
dbscan 基于密度的空间聚类算法
参考文献:百度百科 http://baike.baidu.com
我的算法库:https://github.com/linyiqun/lyq-algorithms-lib
算法介绍
说到聚类算法,大家如果有看过我写的一些关于机器学习的算法文章,一定都这类算法不会陌生,之前将的是划分算法(K均值算法)和层次聚类算法(BIRCH算法),各有优缺点和好坏。本文所述的算法是另外一类的聚类算法,他能够克服BIRCH算法对于形状的限制,因为BIRCH算法偏向于聚簇球形的聚类形成,而dbscan采用的是基于空间的密度的原理,所以可以适用于任何形状的数据聚类实现。
算法原理
在介绍算法原理之前,先介绍几个dbscan算法中的几个概念定义:
Ε领域:给定对象半径为Ε内的区域称为该对象的Ε领域;
核心对象:如果给定对象Ε领域内的样本点数大于等于MinPts,则称该对象为核心对象;
直接密度可达:对于样本集合D,如果样本点q在p的Ε领域内,并且p为核心对象,那么对象q从对象p直接密度可达。
密度可达:对于样本集合D,给定一串样本点p1,p2….pn,p= p1,q= pn,假如对象pi从pi-1直接密度可达,那么对象q从对象p密度可达。
密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联。
下面是算法的过程(可能说的不是很清楚):
1、扫描原始数据,获取所有的数据点。
2、遍历数据点中的每个点,如果此点已经被访问(处理)过,则跳过,否则取出此点做聚类查找。
3、以步骤2中找到的点P为核心对象,找出在E领域内所有满足条件的点,如果个数大于等于MinPts,则此点为核心对象,加入到簇中。
4、再次P为核心对象的簇中的每个点,进行递归的扩增簇。如果P点的递归扩增结束,再次回到步骤2。
5、算法的终止条件为所有的点都被访问(处理过)。
算法可以理解为是一个DFS的深度优先扩展。
算法的实现
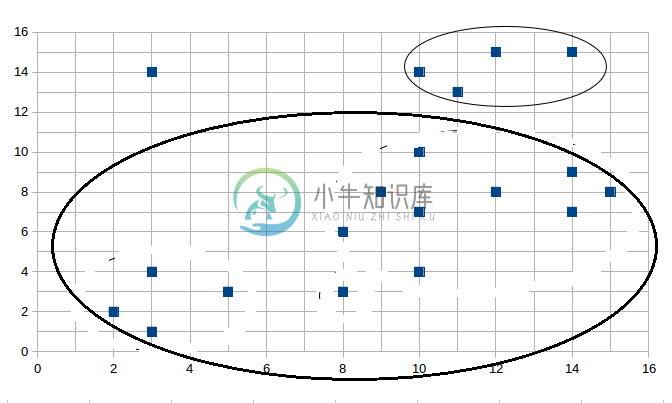
算法的输入Input(格式(x, y)):
2 2
3 1
3 4
3 14
5 3
8 3
8 6
9 8
10 4
10 7
10 10
10 14
11 13
12 8
12 15
14 7
14 9
14 15
15 8
坐标点类Point.java:
package DataMining_DBSCAN;
/**
* 坐标点类
*
* @author lyq
*
*/
public class Point {
// 坐标点横坐标
int x;
// 坐标点纵坐标
int y;
// 此节点是否已经被访问过
boolean isVisited;
public Point(String x, String y) {
this.x = (Integer.parseInt(x));
this.y = (Integer.parseInt(y));
this.isVisited = false;
}
/**
* 计算当前点与制定点之间的欧式距离
*
* @param p
* 待计算聚类的p点
* @return
*/
public double ouDistance(Point p) {
double distance = 0;
distance = (this.x - p.x) * (this.x - p.x) + (this.y - p.y)
* (this.y - p.y);
distance = Math.sqrt(distance);
return distance;
}
/**
* 判断2个坐标点是否为用个坐标点
*
* @param p
* 待比较坐标点
* @return
*/
public boolean isTheSame(Point p) {
boolean isSamed = false;
if (this.x == p.x && this.y == p.y) {
isSamed = true;
}
return isSamed;
}
}package DataMining_DBSCAN;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.text.MessageFormat;
import java.util.ArrayList;
/**
* DBSCAN基于密度聚类算法工具类
*
* @author lyq
*
*/
public class DBSCANTool {
// 测试数据文件地址
private String filePath;
// 簇扫描半径
private double eps;
// 最小包含点数阈值
private int minPts;
// 所有的数据坐标点
private ArrayList<Point> totalPoints;
// 聚簇结果
private ArrayList<ArrayList<Point>> resultClusters;
//噪声数据
private ArrayList<Point> noisePoint;
public DBSCANTool(String filePath, double eps, int minPts) {
this.filePath = filePath;
this.eps = eps;
this.minPts = minPts;
readDataFile();
}
/**
* 从文件中读取数据
*/
public void readDataFile() {
File file = new File(filePath);
ArrayList<String[]> dataArray = new ArrayList<String[]>();
try {
BufferedReader in = new BufferedReader(new FileReader(file));
String str;
String[] tempArray;
while ((str = in.readLine()) != null) {
tempArray = str.split(" ");
dataArray.add(tempArray);
}
in.close();
} catch (IOException e) {
e.getStackTrace();
}
Point p;
totalPoints = new ArrayList<>();
for (String[] array : dataArray) {
p = new Point(array[0], array[1]);
totalPoints.add(p);
}
}
/**
* 递归的寻找聚簇
*
