
Apriori 算法 关联规则挖掘
我的数据挖掘算法代码:https://github.com/linyiqun/DataMiningAlgorithm
介绍
Apriori算法是一个经典的数据挖掘算法,Apriori的单词的意思是"先验的",说明这个算法是具有先验性质的,就是说要通过上一次的结果推导出下一次的结果,这个如何体现将会在下面的分析中会慢慢的体现出来。Apriori算法的用处是挖掘频繁项集的,频繁项集粗俗的理解就是找出经常出现的组合,然后根据这些组合最终推出我们的关联规则。
Apriori算法原理
Apriori算法是一种逐层搜索的迭代式算法,其中k项集用于挖掘(k+1)项集,这是依靠他的先验性质的:
频繁项集的所有非空子集一定是也是频繁的。
通过这个性质可以对候选集进行剪枝。用k项集如何生成(k+1)项集呢,这个是算法里面最难也是最核心的部分。
通过2个步骤
1、连接步,将频繁项自己与自己进行连接运算。
2、剪枝步,去除候选集项中的不符合要求的候选项,不符合要求指的是这个候选项的子集并非都是频繁项,要遵守上文提到的先验性质。
3、通过1,2步骤还不够,在后面还要根据支持度计数筛选掉不满足最小支持度数的候选集。
算法实例
首先是测试数据:
交易ID | 商品ID列表 |
T100 | I1,I2,I5 |
T200 | I2,I4 |
T300 | I2,I3 |
T400 | I1,I2,I4 |
T500 | I1,I3 |
T600 | I2,I3 |
T700 | I1,I3 |
T800 | I1,I2,I3,I5 |
T900 | I1,I2,I3 |
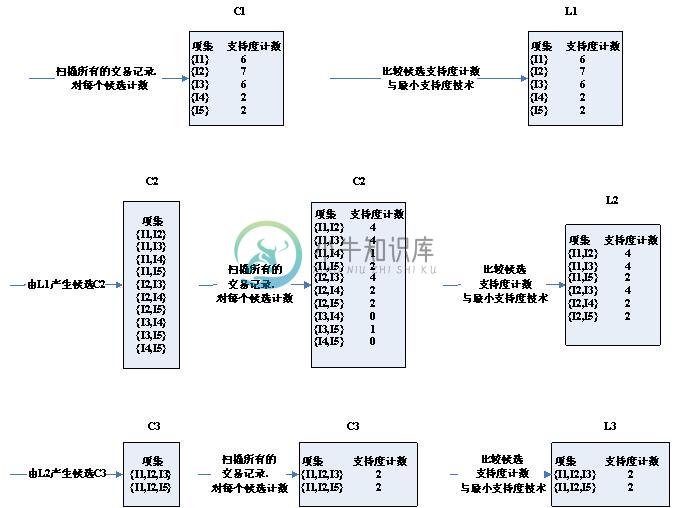
最后我们可以看到频繁3项集的结果为{1, 2, 3}和{1, 2, 5},然后我们去后者{1, 2, 5}作为频繁项集来生产他的关联规则,但是在这之前得先知道一些概念,怎么样才能够成为一条关联规则,关有频繁项集还是不够的。
关联规则
confidence(置信度)
confidence的中文意思为自信的,在这里其实表示的是一种条件概率,当在A条件下,B发生的概率就可以表示为confidence(A->B)=p(B|A),意为在A的情况下,推出B的概率。那么关联规则与有什么关系呢,请继续往下看。最小置信度阈值
按照字面上的意思就是限制置信度值的一个限制条件嘛,这个很好理解。
强规则
强规则就是指的是置信度满足最小置信度(就是>=最小置信度)的推断就是一个强规则,也就是文中所说的关联规则了。这个在下面的程序中会有所体现。
算法的代码实现
我自己写的算法实现可能会让你有点晦涩难懂,不过重在理解算法的整个思路即可,尤其是连接步和剪枝步是最难点所在,可能还存在bug。
输入数据:
T1 1 2 5
T2 2 4
T3 2 3
T4 1 2 4
T5 1 3
T6 2 3
T7 1 3
T8 1 2 3 5
T9 1 2 3/**
* 频繁项集
*
* @author lyq
*
*/
public class FrequentItem implements Comparable<FrequentItem>{
// 频繁项集的集合ID
private String[] idArray;
// 频繁项集的支持度计数
private int count;
//频繁项集的长度,1项集或是2项集,亦或是3项集
private int length;
public FrequentItem(String[] idArray, int count){
this.idArray = idArray;
this.count = count;
length = idArray.length;
}
public String[] getIdArray() {
return idArray;
}
public void setIdArray(String[] idArray) {
this.idArray = idArray;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public int getLength() {
return length;
}
public void setLength(int length) {
this.length = length;
}
@Override
public int compareTo(FrequentItem o) {
// TODO Auto-generated method stub
return this.getIdArray()[0].compareTo(o.getIdArray()[0]);
}
}
package DataMining_Apriori;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.text.MessageFormat;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
/**
* apriori算法工具类
*
* @author lyq
*
*/
public class AprioriTool {
// 最小支持度计数
private int minSupportCount;
// 测试数据文件地址
private String filePath;
// 每个事务中的商品ID
private ArrayList<String[]> totalGoodsIDs;
// 过程中计算出来的所有频繁项集列表
private ArrayList<FrequentItem> resultItem;
// 过程中计算出来频繁项集的ID集合
private ArrayList<String[]> resultItemID;
public AprioriTool(String filePath, int minSupportCount) {
this.filePath = filePath;
this.minSupportCount = minSupportCount;
readDataFile();
}
/**
* 从文件中读取数据
*/
private void readDataFile() {
File file = new File(filePath);
ArrayList<String[]> dataArray = new ArrayList<String[]>();
try {
