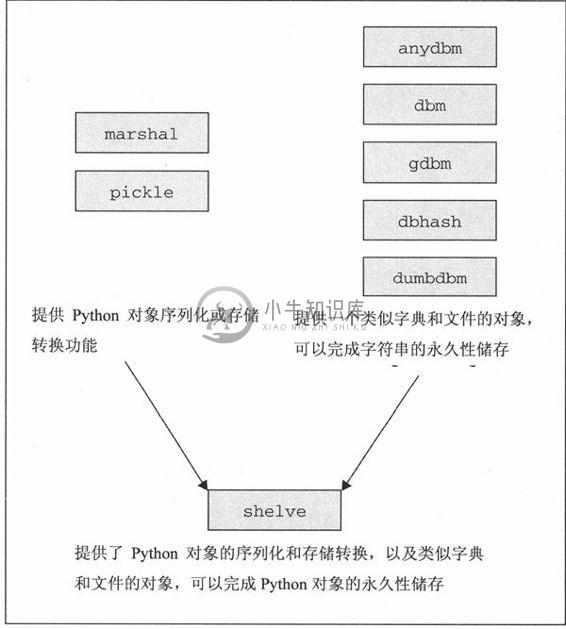
最后,我们来看一个更为完整的解决方案,shelve模块。shelve模块使用anydbm模块寻找合适的DBM模块,然后使用cPickle来完成对储存转换过程。shelve模块允许对数据库文件进行并发的读访问,但不允许共享读/写访问。这也许是我们在Python标准库里找到的最接近于永久性储存的东西了。可能有一些第三方模块实现了“真正”的永久性储存。图9-1展示了储存转换模块与永久性储存模块之间的关系,以及为何shelve对象能成为两者的最好的选择的。
图 9-1 用于序列化和永久性储存的 Python模块
核心模块: pickle和 cPickle
你可以使用pickle模块把Python对象直接保存到文件里,而不需要把它们转化为字符串,也不用底层的文件访问操作把它们写入到一个二进制文件里。pickle模块会创建一个Python语言专用的二进制格式,你不需要考虑任何文件细节,它会帮你干净利索地完成读写对象操作,唯一需要的只是一个合法的文件句柄。
pickle模块中的两个主要函数是dump()和load()。dump()函数接受一个文件句柄和一个数据对象作为参数,把数据对象以特定格式保存到给定文件里。当我们使用load()函数从文件中取出已保存的对象时,pickle知道如何恢复这些对象到它们本来的格式。我们建议你看一看pickle和更“聪明”的shelve模块,后者提供了字典式的文件对象访问功能,进一步减少了程序员的工作。
cPickle是pickle的一个更快的C语言编译版本。
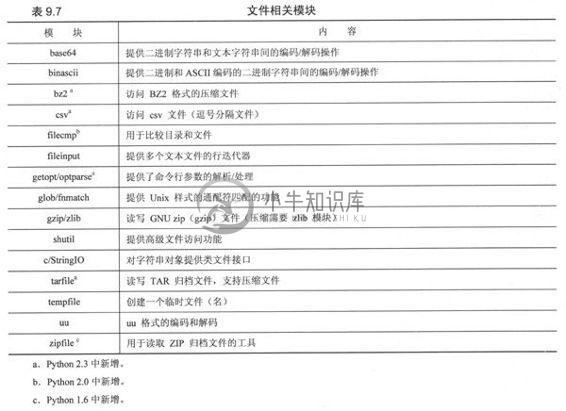
还有大量的其他模块与文件和输入/输出有关,它们中的大多数都可以在主流平台上工作。表9.7列出了一些文件相关的模块。
fileinput模块遍历一组输入文件,每次读取它们内容的一行,类似Perl语言中的不带参数的“<>”操作符。如果没有明确给定文件名,则默认从命令行读取文件名。
glob和fnmatch模块提供了老式Unix shell样式文件名的模式匹配,例如使用星号(*)通配符代表任意字符串,用问号(?)匹配任意单个字符。
核心提示:使用 os.path.expanduser()的波浪号(~)进行扩展
虽然glob和fnmatch提供了 Unix样式的模式匹配,但它们没有提供对波浪号(用户目录)字符,〜的支持。你可以使用os.path.expanduser()函数来完成这个功能,传递一个带波浪号的目录,然后它会返回对应的绝对路径。这里是两个例子,分别运行在Unix和Win32环境下:
另外Unix衍生系统还支持 “~user”这样的用法,表示指定用户的目录,还要注意Win32版本函数没有使用反斜杠来分隔目录路径。





















gzip和zlib模块提供了对zlib压缩库直接访问的接口。gzip模块是在zlib模块上编写的,不但实现了标准的文件访问,还提供了自动的gzip压缩/解压缩bz2类似于gzip,用于操作bzip压缩的文件。
程序员可以通过1.6中新增的zipfile模块创建,修改和读取zip归档文件。(tarfile文件实现了针对tar归档文件的相同功能)。在2.3版本中,Python加入了导入归档zip文件中模块的功能。更多细节请参阅12.5.7小节。
shutil模块提供高级的文件访问功能,包括复制文件、复制文件的访问权限、递归地目录树复制等。
tempfile模块用于生成临时文件(名)。
在关于字符串一章中,我们介绍了 StringlO模块(和它的C语言版本cStringIO),并且介绍了它是如何在字符串对象顶层加入文件操作接口的。这个接口包括文件对象的所有标准方法。
我们在前面永久性储存一节(9.9节)中介绍的模块还有文件和字典对象混合样式的例子。
其他的Python类文件对象还有网络和文件socket对象(socket模块),用于管道连接的popen*()文件对象(os和popen2模块),用于底层文件访问的fdopen()文件对象(os模块),通过URL (UniformResource Locator,统一资源定位符)建立的到指定Web服务器的网络连接(urllib模块)等。需要注意的是并非所有的标准文件方法都能在这些对象上实现,同样的,这些对象也提供了一些普通文件没有的功能。
