《集群化》专题
-
如何基于String的值对节点集群进行分片?
我想创建一个分布式系统,其中数据在所有节点上分片。我知道有像Hazelcast或Apache Ignite这样的库为您做这些工作。在我的例子中,对于每个分片密钥,我需要创建一个到另一个系统的套接字订阅,所以这不仅仅是关于如何分发数据,还包括如何以分布式的方式实际创建这些订阅。 其思想是为每个分片密钥创建对另一个系统的订阅。每个订阅都将保留一个条目列表,其中包含用于检查来自套接字连接的每个更新的数据
-
配置ElasticSearch Magento 2.4-在集群中找不到活动节点
尝试在magento 2.4中搜索产品时返回以下错误 异常#0(Elasticsearch\Common\Exceptions\NoNodes可用性异常):在集群中找不到活动节点 以下配置: PHP 7.4.1 Nginx 1.14 MySql 8 ElasticSearch 7.9 /etc/nginx/conf.d/100-magento2.conf /etc/nginx/conf.d/90-
-
服务Fabric群集。Statefull服务。服务总线队列使用
-
如何在Spark独立集群模式下访问HDFS文件?
抛出错误 到目前为止,我在Hadoop中只有start-dfs.sh,在Spark中并没有真正配置任何内容。我是否需要使用YARN集群管理器来运行Spark,以便Spark和Hadoop使用相同的集群管理器,从而可以访问HDFS文件? 我尝试按照tutorialspoint https://www.tutorialspoint.com/Hadoop/hadoop_enviornment_setup
-
无法从Java应用程序连接到本地spark集群
我试图运行一个连接到本地独立spark集群的java应用程序。我使用start-all.sh以默认配置启动集群。当我转到集群的web页面时,它被启动为OK。我可以用SparkR连接到这个集群,但是当我使用相同的主URL从Java内部连接时,我会得到一条错误消息。 下面是Spark日志中的输出:
-
无法使用kubectl管理集群-“无法协商api版本”
在通过云控制台创建集群后,我试图在本地使用kubectl,但总是出现错误。以下是我采取的步骤: 通过云控制台 下面是kubectl版本的输出 客户端版本:version.info{Major:“1”,Minor:“3”,gitversion:“v1.3.5”,gitcommit:“b0deb2eb8f4037421077f77cb163dbb4c0a2a9f5”,gittreeste:“clean
-
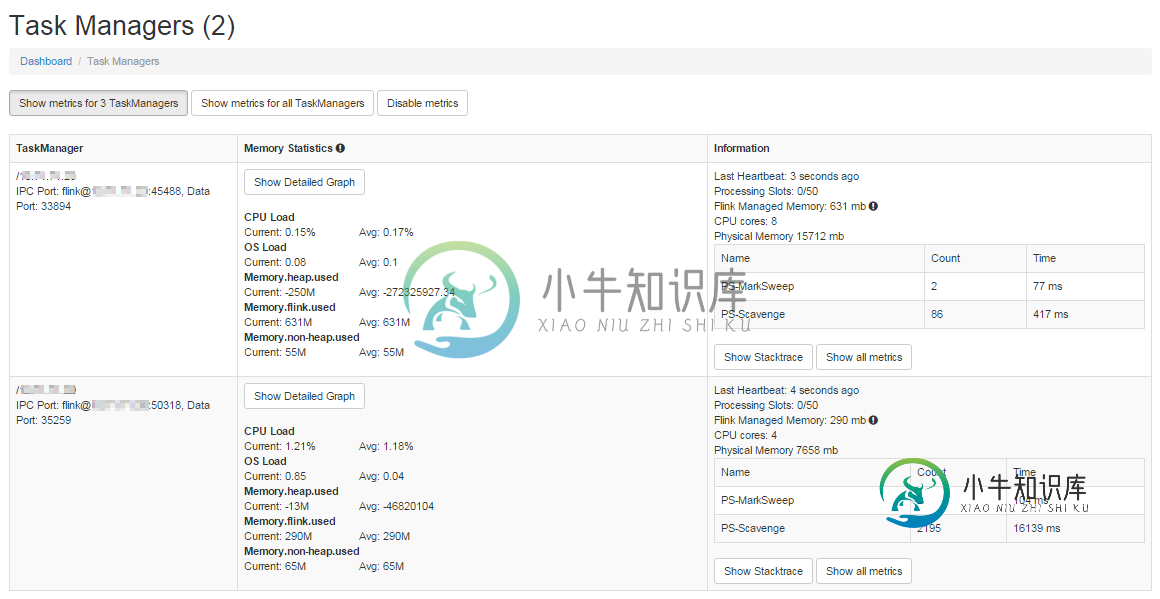 集群中的Apache Flink流不会与工人拆分作业
集群中的Apache Flink流不会与工人拆分作业我的目标是使用Kafka作为源设置一个高吞吐量集群 我在主服务器和辅助服务器上设置了一个2节点集群,配置如下。 flink-conf.yaml大师 Worker flink-conf.yaml 主节点上的文件如下所示: 两个节点上的 flink 设置位于具有相同名称的文件夹中。我通过运行 这将启动Worker节点上的任务管理器。 我的输入源是Kafka。以下是片段。 这是我的水槽功能 这是我的po
-
如何优雅地更新形成Hazelcast集群组的ECS-service?