BufferedReader in = new BufferedReader(new FileReader(file));
String str;
String[] tempArray;
while ((str = in.readLine()) != null) {
tempArray = str.split(" ");
dataArray.add(tempArray);
}
in.close();
} catch (IOException e) {
e.getStackTrace();
}
String[] temp = null;
totalGoodsIDs = new ArrayList<>();
for (String[] array : dataArray) {
temp = new String[array.length - 1];
System.arraycopy(array, 1, temp, 0, array.length - 1);
// 将事务ID加入列表吧中
totalGoodsIDs.add(temp);
}
}
/**
* 判读字符数组array2是否包含于数组array1中
*
* @param array1
* @param array2
* @return
*/
public boolean iSStrContain(String[] array1, String[] array2) {
if (array1 == null || array2 == null) {
return false;
}
boolean iSContain = false;
for (String s : array2) {
// 新的字母比较时,重新初始化变量
iSContain = false;
// 判读array2中每个字符,只要包括在array1中 ,就算包含
for (String s2 : array1) {
if (s.equals(s2)) {
iSContain = true;
break;
}
}
// 如果已经判断出不包含了,则直接中断循环
if (!iSContain) {
break;
}
}
return iSContain;
}
/**
* 项集进行连接运算
*/
private void computeLink() {
// 连接计算的终止数,k项集必须算到k-1子项集为止
int endNum = 0;
// 当前已经进行连接运算到几项集,开始时就是1项集
int currentNum = 1;
// 商品,1频繁项集映射图
HashMap<String, FrequentItem> itemMap = new HashMap<>();
FrequentItem tempItem;
// 初始列表
ArrayList<FrequentItem> list = new ArrayList<>();
// 经过连接运算后产生的结果项集
resultItem = new ArrayList<>();
resultItemID = new ArrayList<>();
// 商品ID的种类
ArrayList<String> idType = new ArrayList<>();
for (String[] a : totalGoodsIDs) {
for (String s : a) {
if (!idType.contains(s)) {
tempItem = new FrequentItem(new String[] { s }, 1);
idType.add(s);
resultItemID.add(new String[] { s });
} else {
// 支持度计数加1
tempItem = itemMap.get(s);
tempItem.setCount(tempItem.getCount() + 1);
}
itemMap.put(s, tempItem);
}
}
// 将初始频繁项集转入到列表中,以便继续做连接运算
for (Map.Entry entry : itemMap.entrySet()) {
list.add((FrequentItem) entry.getValue());
}
// 按照商品ID进行排序,否则连接计算结果将会不一致,将会减少
Collections.sort(list);
resultItem.addAll(list);
String[] array1;
String[] array2;
String[] resultArray;
ArrayList<String> tempIds;
ArrayList<String[]> resultContainer;
// 总共要算到endNum项集
endNum = list.size() - 1;
while (currentNum < endNum) {
resultContainer = new ArrayList<>();
for (int i = 0; i < list.size() - 1; i++) {
tempItem = list.get(i);
array1 = tempItem.getIdArray();
for (int j = i + 1; j < list.size(); j++) {
tempIds = new ArrayList<>();
array2 = list.get(j).getIdArray();
for (int k = 0; k < array1.length; k++) {
// 如果对应位置上的值相等的时候,只取其中一个值,做了一个连接删除操作
if (array1[k].equals(array2[k])) {
tempIds.add(array1[k]);
} else {
tempIds.add(array1[k]);
tempIds.add(array2[k]);
}
}
resultArray = new String[tempIds.size()];
tempIds.toArray(resultArray);
boolean isContain = false;
// 过滤不符合条件的的ID数组,包括重复的和长度不符合要求的
if (resultArray.length == (array1.length + 1)) {
isContain = isIDArrayContains(resultContainer,
resultArray);
if (!isContain) {
resultContainer.add(resultArray);
