《集群化》专题
-
十、兽群、鸟群和交通堵塞
本章的代码位于chap10.ipynb中,它是本书仓库中的 Jupyter 笔记本。使用此代码的更多信息,请参见第?节。 10.1 交通堵塞 是什么导致交通堵塞?在某些情况下,有明显的原因,如事故,车速监视或其他干扰交通的事情。 但其他时候,交通堵塞似乎没有明显的原因。 基于智能体的模型有助于解释自发性交通拥堵。 例如,我根据 Resnick,海龟,白蚁和交通堵塞模型实现了一个简单的高速路模拟。
-
在集群中共享Java同步块,还是使用全局锁?
问题内容: 我有一些代码只想允许一个线程访问。我知道如何使用块或方法来完成此操作,但是在集群环境中可以工作吗? 目标环境是WebSphere 6.0,集群中有2个节点。 我感觉这种方法行不通,因为每个节点上的每个应用程序实例都将拥有自己的JVM,对吗? 我在这里试图做的是在启动系统时对数据库记录进行一些更新。它将查找代码版本之前的所有数据库记录,并执行特定的任务来更新它们。我只希望一个节点执行这些
-
启动hadoop集群时报下图错误,分析什么原因:
本文向大家介绍启动hadoop集群时报下图错误,分析什么原因:相关面试题,主要包含被问及启动hadoop集群时报下图错误,分析什么原因:时的应答技巧和注意事项,需要的朋友参考一下 解答: 1、权限问题,可能曾经用root启动过集群。(例如hadoop搭建的集群,是tmp/hadoop-hadoop/.....) 2、可能是文件夹不存在 3、解决: 删掉tmp下的那个文件,或改成当前用户
-
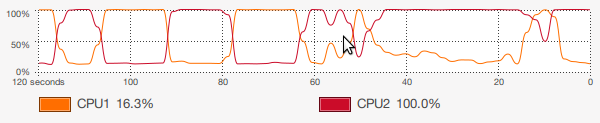 如何在简单的Express应用程序中使用Node.js集群?
如何在简单的Express应用程序中使用Node.js集群?问题内容: —我构建了一个简单的应用程序,该应用程序从Redis数据库中提取数据(50个项目)并将其扔到localhost。我做了一个ApacheBench(c = 100,n = 50000),并且在1.73GHz(我的6岁笔记本电脑)的双核T2080上获得了半不错的150个请求/秒,但是proc的使用非常令人失望显示: 仅使用了一个内核,这是按照Node中的设计进行的,但是我认为,如果我可以使
-
Elastic search给出错误在群集中找不到活动节点
问题内容: 我开始使用Elastic search。我成功在服务器上安装了elasticsearch(与应用程序服务器不同),但是当我尝试从应用程序服务器调用Elatic搜索时出现错误 当我检查Elastic search状态时,它显示 Active 。 如何将Elastic search从我的应用程序服务器调用到elasticsearch服务器。 我的elasticsearch.yml设置 el
-
在Redis集群中使用pipeline批量插入的实现方法
本文向大家介绍在Redis集群中使用pipeline批量插入的实现方法,包括了在Redis集群中使用pipeline批量插入的实现方法的使用技巧和注意事项,需要的朋友参考一下 由于项目中需要使用批量插入功能, 所以在网上查找到了Redis 批量插入可以使用pipeline来高效的插入, 示例代码如下: 但实际上遇到的问题是,项目上所用到的Redis是集群,初始化的时候使用的类是JedisClust
-
是否可以在RKE集群上使用云代码(VSCode内部)?
我正在研究是否可以在私有RKE集群上使用云代码(VSCode内部)?使用VSCode,连接到集群的唯一选择似乎包括GCP(或其他大型云计算提供商)或MiniKube。Kubectl在集群上的所有设置和工作都很好--只是在云中没有支持--运行/调试代码等?我运气不好吗?
-
将一个GKE集群拆成“全新”状态而不删除它?