具体内容请参考这些模块的相关文档,你可以在下边这些地址中找到关于file()/open(),文件,文件对象的更多信息,(这里我们还建议读者参考Python标准库,译者注)
http://docs.python.org/lib/built-in-flincs.html
http://docs.python.org/lib/bltin-file-objects.html
http://www.python.org/doc/2.3/whatsnew/node7.html
http://www.python.org/doc/peps/pep-0278/
9.11 练习
9-1.文件过滤。显示一个文件的所有行,忽略以井号(#)开头的行。这个字符被用做Python, Perl,Tcl,等大多脚本文件的注释符号。
附加题:处理不是第一个字符开头的注释。
9-2.文件访问,提示输入数字N和文件F,然后显示文件F的前Ν行。
9-3.文件信息,提示输入一个文件名,然后显示这个文本文件的总行数。
9-4.文件访问,写一个逐页显示文本文件的程序。提示输入一个文件名,每次显示文本文件的25行,暂停并向用户提示“按任意键继续”,按键后继续执行。
9-5.考试成绩,改进你的考试成绩问题(练习5-3和练习6-4),要求能从多个文件中读入考试成绩。文件的数据格式由你自己决定。
9-6.文件比较,写一个比较两个文本文件的程序,如果不同,给出第一个不同处的行号和列号。
9-7.解析文件。Win32用户,创建一个用来解析Windows .ini文件的程序。 POSIX用户,创建一个解析/etc/serves文件的程序。其他平台用户,写一个解析特定结构的系统配置文件的程序。
9-8.模块研究。提取模块的属性资料。提示用户输入一个模块名(或者从命令行接受输入)。然后使用dir()和其他内建函数提取模块的属性,显示它们的名字、类型、值。
9-9.Python文档字符串。进入Python标准库所在的目录。检查每个.py文件看是否有doc字符串,如果有,对其格式进行适当的整理归类。你的程序执行完毕后,应该会生成一个漂亮的清单。里边列出哪些模块有文档字符串,以及文档字符串的内容,清单最后附上那些没有文档字符串模块的名字。
附加题:提取标准库中各模块内全部类(class)和函数的文档。
9-10.家庭理财。创建一个家庭理财程序。你的程序需要处理储蓄、支票、金融市场,定期存款等多种账户。为每种账户提供一个菜单操作界面,要有存款、取款、借、贷等操作。另外还要提供一个取消操作选项。用户退出这个程序时相关数据应该保存到文件里去(出于备份的目的,程序执行过程中也要备份)。
9-11.Web站点地址。
a) 编写一个URL.书签管理程序。使用基于文本的菜单,用户可以添加、修改或者删除书签数据项、书签数据项中包含站点的名称、URL地址和一行简单说明(可选)。另外提供检索功能,可以根据检索关键字在站点名称和URL两部分查找可能的匹配。程序退出时把数据保存到一个磁盘文件中去;再次执行的时候加载保存的数据。
b) 改进a)的解决方案,把书签输出到一个合法且语法正确的HTML文件(.html或htm)中,这样用户就可以使用浏览器查看自己的书签清单。另外提供创建“文件夹”功能,对相关的书签进行分组管理。
附加题:请阅读Python的re模块了解有关正则表达式的资料,使用正则表达式对用户输入的URL进行验证。
9-12.用户名和密码。
回顾练习7-5,修改代码使之可以支持“上次登录时间”。请参阅time模块中的文档了解如何记录用户上次登录的时间。另外提供一个“系统管理员”,它可以导出所有用户的用户名,密码(如果想要的话,你可以把密码加密),以及“上次登录时间”。
a) 数据应该保存在磁盘中,使用冒号(:)分割,一次写入一行,例如“joe:boohoo:953176591.145”,文件中数据的行数应该等于你系统上的用户数。
b) 进一步改进你的程序,不再一次写入一行,而使用pickle模块保存整个数据对象。请参阅pickle模块的文档了解如何序列化/扁平化对象,以及如何读写保存的对象。一般来说,这个解决方案的代码行数要比a)的少。
c) 使用shelve模块替换pickle模块,由于可以省去一些维护代码,这个解决方案的代码比b)的更少。
9-13.命令行参数
a) 什么是命令行参数,它们有什么用?