}
}
}
}
// 做频繁项集的剪枝处理,必须保证新的频繁项集的子项集也必须是频繁项集
list = cutItem(resultContainer);
currentNum++;
}
// 输出频繁项集
for (int k = 1; k <= currentNum; k++) {
System.out.println("频繁" + k + "项集:");
for (FrequentItem i : resultItem) {
if (i.getLength() == k) {
System.out.print("{");
for (String t : i.getIdArray()) {
System.out.print(t + ",");
}
System.out.print("},");
}
}
System.out.println();
}
}
/**
* 判断列表结果中是否已经包含此数组
*
* @param container
* ID数组容器
* @param array
* 待比较数组
* @return
*/
private boolean isIDArrayContains(ArrayList<String[]> container,
String[] array) {
boolean isContain = true;
if (container.size() == 0) {
isContain = false;
return isContain;
}
for (String[] s : container) {
// 比较的视乎必须保证长度一样
if (s.length != array.length) {
continue;
}
isContain = true;
for (int i = 0; i < s.length; i++) {
// 只要有一个id不等,就算不相等
if (s[i] != array[i]) {
isContain = false;
break;
}
}
// 如果已经判断是包含在容器中时,直接退出
if (isContain) {
break;
}
}
return isContain;
}
/**
* 对频繁项集做剪枝步骤,必须保证新的频繁项集的子项集也必须是频繁项集
*/
private ArrayList<FrequentItem> cutItem(ArrayList<String[]> resultIds) {
String[] temp;
// 忽略的索引位置,以此构建子集
int igNoreIndex = 0;
FrequentItem tempItem;
// 剪枝生成新的频繁项集
ArrayList<FrequentItem> newItem = new ArrayList<>();
// 不符合要求的id
ArrayList<String[]> deleteIdArray = new ArrayList<>();
// 子项集是否也为频繁子项集
boolean isContain = true;
for (String[] array : resultIds) {
// 列举出其中的一个个的子项集,判断存在于频繁项集列表中
temp = new String[array.length - 1];
for (igNoreIndex = 0; igNoreIndex < array.length; igNoreIndex++) {
isContain = true;
for (int j = 0, k = 0; j < array.length; j++) {
if (j != igNoreIndex) {
temp[k] = array[j];
k++;
}
}
if (!isIDArrayContains(resultItemID, temp)) {
isContain = false;
break;
}
}
if (!isContain) {
deleteIdArray.add(array);
}
}
// 移除不符合条件的ID组合
resultIds.removeAll(deleteIdArray);
// 移除支持度计数不够的id集合
int tempCount = 0;
for (String[] array : resultIds) {
tempCount = 0;
for (String[] array2 : totalGoodsIDs) {
if (isStrArrayContain(array2, array)) {
tempCount++;
}
}
// 如果支持度计数大于等于最小最小支持度计数则生成新的频繁项集,并加入结果集中
if (tempCount >= minSupportCount) {
tempItem = new FrequentItem(array, tempCount);
newItem.add(tempItem);
resultItemID.add(array);
resultItem.add(tempItem);
}
}
return newItem;
}
/**
* 数组array2是否包含于array1中,不需要完全一样
*
* @param array1
* @param array2
* @return
*/
private boolean isStrArrayContain(String[] array1, String[] array2) {
boolean isContain = true;
for (String s2 : array2) {
isContain = false;
for (String s1 : array1) {
// 只要s2字符存在于array1中,这个字符就算包含在array1中
if (s2.equals(s1)) {
isContain = true;
break;
}
}
// 一旦发现不包含的字符,则array2数组不包含于array1中
if (!isContain) {
break;
}
}
return isContain;
}
/**
* 根据产生的频繁项集输出关联规则
*
* @param minConf
* 最小置信度阈值
*/
public void printAttachRule(double minConf) {
// 进行连接和剪枝操作
computeLink();
int count1 = 0;
int count2 = 0;
ArrayList<String> childGroup1;