* @param pointList
* 当前的点列表
* @param parentCluster
* 父聚簇
*/
private void recursiveCluster(Point point, ArrayList<Point> parentCluster) {
double distance = 0;
ArrayList<Point> cluster;
// 如果已经访问过了,则跳过
if (point.isVisited) {
return;
}
point.isVisited = true;
cluster = new ArrayList<>();
for (Point p2 : totalPoints) {
// 过滤掉自身的坐标点
if (point.isTheSame(p2)) {
continue;
}
distance = point.ouDistance(p2);
if (distance <= eps) {
// 如果聚类小于给定的半径,则加入簇中
cluster.add(p2);
}
}
if (cluster.size() >= minPts) {
// 将自己也加入到聚簇中
cluster.add(point);
// 如果附近的节点个数超过最下值,则加入到父聚簇中,同时去除重复的点
addCluster(parentCluster, cluster);
for (Point p : cluster) {
recursiveCluster(p, parentCluster);
}
}
}
/**
* 往父聚簇中添加局部簇坐标点
*
* @param parentCluster
* 原始父聚簇坐标点
* @param cluster
* 待合并的聚簇
*/
private void addCluster(ArrayList<Point> parentCluster,
ArrayList<Point> cluster) {
boolean isCotained = false;
ArrayList<Point> addPoints = new ArrayList<>();
for (Point p : cluster) {
isCotained = false;
for (Point p2 : parentCluster) {
if (p.isTheSame(p2)) {
isCotained = true;
break;
}
}
if (!isCotained) {
addPoints.add(p);
}
}
parentCluster.addAll(addPoints);
}
/**
* dbScan算法基于密度的聚类
*/
public void dbScanCluster() {
ArrayList<Point> cluster = null;
resultClusters = new ArrayList<>();
noisePoint = new ArrayList<>();
for (Point p : totalPoints) {
if(p.isVisited){
continue;
}
cluster = new ArrayList<>();
recursiveCluster(p, cluster);
if (cluster.size() > 0) {
resultClusters.add(cluster);
}else{
noisePoint.add(p);
}
}
removeFalseNoise();
printClusters();
}
/**
* 移除被错误分类的噪声点数据
*/
private void removeFalseNoise(){
ArrayList<Point> totalCluster = new ArrayList<>();
ArrayList<Point> deletePoints = new ArrayList<>();
//将聚簇合并
for(ArrayList<Point> list: resultClusters){
totalCluster.addAll(list);
}
for(Point p: noisePoint){
for(Point p2: totalCluster){
if(p2.isTheSame(p)){
deletePoints.add(p);
}
}
}
noisePoint.removeAll(deletePoints);
}
/**
* 输出聚类结果
*/
private void printClusters() {
int i = 1;
for (ArrayList<Point> pList : resultClusters) {
System.out.print("聚簇" + (i++) + ":");
for (Point p : pList) {
System.out.print(MessageFormat.format("({0},{1}) ", p.x, p.y));
}
System.out.println();
}
System.out.println();
System.out.print("噪声数据:");
for (Point p : noisePoint) {
System.out.print(MessageFormat.format("({0},{1}) ", p.x, p.y));
}
System.out.println();
}
}
package DataMining_DBSCAN;
/**
* Dbscan基于密度的聚类算法测试类
* @author lyq
*
*/
public class Client {
public static void main(String[] args){
String filePath = "C:\\Users\\lyq\\Desktop\\icon\\input.txt";
//簇扫描半径
double eps = 3;
//最小包含点数阈值
int minPts = 3;
DBSCANTool tool = new DBSCANTool(filePath, eps, minPts);
tool.dbScanCluster();
}
}
聚簇1:(2,2) (3,4) (5,3) (3,1) (8,3) (8,6) (10,4) (9,8) (10,7) (10,10) (12,8) (14,7) (14,9) (15,8)
聚簇2:(10,14) (11,13) (14,15) (12,15)
噪声数据:(3,14)
算法的缺点
dbscan虽说可以用于任何形状的聚类发现,但是对于密度分布不均衡的数据,变化比较大,分类的性能就不会特别好,还有1点是不能反映高尺寸数据。