《集群化》专题
-
未绑定到浮动IP的Spark群集主IP地址
null 当我尝试使用这些浮动IPs和标准公共IPs时,我遇到了问题。 在spark-master计算机上,主机名为spark-master,/etc/hosts类似于 对spark-env.sh所做的唯一更改是。如果我运行,我可以查看web UI。 您的主机名spark-master解析为环回地址:127.0.1.1;使用192.x.x.1代替(在接口eth0)16/05/12 15:05:33
-
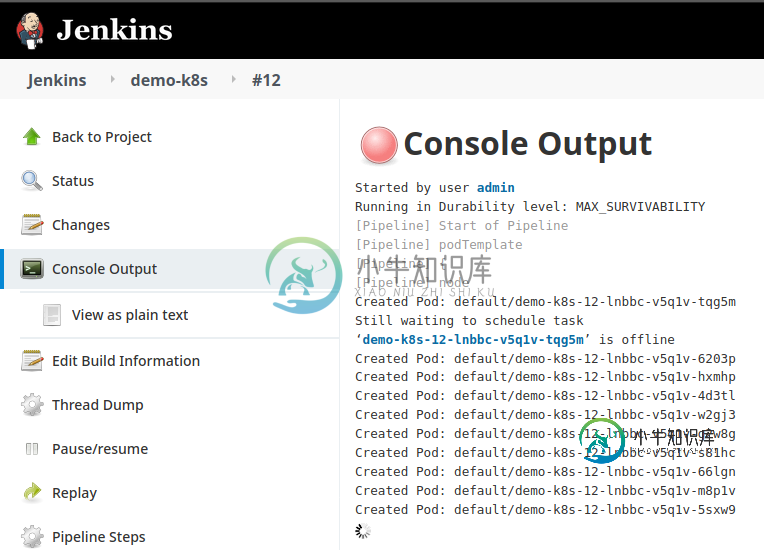 Jenkins管道作业继续在kubernetes集群内创建pod
Jenkins管道作业继续在kubernetes集群内创建pod最近我一直试图在詹金斯内部建立一个管道。目标是创建一个pod并执行kubernetes部署。 但是当我运行管道作业时,它会一个接一个地创建pod,它永远不会完成作业- 设置kubernetes集群-成功 安装jenkins-成功 连接jenkins到kubernetes集群-成功 这是管道脚本- 不-Pods创建成功,kubernetes部署也成功,但jenins管道从未停止。 我的jenkins
-
创建运行在多个docker容器上的HazelCast集群
有没有人知道,如果我们想在运行在多个docker容器上的Hazelcast实例之间形成Hazelcast集群,那么需要在Hazelcast.xml中进行哪些配置。我们应该提供127.0.0.1作为成员的地址还是应该提供docker主机的地址?Local.LocalAddress属性是否需要指向docker主机地址? 编辑:
-
Akka集群单例创业的正确道路是什么
null 我看到“singleton actor总是在具有指定角色的最老成员上运行。”在Akka集群中,单例Doc。但我不明白singleton是怎么开始的。也许所有的单例都必须在第一个种子节点中实现和启动?
-
跨不同openshift集群的应用程序吊舱部署
我在俄亥俄州的一个AWS地区安装了OpenShift3.9。我把詹金斯装在里面了。我有一个管道代码,它将从GitHub中获取Java代码,并将其与jboss绑定,并将其部署在同一个集群中的项目测试中。它工作得很好,我能够访问应用程序,因为pod正在创建,应用程序也与JBoss绑定。现在我想跨不同的集群部署这个应用程序,可以在同一区域内部署,也可以跨不同的区域部署。有没有办法做到这一点?
