
为基于KMeans的聚类算法创建条形图的问题

我正在努力为基于KMeans的聚类算法绘制条形图。问题是我想用这样一种方式来演示集群,即非常离群的集群可以在x轴的末端进行描述
---|---|---|-----------------> x-axis
0 1 2 3
在这种情况下,我想说明,例如,根据距离有点远的分数,使用标记为3的聚类预测,需要对箱子宽度进行一些调整,可能如下所示:
---|---|--------------|------> x-axis
0 1 2 3
from sklearn.cluster import KMeans
import seaborn as sns
import numpy as np
from pandas import DataFrame
from math import pow
import math
class ODKM:
def __init__(self,n_clusters=15,effectiveness=500,max_iter=2):
self.n_clusters=n_clusters
self.effectiveness=effectiveness
self.max_iter=max_iter
self.kmeans = {}
self.cluster_score = {}
#self.labels = {}
def fit(self, data):
length = len(data)
for column in data.columns:
kmeans = KMeans(n_clusters=self.n_clusters,max_iter=self.max_iter)
self.kmeans[column]=kmeans
kmeans.fit(data[column].values.reshape(-1,1))
assign = DataFrame(kmeans.predict(data[column].values.reshape(-1,1)),columns=['cluster'])
cluster_score=assign.groupby('cluster').apply(len).apply(lambda x:x/length)
ratio=cluster_score.copy()
sorted_centers = sorted(kmeans.cluster_centers_)
max_distance = ( sorted_centers[-1] - sorted_centers[0] )[ 0 ]
for i in range(self.n_clusters):
for k in range(self.n_clusters):
if i != k:
dist = abs(kmeans.cluster_centers_[i] - kmeans.cluster_centers_[k])/max_distance
effect = ratio[k]*(1/pow(self.effectiveness,dist))
cluster_score[i] = cluster_score[i]+effect
self.cluster_score[column] = cluster_score
def predict(self, data):
length = len(data)
score_array = np.zeros(length)
for column in data.columns:
kmeans = self.kmeans[ column ]
cluster_score = self.cluster_score[ column ]
#labels = kmeans.labels_
assign = kmeans.predict( data[ column ].values.reshape(-1,1) )
#print(assign)
for i in range(length):
score_array[i] = score_array[i] + math.log10( cluster_score[assign[i]] )
return score_array #,labels
def fit_predict(self,data):
self.fit(data)
return self.predict(data)
测试结果:
