《集群化》专题
-
扩展Docker群集群中Uber节奏的匹配服务后,获得大量决策任务超时
我正在尝试独立运行每个节奏服务,这样我就可以轻松地扩展它们。我的团队正在使用docker群,我们使用Portainer UI管理一切。到目前为止,我已经能够扩展前端服务以拥有两个副本,但是如果我对匹配的服务做同样的事情,我将通过工作流执行获得大量的。最终,执行将成功完成,但需要很长时间。要想有一个想法,使用两个匹配的服务副本需要2分钟,而只使用一个只需要7秒。 这是一个测试环境。我正在使用泊坞化的
-
如何使用IDE在Storm生产集群中提交拓扑
问题内容: 我在使用IDE向生产集群提交拓扑时遇到了一个问题,而如果我在命令行中使用command 执行同样的事情,它的运行就像天堂一样。我从githublink看到了同样的例子。 为了提交拓扑,我正在使用这些行集 请建议我这是否是运行的正确方法? 问题答案: 很好找到解决方案。当我们运行“ storm jar”时,它将在提交的jar中触发storm.jar的属性标志。因此,如果我们要以编程方式提
-
如何在Redis群集中删除与模式匹配的键
问题内容: 我已经在这个问题中尝试过方法,但是由于我在集群模式下工作,因此它不起作用,redis告诉我: (错误)CROSSSLOT请求中的键未哈希到同一插槽 问题答案: 该问题的答案尝试在一个中删除多个键。但是,与给定模式匹配的键可能不会位于同一插槽中,并且如果这些键不属于同一插槽,则Redis Cluster不支持多键命令。这就是为什么您收到错误消息。 为了解决此问题,您需要一对一地使用以下密
-
mongodb 集群重构和释放磁盘空间实例详解
本文向大家介绍mongodb 集群重构和释放磁盘空间实例详解,包括了mongodb 集群重构和释放磁盘空间实例详解的使用技巧和注意事项,需要的朋友参考一下 MongoDB集群重构,释放磁盘空间 由于mongodb删除了一部分数据后,不会回收相应的磁盘空间,所以这里通过重建数据目录的方式释放磁盘空间。 一 实验环境 配置了一个副本集,该副本集由以下三个节点组成: 10.192.203.201:270
-
Kafka Connect可以成为我的Hadoop集群的一部分吗?
我目前正在使用一个由10个节点(1个名称节点和9个数据节点)组成的Hadoop集群,其中运行Hbase、Hive、Kafka、Zookeeper和Hadoop的其他echo系统。现在我想从RDBMS中获取数据,并将其实时存储在HDFS中。我们可以在同一个集群中使用Confluent Source Connector和HDFS2 Sink Connector吗?还是我需要为Kafka Connect
-
融合云 Kafka - 审核日志群集:接收器连接器
对于托管在 Confluent Cloud 中的 Kafka 集群,会创建一个审核日志集群。似乎可以将接收器连接器挂接到此群集,并从“汇合审核日志事件”主题中排出事件。 但是,当我运行连接器执行相同操作时,我遇到了以下错误。 在我的connect-distributed.properties文件中,我的设置如下: 需要授予哪些额外的权限,以便连接器可以在集群中创建所需的主题?connect-dis
-
我们正在丢失弹性搜索集群中的数据
我们用ElasticSearch做了一个poc,但是在做的时候,我们在集群环境中丢失了数据。我们使用ES2.4.0。 谁能说说我们缺了什么? 我们的设想是: > 使用下面的配置打开弹性服务器1和服务器2,它们位于一个集群中。 服务器上的索引文档-1: curl-xput'20.20.20.5:9200/ert/post/1'-d'{“用户”:“Easlan”,“postdate”:“01-16-2
-
spark独立集群:如何限制工作人员的数量?
> 提交应用程序未设置,然后它将创建 1名16芯工人 使用提交,然后它将创建一个包含15个核心的worker
-
Spark独立集群deployMode=“Cluster”:我的驱动程序在哪里?