-
使用Kubeadm创建高可用性Kubernetes集群时出错
我正在使用kubeadm在VM中创建Kubernetes集群(我在VM中使用的映像是CentOS 7 CIS Hardened)。 我正在遵循这个用Kubeadm创建高可用性集群的官方文档 到目前为止我已经完成的步骤: 将这些值更改为1而不是0 回声 1 禁用交换:swapoff-a sed-e'/swapoff/s/^#*/#/' -i /etc/fstab挂载-a 这样做之后,我创建了一个名为
-
Apache Artemis:如何为静态集群创建持久订阅
这里是clustered-stability-subscription的示例,这里是clustered-static-discovery的示例,其中clustered-static-discovery只与一台服务器连接(使用集群配置,集群自动与另一台服务器连接)。根据文档 通常,持久订阅存在于单个节点上,并且在任何时候只能有一个订阅者,但是,使用ActiveMQ Artemis,可以在集群的不同节
-
在多节点群集中跨H2O节点分配资源
我有 2 个 docker 容器运行我的 Web 应用程序和机器学习应用程序,都使用 h2o。最初,我既调用 h2o.init() 又指向同一个 IP:PORT,因此初始化了一个具有一个节点的 h2o 集群。 考虑到我已经训练了一个模型,现在我正在训练第二个模型。在此训练过程中,如果web应用程序调用h2o集群(例如,从第一个模型请求预测),它将终止训练过程(错误消息如下),这是无意的。我尝试为每
-
无法在docker上的spark群集上提交spark作业
正如标题所预期的,我在向docker上运行的spark集群提交spark作业时遇到了一些问题。 我在scala中写了一个非常简单的火花作业,订阅一个kafka服务器,安排一些数据,并将这些数据存储在一个elastichsearch数据库中。 如果我在我的开发环境(Windows/IntelliJ)中从Ide运行spark作业,那么一切都会完美工作。 然后(我一点也不喜欢java),我按照以下说明添
-
基于 Helm Charts 实现的 TiDB 集群备份与恢复
本文详细描述了如何对 Kubernetes 上的 TiDB 集群进行数据备份和数据恢复。本文使用的备份恢复方式是基于 Helm Charts 实现的。 TiDB Operator 1.1 及以上版本推荐使用基于 CustomResourceDefinition (CRD) 实现的备份恢复方式实现: 如果 TiDB 集群版本 < v3.1,可以参考以下文档: 使用 Dumpling 备份 TiDB
-
如何为动态大小的ZooKeeper集群初始化策展人框架?
我刚刚在独立模式下使用Apache Curator和ZooKeeper实现了一个分布式锁。我草签了策展人框架如下: 一切都很好,所以我尝试在集群模式下使用ZooKeeper。我启动了三个实例,并初始化了CuratorFramework,如下所示: 如您所见,我刚刚添加了两个新节点的地址。到目前为止还不错。 但是,当我不知道每个节点的地址和集群的大小时,我如何初始化客户端,因为我想动态扩展它? 我可
-
集群模式下的JBoss EAP7.1集成ActiveMQ Artemis消息重新分发不起作用
在https://access.redhat.com/documentation/en-us/red_hat_jboss_enterprise_application_platform/7.1/html/configuring_messaging/clusters_overview中的第29项之后,重新分发测试不起作用。 测试用例:1个jboss主程序和2个jboss从程序。我在artemis中创
-
spark job在2个节点的集群中运行,但spark submit配置可以轻松地在单个节点中容纳?(集群模式)
spark集群有2个工作节点。节点1:64 GB,8个内核。节点2:64 GB,8个内核。 现在,如果我在集群模式下使用spark-submit提交一个spark作业,其中有2个执行器,每个执行器内存为32 GB,则为4个内核/执行器。现在我的问题是,由于上面的配置可以容纳在单个节点中,那么spark将使用2个工作节点还是只在一个节点中运行它?
-
我如何从运行在同一Kubernetes集群中的容器连接到运行在Kubernetes集群中的主机虚拟机上的Docker?
我正在使用一个安装了docker的docker映像,为了运行任务来清理我的kubernetes集群中每个节点上的docker映像数据。我尝试使用Daemonset,因为它将在除master之外的每个节点上运行,但是在docker容器中运行cron被证明是徒劳的。 因此,我尝试使用K8s Cronjob,它定期运行,具有以下属性: 和 我正在运行一个 shell 脚本,该脚本从上述 CronJob
-
Quartz作业由每台群集计算机同时执行多次,而不是由整个群集的一台计算机执行一次
目标:*使三节点集群每10分钟运行一次Job1,同一集群每5分钟运行一次Job2。每个作业生成一封电子邮件;所以在10:55AM我应该只收到一封来自集群的Job2电子邮件,在11:00AM我应该收到一封来自集群的Job1电子邮件和一封来自集群的Job2电子邮件,在11:05AM我应该只收到一封来自集群的Job2电子邮件,依此类推... 问题:*Job1每10分钟在集群中的每个节点上运行多次,对于J