《集群化》专题
-
何时使用集合与集合?
问题内容: 除了a 和Java 可以两次包含相同的元素外,a 和Java 之间在实践上还有什么区别吗?它们具有相同的方法。 (例如,是否给我更多选择来使用接受s但不接受s的库?) 编辑: 我可以认为至少有5种不同的情况来判断这个问题。其他人还能提出更多建议吗?我想确保我了解这里的微妙之处。 设计接受或参数的方法。更通用,并接受更多输入可能性。(如果我正在设计特定的类或接口,那么对我的消费者会更好,
-
Java中ArrayList的交集和并集
问题内容: 有什么方法可以这样做吗?我一直在寻找,但找不到任何东西。 另一个问题:我需要这些方法,以便可以过滤文件。有些是AND过滤器,有些是OR过滤器(类似于集合论),因此我需要根据所有文件以及保存这些文件的unite / intersects ArrayLists进行过滤。 我是否应该使用其他数据结构来保存文件?还有其他什么可以提供更好的运行时间吗? 问题答案: 这是不使用任何第三方库的简单实
-
Java流-收集、转换和收集
我想获取地图的值,找到min值,并为地图的每个条目构造一个新的CodesWitMinValue实例。我希望使用Java11个流,我可以在多行中使用多个流(一个用于min值,一个用于转换)来实现这一点。是否可以使用java 11流和收集器在单行中实现?谢谢。
-
集合子集的穷举匹配
我有一个关于使用“永远”类型的穷举开关/情况的问题。 比如说,我有一组字符串:{a,B}(字符串可以是任意长的单词,而且集合本身可能非常大),对于每个子集(比如{},{a,B}),我想创建一个函数:show:Set= 预发伪代码: 是否有可能在编译时保证show函数中包含所有可能的子集?所以把C加到集合{A,B,C}需要我扩充show函数吗?并为{C}、{A,C}、{B,C}和{A,B,C}添加案
-
18. 函数的集合与系集
在连续情景中,我们不得不处理函数的集合和函数的系集。由函数集的名字可以看出,它就是一组函数,通常是一个变量——时间的函数。为描述函数集,我们可以给出集合中各种函数的显式表达式,也可以给出只有集合中的函数才拥有的性质。下面是一些示例: 由以下函数组成的集合: 。 的每个具体值确定了集合中的一个特定函数。 一个由时间函数组成的集合,其中包含频率不超过W周期/秒的所有时间函数。 一个由带宽局限于W、幅度
-
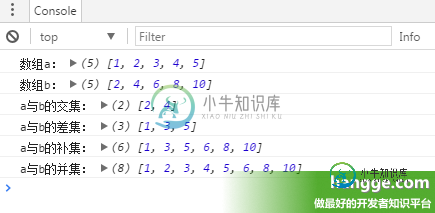 JS计算两个数组的交集、差集、并集、补集(多种实现方式)
JS计算两个数组的交集、差集、并集、补集(多种实现方式)本文向大家介绍JS计算两个数组的交集、差集、并集、补集(多种实现方式),包括了JS计算两个数组的交集、差集、并集、补集(多种实现方式)的使用技巧和注意事项,需要的朋友参考一下 方法一:最普遍的做法 使用 ES5 语法来实现虽然会麻烦些,但兼容性最好,不用考虑浏览器 JavaScript 版本。也不用引入其他第三方库。 1,直接使用 filter、concat 来计算 2,对 Array 进行扩展
-
有没有一种方法可以使特定密钥在集群模式下位于特定Redis实例上?
问题内容: 我想让我的多锁位于不同的Redis实例上。 我发现redission可以指定要在其上执行命令的实例,但是如果命令与键相关,则指定的实例会将命令传输到另一个实例。 你能给我一些建议吗? 问题答案: 您可以,但并非不重要。首先,Redis在密钥中使用花括号来确定其分片部分,因此您可以决定修改密钥并将其发送给任意分片。 现在,您需要两件事: 哪个碎片或插槽范围位于redis实例中的映射。 一
-
如何使用裸机集群上的证书管理器在Kubernetes中自动执行Let's Encrypt证书更新?