ArrayList<String> childGroup2;
String[] group1;
String[] group2;
// 以最后一个频繁项集做关联规则的输出
String[] array = resultItem.get(resultItem.size() - 1).getIdArray();
// 子集总数,计算的时候除去自身和空集
int totalNum = (int) Math.pow(2, array.length);
String[] temp;
// 二进制数组,用来代表各个子集
int[] binaryArray;
// 除去头和尾部
for (int i = 1; i < totalNum - 1; i++) {
binaryArray = new int[array.length];
numToBinaryArray(binaryArray, i);
childGroup1 = new ArrayList<>();
childGroup2 = new ArrayList<>();
count1 = 0;
count2 = 0;
// 按照二进制位关系取出子集
for (int j = 0; j < binaryArray.length; j++) {
if (binaryArray[j] == 1) {
childGroup1.add(array[j]);
} else {
childGroup2.add(array[j]);
}
}
group1 = new String[childGroup1.size()];
group2 = new String[childGroup2.size()];
childGroup1.toArray(group1);
childGroup2.toArray(group2);
for (String[] a : totalGoodsIDs) {
if (isStrArrayContain(a, group1)) {
count1++;
// 在group1的条件下,统计group2的事件发生次数
if (isStrArrayContain(a, group2)) {
count2++;
}
}
}
// {A}-->{B}的意思为在A的情况下发生B的概率
System.out.print("{");
for (String s : group1) {
System.out.print(s + ", ");
}
System.out.print("}-->");
System.out.print("{");
for (String s : group2) {
System.out.print(s + ", ");
}
System.out.print(MessageFormat.format(
"},confidence(置信度):{0}/{1}={2}", count2, count1, count2
* 1.0 / count1));
if (count2 * 1.0 / count1 < minConf) {
// 不符合要求,不是强规则
System.out.println("由于此规则置信度未达到最小置信度的要求,不是强规则");
} else {
System.out.println("为强规则");
}
}
}
/**
* 数字转为二进制形式
*
* @param binaryArray
* 转化后的二进制数组形式
* @param num
* 待转化数字
*/
private void numToBinaryArray(int[] binaryArray, int num) {
int index = 0;
while (num != 0) {
binaryArray[index] = num % 2;
index++;
num /= 2;
}
}
}
/**
* apriori关联规则挖掘算法调用类
* @author lyq
*
*/
public class Client {
public static void main(String[] args){
String filePath = "C:\\Users\\lyq\\Desktop\\icon\\testInput.txt";
AprioriTool tool = new AprioriTool(filePath, 2);
tool.printAttachRule(0.7);
}
}频繁1项集:
{1,},{2,},{3,},{4,},{5,},
频繁2项集:
{1,2,},{1,3,},{1,5,},{2,3,},{2,4,},{2,5,},
频繁3项集:
{1,2,3,},{1,2,5,},
频繁4项集:
{1, }-->{2, 5, },confidence(置信度):2/6=0.333由于此规则置信度未达到最小置信度的要求,不是强规则
{2, }-->{1, 5, },confidence(置信度):2/7=0.286由于此规则置信度未达到最小置信度的要求,不是强规则
{1, 2, }-->{5, },confidence(置信度):2/4=0.5由于此规则置信度未达到最小置信度的要求,不是强规则
{5, }-->{1, 2, },confidence(置信度):2/2=1为强规则
{1, 5, }-->{2, },confidence(置信度):2/2=1为强规则
{2, 5, }-->{1, },confidence(置信度):2/2=1为强规则程序算法的问题和技巧
在实现Apiori算法的时候,碰到的一些问题和待优化的点特别要提一下:
1、首先程序的运行效率不高,里面有大量的for嵌套循环叠加上循环,当然这有本身算法的原因(连接运算所致)还有我的各个的方法选择,很多一部分用来比较字符串数组。
2、这个是我觉得会是程序的一个漏洞,当生成的候选项集加入resultItemId时,会出现{1, 2, 3}和{3, 2, 1}会被当成不同的侯选集,未做顺序的判断。
3、程序的调试过程中由于未按照从小到大的排序,导致,生成的候选集与真实值不一致的情况,所以这里必须在频繁1项集的时候就应该是有序的。
4、在输出关联规则的时候,用到了数字转二进制数组的形式,输出他的各个非空子集,然后最出关联规则的判断。
Apriori算法的缺点
此算法的的应用非常广泛,但是他在运算的过程中会产生大量的侯选集,而且在匹配的时候要进行整个数据库的扫描,因为要做支持度计数的统计操作,在小规模的数据上操作还不会有大问题,如果是大型的数据库上呢,他的效率还是有待提高的。