import pandas as pd
df = pd.DataFrame(data={'attr1':[1,1,1,1,2,2,2,2,2,2,2,2,3,5,5,6,6,7,7,7,7,7,7,7,15],
'attr2':[1,1,1,1,2,2,2,2,2,2,2,2,3,5,5,6,6,7,7,7,13,13,13,14,15]})
#generate score from KM-based algorithm via class ODKM
odkm_model = ODKM(n_clusters=3, max_iter=1)
result = odkm_model.fit_predict(df)
#include generated scores to the main frame to reach desired plot
df['ODKM_Score']= result
df
#for i in result:
# print(round(i,2))
#results
#-0.51, -0.51 , -0.51 , -0.51, -0.51, -0.51, -0.51, -0.51, -0.51, -0.51, -0.51, -0.51, -0.51
#-0.78, -0.78, -0.78, -0.78, -0.78, -0.78, -0.78
#-0.99, -0.99, -0.99, -0.99
#-1.99
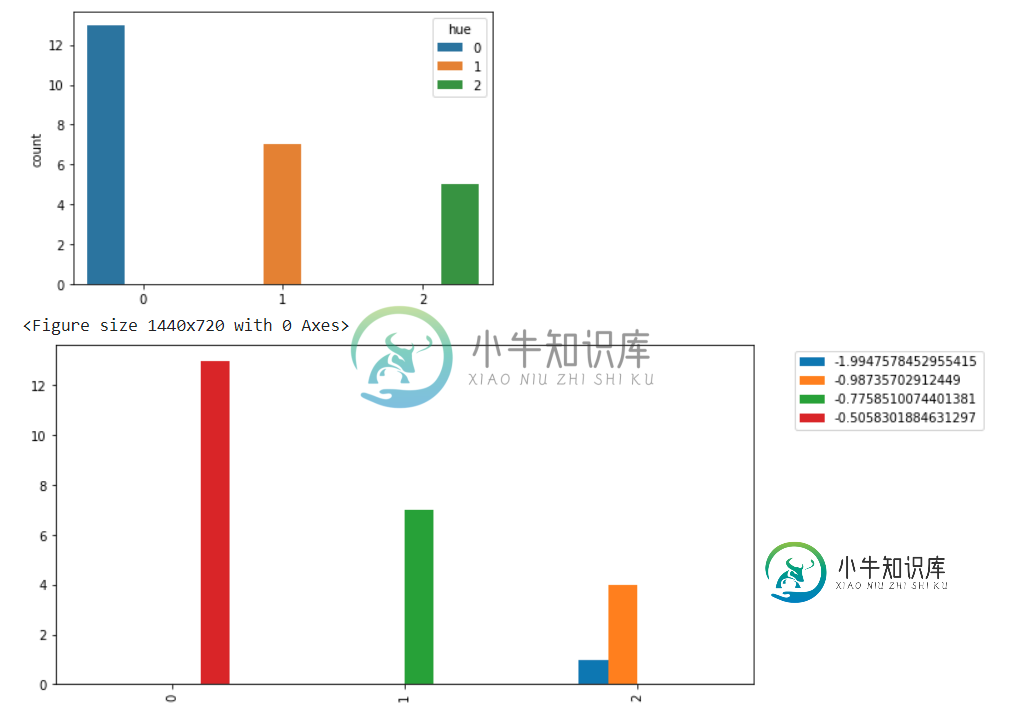
你可以在colab笔记本中找到我的整个代码,包括这个基于KM的算法,以便快速调试。如果您需要,请随时在笔记本上实现您的解决方案或在单元格上发表评论,或者在ODKM算法本身(KM集群执行的地方)内的一些更改已经脚本化,可以以@class ODKM的形式访问。也许最好提取预测的群集标签,并在ODKM算法Score旁边的Cluster_label标题下添加一个新列,以便更好地访问条形图。
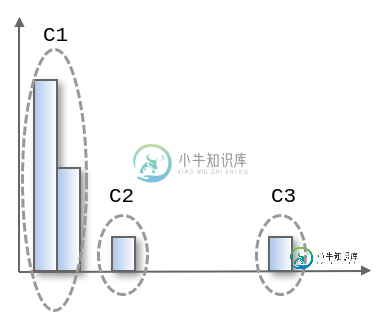
预期的输出应该是这样的(相同集群中的更好的垃圾箱具有相同的颜色,例如第一个集群C1):
更新:除了条形图解决方案外,我还可以绘制历史
##left output
# just plot 'Score' column (not all columsn in 1st phase) to simply the problem
#cols_ = df.columns[-1:]
ax1 = plt.subplot2grid((1,1), (0,0))
df['Score'].plot(kind='hist', ax=ax1 , color='b', alpha=0.4)
df['Score'].plot(kind='kde', ax=ax1, secondary_y=True, label='distribution', color='b', lw=2)
##Right output
sns.distplot(df['Score'] , color='b')
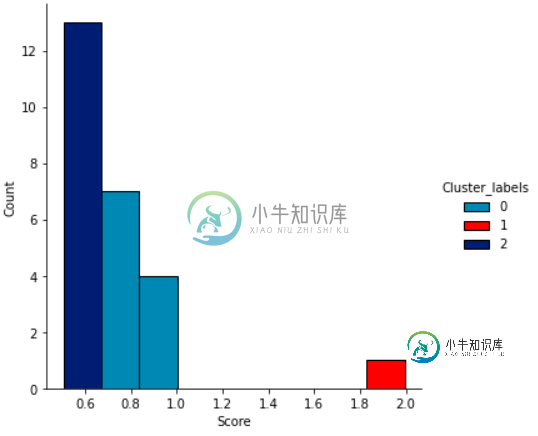
尽管在图表上反映了聚类结果,但我注意到,正如我在下图中强调的,这两个图之间存在一些差异,例如y轴的比例

我也找到了这篇文章,但是我不能适应@class ODKM来动态解决我的问题。我最近也可以实现这一点:
df['Score'] = df['Score'].abs()
sns.displot(df,
x='Score',
hue='Cluster_labels',
palette=["#00f0f0","#ff0000","#00ff00"],
alpha=1)
共有2个答案

import pandas as pd
df = pd.DataFrame(data={'attr1':[1,1,1,1,2,2,2,2,2,2,2,2,3,5,5,6,6,7,7,7,7,7,7,7,15],
'attr2':[1,1,1,1,2,2,2,2,2,2,2,2,3,5,5,6,6,7,7,7,13,13,13,14,15]
})
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
def kmeans_scatterplot(df):
column_i = 'attr1'