b) 写一个程序,打印出所有的命令行参数。
9-14.记录结果,修改你的计算器程序(练习5-6)使之接受命令行参数。例如:
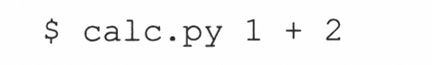
只输出计算结果。另外,把每个表达式和它的结果写入到一个磁盘文件中,当使用下面的命令时。
会把记录的内容显示到屏幕上,然后重置文件。这里是样例展示:

附加题:处理输入时候的注释。
9-15.复制文件。提示输入两个文件名(或者使用命令行参数)。把第一个文件的内容复制到第二个文件中去。
9-16.文本处理。人们输入的文字常常超过屏幕的最大宽度。编写一个程序,在一个文本文件中查找长度大于80个字符的文本行。从最接近80个字符的单词断行,把剩余文件插入到下一行处。程序执行完毕后,应该没有超过80个字符的文本行了。
9-17.文本处理。创建一个原始的文本文件编辑器。你的程序应该是菜单驱动的,有如下这些选项:
1) 创建文件(提示输入文件名和任意行的文本输入);
2) 显示文件(把文件的内容显示到屏幕);
3) 编辑文件(提示输入要修改的行,然后让用户进行修改);
4) 保存文件;
5) 退出。
9-18.搜索文件。提示输入一个字节值(0〜255)和一个文件名。显示该字符在文件中出现的次数。
9-19.创建文件。创建前一个问题的辅助程序。创建一个随机字节的二进制数据文件,但某一特定字节会在文件中出现指定的次数。该程序接受3个参数:
1) 一个字节值(0〜255);
2) 该字符在数据文件中出现的次数;
3) 数据文件的总字节长度。
你的工作就是生成这个文件,把给定的字节随机散布在文件里,并且要求保证给定字符在文件中只出现指定的次数,文件应精确地达到要求的长度。
9-20.压缩文件。写一小段代码,压缩/解压缩gzip或bzip格式的文件。可以使用命令行下的gzip或bzip2和GUI程序PowerArchiver、Stufflt、或WinZip来确认你的Python支持这两个库。
9-21.ZIP归档文件。创建一个程序,可以往ZIP归档文件加入文件,或从中提取文件,有可能的话,加入创建ZIP归档文件的功能。
9-22.ZIP归档文件。unzip-1命令显示出的ZIP归档文件很无趣。创建一个Python脚本lszip.py,使它可以显示额外信息:压缩文件大小,每个文件的压缩比率(通过比较压缩前后文件大小),以及完成的time.ctime()时间戳,而不是只有日期和HH:MM。提示:归档文件的date_time属性并不完整,无法提供给time.mktime()使用…这由你自己决定!
9-23.TAR归档文件。为TAR归档文件建立类似上个问题的程序。这两种文件的不同之处在于ZIP文件通常是压缩的,而TAR文件不是,只是在gzip和bzip2的支持下才能完成压缩工作。加入任意一种压缩格式支持。
附加题:同时支持gzip和bzip2。
9-24.归档文件转换。参考前两个问题的解决方案,写一个程序,在ZIP(.zip)和TAR/gzip(.tgz/.tar.gz)或TAR/bzip2 (.tbz/.tar.bz2)归档文件间移动文件。文件可能是已经存在的,必要时请创建文件。
9-25.通用解压程序。创建一个程序,接受任意数目的归档文件以及一个目标目录作为参数。归档文件格式可以是.zip、.tgz、.tar.gz、.gz、.bz2、.tar.bz2、.tbz中的一种或几种。程序会把第一个归档文件解压后放入目标目录,把其他归档文件解压后放入以对应文件名命名的目录下(不包括扩展名)。例如输入的文件名为header.txt.gz和data.tgz,目录为incoming, header.txt会被解压到incoming而data.tgz中的文件会被放入incoming/data。