我们有一个ECS-service(EC2 ECS),有几个任务组成一个Hazelcast集群组(Hazelcast:3.10.6,HazelCast-AWS:2.2,我们使用Hazelcast在分布式对象中存储一些共享数据和锁)。它使用滚动服务更新,最小健康百分比设置为100,最大值设置为200。 用新的任务定义更新这个服务并不是很可靠--通常由于ECS的服务更新过程的性质,Hazelcast不能
-
无法在3 HA群集架构上使用相同的clientId
我使用的是ActiveMQ Artemis集群,由3个代理(1个主代理,2个从代理)组成,使用UDP广播设置。 ActiveMQ Artemis按预期启动,但是当尝试使用SAG webMethods创建JMS连接时,它返回错误: null ActiveMQ Artemis支持JMS2.0,多个客户端指向同一个ClientID/目的地应该是可能的,对吗?它允许共享订阅。 我在这里错过了什么?我根本没
-
hadoop多节点群集-从节点无法执行mapreduce任务
jps输出正确: 在主机上: 在5个从节点上:
-
密钥斗篷独立集群配置是否需要仲裁?
据说KeyClope构建在WildFly应用服务器及其子项目Infinispan(用于缓存)和Hibernate(用于持久性)之上。 Keycloak 建议查看 WildFly 文档和高可用性指南。 如果理解正确,独立群集配置允许在群集周围进行SSO上下文的会话复制或传输。 我不明白是否需要奇数个密钥保护节点才能达到仲裁。 单子系统状态 10.1.3.Quorum网络分区对于单例服务来说尤其成问题
-
active-mq artemis springboot集群主题负载平衡(循环)问题
在花费大量时间配置和尝试大量解决方案使Artemis在集群模式下工作之后,就像发布-订阅(主题)中的本地模式一样。因此,我在不同的节点上准备了3个消费者和一个只在一个节点上发布消息的生产者。我希望3个消费者收到他们自己的消息副本,如在这里所描述的! 问题是集群(核心桥)仍然在3个节点之间循环消息。 我的项目Github回购 spring-boot-artemis-clustered-topic 代
-
无法在Apache Storm群集中使用远程从属节点
我在跟踪http://jayatiatblogs.blogspot.com/2011/11/storm-installation.html尝试在Amazon Web服务上使用带有Ubuntu14.04 LTS的少数虚拟机(EC2)配置Apache Storm远程集群。 我的主节点是10.0.0.230,从节点是10.0.0.79。我的zookeeper位于我的主节点中。当我使用storm-jar-
-
基于 Akka 集群的微服务 API 网关模式实现
我尝试基于Akka创建一些使用CQRS的微服务。所以我的微服务有Httpendpoint的写端(向集群发送命令)和读端(从数据库读取投影),但这不是主要问题。由于许多微服务,问题出现了为客户端收集复杂的API。我找到了答案:API网关模式。但我还有下一个问题:如何实现它? > < li> 我可以创建单独的项目,该项目将实现API网关模式(在简单的情况下,它是一个反向代理)。完整堆栈将: 赞成的意见
-
Cassandra集群的插入性能和插入稳定性较差
我必须为每个客户端每秒存储大约250个数值,即每小时大约90万个数字。它可能不会是全天的记录(可能每天5-10个小时),但我会根据客户端ID和读取日期对数据进行分区。最大行长约为22-23M,这仍然是可管理的。无论如何,我的方案看起来像这样: 密钥空间的复制因子为2,仅用于测试,告密者为和。我知道复制因子3更符合生产标准。 接下来,我在公司服务器上创建了一个小型集群,三台裸机虚拟化机器,具有2个C