我的Spark 2.3.3集群运行良好。我在“http://master-address:8080”上看到了GUI,其中有2个空闲的工作人员。 我有一个Scala应用程序,它创建上下文并启动作业。我不使用spark-submit,我以编程方式开始工作,这是许多答案与我的问题不同的地方。 在“my-app”中,我创建了一个新的SparkConf,代码如下(略有缩写): 司机跑到哪里去了?我如何找到它
-
从远程客户端在Yarn集群上提交Spark作业
我被困在: 在我得到这个之前: 当我签出应用程序跟踪页面时,我在stderr上得到以下信息: 我对这一切都很陌生,也许我的推理有缺陷,任何投入或建议都会有所帮助。
-
Kubernetes:无法通过ClusterIP/NodePort访问VirtualBox集群上的服务
我使用此处的说明在 VirtualBox 上创建了一个 3 节点 kubernetes 集群(1 个主 2 个工作线程)。我正在使用法兰绒作为覆盖网络。 我在安装过程中在主服务器上设置了< code > sysctl-w net . bridge . bridge-nf-call-iptables = 1 和< code > sysctl-w net . bridge . bridge-nf-ca
-
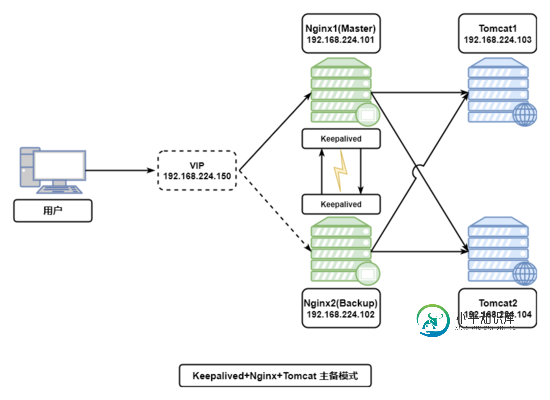 Keepalived+Nginx+Tomcat 实现高可用Web集群的示例代码
Keepalived+Nginx+Tomcat 实现高可用Web集群的示例代码本文向大家介绍Keepalived+Nginx+Tomcat 实现高可用Web集群的示例代码,包括了Keepalived+Nginx+Tomcat 实现高可用Web集群的示例代码的使用技巧和注意事项,需要的朋友参考一下 Keepalived+Nginx+Tomcat 实现高可用Web集群 一、Nginx的安装过程 1.下载Nginx安装包,安装依赖环境包 (1)安装 C++编译环境 (2)安装pc
-
AWS弹性缓存Redis群集“已移动XXXXX ip:6379”错误
我正在尝试连接到AWS Elastic Cache Redis群集,我不断收到此消息,但仍然收到移动12218 ip:6379的错误 以下是代码 https://www.npmjs.com/package/redis-redis:^4.0.1 输出: 但当我等待客户的时候。获取(键)或等待客户端。设置(键,值)我得到移动的错误。 我甚至遵循了这个https://github.com/redis/n
-
EC2实例如何连接到同一VPC中的ElastiCache集群?
我有一个专有网络,在每个AZ为我的EC2提供专用子网。在专有网络中,我的ElastiCache(Redis)实例也有专用子网。设置是这样的 我还有安全组和NACL来控制对子网中资源的访问 当我想从运行在其中一个EC2实例上的程序访问ElastiCache群集时,我必须指定群集endpoint-例如: 我知道,使用读卡器endpoint可以实现读卡器实例之间的负载平衡,但由于所有资源都位于同一VPC
-
Nginx实现集群的负载均衡配置过程解析
本文向大家介绍Nginx实现集群的负载均衡配置过程解析,包括了Nginx实现集群的负载均衡配置过程解析的使用技巧和注意事项,需要的朋友参考一下 Nginx 的负载均衡功能,其实实际上和 nginx 的代理是同一个功能,只是把代理一台机器改为多台机器而已。 Nginx 的负载均衡和 lvs 相比,nginx属于更高级的应用层,不牵扯到 ip 和内核的修改,它只是单纯地把用户的请求转发到后面的机器上。