我想访问我的库伯内特斯裸机集群与暴露的Ngin x入口控制器TLS终止。为了能够自动更新证书,我想使用库伯内特斯插件证书管理器,它是库贝-lego的继任者。 到目前为止我所做的: > < li> 按照本指南在裸机(1个主机,1个迷你机,均运行Ubuntu 16.04.4 LTS)上设置Kubernetes (v1.9.3)集群,并使用kubeadm和法兰绒作为pod网络。 使用库伯内特斯包管理器h
-
我们如何在一个单独的Openshift/Kubernetes集群中添加第二个运行的卡珊德拉·DC?
我们在 2 个不同的 openshift 集群中部署了 2 个 cassandra 数据中心(每个 openshift 集群一个)。每个Cassandra数据中心都有一个种子盒(pod-0) 我们使用了bitnami helm-chart(https://github . com/bitnami/charts/tree/master/bitnami/Cassandra) 现在我们想连接两个cass
-
集群中有 3 台服务器,其中一个节点宕机,这个时候 zookeeper 还可以使用吗?
本文向大家介绍集群中有 3 台服务器,其中一个节点宕机,这个时候 zookeeper 还可以使用吗?相关面试题,主要包含被问及集群中有 3 台服务器,其中一个节点宕机,这个时候 zookeeper 还可以使用吗?时的应答技巧和注意事项,需要的朋友参考一下 可以继续使用,单数服务器只要没超过一半的服务器宕机就可以继续使用。
-
GKE群集-我可以将流量从全局http负载平衡器定向到nginx入口控制器吗
我正在使用GKE,并在集群上安装了nginx入口控制器。GCP自动创建了一个TCP负载均衡器,将请求从外部临时IP重定向到我的集群节点(nginx)。 我在VM上部署了另一个web应用程序,我想在VM和gke集群之间按子域平衡传入的请求。为了做到这一点,我创建了一个具有2个后端以及主机和路径规则的全局负载平衡器。 我将DNS记录A配置为指向全局负载均衡器。 我可以从我的域访问VM,但我无法访问安装
-
以集群模式在Kubernetes上提交Spark应用程序:配置的服务帐户没有访问权限
我尝试向一个Kubernetes集群(Minikube)提交一个Spark应用程序。在客户端模式下运行我的spark submit时,一切都很顺利。在3个POD中创建3个执行器,并执行代码。下面是我的submit命令: 我该怎么做才能使它起作用?
-
应用程序完成后清理库伯内特斯上的Flink应用程序集群的最佳实践
我们正在Kubernetes上以应用程序模式运行Flink作业,问题是当作业完成/停止时,作业管理器容器将退出,但1。任务管理器2的部署。作业管理器服务3。除非我们运行kubectl delete来清理它,否则configMap仍然存在。 如果我们手动停止作业,这没什么大不了的,但是如果我们的Flink作业是一个批处理作业,稍后会完成,这意味着我们需要一个外部服务来保持监控作业管理器容器并在完成后
-
Kubernetes吊舱如何连接到与主机在同一本地网络(集群外)中运行的数据库?
我有一个库伯内特斯集群(K8s)运行在物理服务器A(内部网络IP192.168.200.10)和一个PostgreSQL数据库运行在另一个物理服务器B(内部网络IP192.168.200.20)中。如何使我的Java应用程序容器(pod)能够连接到服务器B中的PostgreSQL数据库? 操作系统:Ubuntu v16。04 Docker 18.09.7 Kubernetes v1。15.4印花棉
-
js中的集群和使用Kubernetes的自动伸缩web应用程序服务于相同的目的吗?
JS引入了集群模块来扩展应用程序以实现性能优化。我们让Kubernetes做同样的事情。 我很困惑,如果两者都是为了同一个目的?我的假设是集群最多可以产生8个进程(如果有4个cpu核,每个cpu核有2个线程),在Kubernetes中没有这样的限制。