column_j = 'attr2'
df_temp = df[[column_i, column_j]]
# model
y_pred = DBSCAN(eps = 3, min_samples = 1).fit_predict(df_temp)
# plot
plt.scatter(df_temp[column_i], df_temp[column_j], c=y_pred, cmap='rainbow', alpha=0.7, edgecolors='b')
plt.show()
kmeans_scatterplot(df)
这个聚类只需要指定距离,然后我们就可以根据类别标注颜色了。
它将帮助您快速理解此算法的原理:https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/

对于1D情况,可以使用簇的中心作为条形图的x位置。
n_clusters=3
km = KMeans(init='k-means++', n_clusters=n_clusters).fit(df[['Score']])
counts = np.bincount(km.labels_)
for center, count, label in zip(km.cluster_centers_, counts, range(n_clusters)):
print(center, count)
plt.bar(center, count, width=0.2, label=label)
-
算法介绍 K-Means又名为K均值算法,他是一个聚类算法,这里的K就是聚簇中心的个数,代表数据中存在多少数据簇。K-Means在聚类算法中算是非常简单的一个算法了。有点类似于KNN算法,都用到了距离矢量度量,用欧式距离作为小分类的标准。 算法步骤 (1)、设定数字k,从n个初始数据中随机的设置k个点为聚类中心点。 (2)、针对n个点的每个数据点,遍历计算到k个聚类中心点的距离,最后按照离哪个中心
-
我试图为数据集创建多水平条形图。这些数据涉及跑步比赛的比赛时间。 Dataframe有以下列:名称、年龄组、完成时间、完成地点、家乡。下面是示例数据。 我想创建一个类似下图的条形图。每个年龄组将有一个条形图,最快的跑步者在图表的底部,跑步者的名字与城市和次数跑了比赛低于他们的名字。 我需要一个for循环还是一个简单的groupby工作?每个年龄组的数量和大小可以根据种族动态变化,因此它不是一个常数
-
本文向大家介绍Python实现Kmeans聚类算法,包括了Python实现Kmeans聚类算法的使用技巧和注意事项,需要的朋友参考一下 本节内容:本节内容是根据上学期所上的模式识别课程的作业整理而来,第一道题目是Kmeans聚类算法,数据集是Iris(鸢尾花的数据集),分类数k是3,数据维数是4。 关于聚类 聚类算法是这样的一种算法:给定样本数据Sample,要求将样本Sample中相似的
-
参考文献:基于连通图动态分裂的聚类算法.作者:邓健爽 郑启伦 彭宏 邓维维(华南理工大学计算机科学与工程学院,广东广州510640) 我的算法库:https://github.com/linyiqun/lyq-algorithms-lib 算法介绍 从文章的标题可以看出,今天我所介绍的算法又是一个聚类算法,不过他比较特殊,用到了图方面的知识,而且是一种动态的算法,与BIRCH算法一样,他也是一种
-
参考文献:百度百科 http://baike.baidu.com 我的算法库:https://github.com/linyiqun/lyq-algorithms-lib 算法介绍 说到聚类算法,大家如果有看过我写的一些关于机器学习的算法文章,一定都这类算法不会陌生,之前将的是划分算法(K均值算法)和层次聚类算法(BIRCH算法),各有优缺点和好坏。本文所述的算法是另外一类的聚类算法,他能够克服
-
问题内容: 在以下将节点映射到颜色的字典中,我想绘制结果图,同时根据其颜色在图中的节点上聚类。也就是说,如果节点和 有深红色,我希望他们下一步彼此在图表上显示。 我的字典如下: 具有以下边缘(以上字典中的键): 如果我尝试正常绘制图形,则会得到随机位置: 有没有一种方法可以绘制此图,并根据nodesWithGroup词典中的值对节点进行分组。我尝试应用此问题中描述的方法,但是我不知道如何应用逻辑。