我第一次真正玩Kubernetes,在GCP上有一个全新的(空的)GKE集群。 我将使用YAML Kustomize文件,并尝试在其中部署一些服务,但我真正寻找的是一个命令(或/命令集),以将GKE集群恢复到一个完全“新”的状态。这是因为它可能需要几十个(或更多!)尝试配置和调整我的YAML文件,直到我得到正确的配置和行为,每次我搞砸了,我都想用一个完全“干净”/新的GKE集群重新开始。出于本问题
-
Spark cassandra连接器不能在独立的Spark集群中工作
我有一个向spark独立单节点集群提交spark作业的maven scala应用程序。提交作业时,Spark应用程序尝试使用spark-cassandra-connector访问Amazon EC2实例上托管的cassandra。连接已建立,但不返回结果。一段时间后连接器断开。如果我在本地模式下运行spark,它工作得很好。我试图创建简单的应用程序,代码如下所示: SparkContext.Sca
-
Kafka Connect 集群中只有一个节点响应 REST API 请求
我在不同的主机上运行Kafka Connect集群,我只看到其中一个节点响应REST API请求(特别是:POST、PUT或DELETE请求)的行为。我可以通过关闭一个节点并向另一个活动节点发出写入命令来可靠地交换响应API请求的节点。 这是我的 docker-compose worker 配置: 我可以使用Debezium Postgres连接器和Kafka Snowflake连接器重现它。所以
-
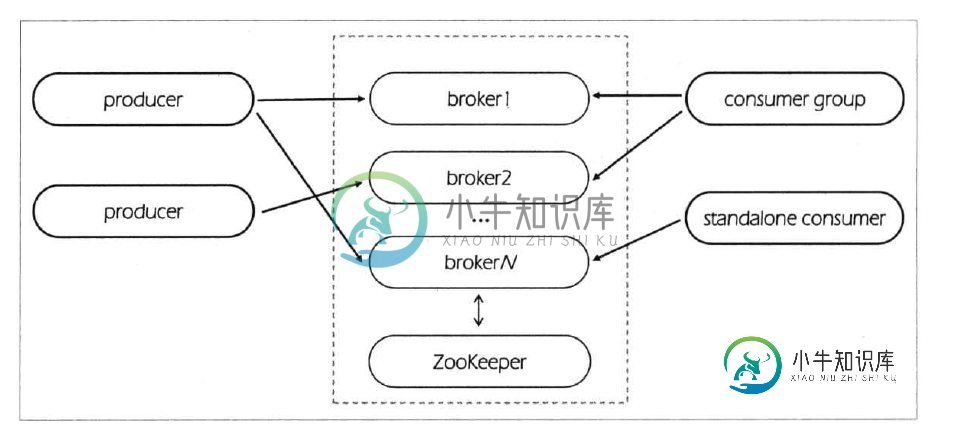 Kafka多节点分布式集群搭建实现过程详解
Kafka多节点分布式集群搭建实现过程详解本文向大家介绍Kafka多节点分布式集群搭建实现过程详解,包括了Kafka多节点分布式集群搭建实现过程详解的使用技巧和注意事项,需要的朋友参考一下 上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法。多节点分布式集群结构如下图所示: 为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建。 一、安装Jdk 具体安装步骤可参考linux安装jdk。 二、安装
-
Docker数据卷容器-我可以在整个群集中共享
问题内容: 我知道如何使用–volumes-from创建数据卷容器并将其安装到其他多个容器,但是我确实对它的用法和局限性有一些疑问: 情况:我正在寻找一个数据量容器来存储用户为我的Web应用程序上传的图像。该数据量容器将由运行Web前端的许多其他容器使用/安装。 问题: 数据量容器可以使用/安装在Docker群中其他主机上的容器中吗? 表现如何?建议以这种方式构造事物吗? 是否有更好的方法来处理跨
-
在Hadoop集群环境中为MySQL安装配置Sqoop的教程
本文向大家介绍在Hadoop集群环境中为MySQL安装配置Sqoop的教程,包括了在Hadoop集群环境中为MySQL安装配置Sqoop的教程的使用技巧和注意事项,需要的朋友参考一下 Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数
-
WildFly 8 EJB查找失败,“没有可用的集群上下文”
这是我需要完成的一个例子。有一个带有虚拟方法的远程EJB接口。该接口由两个有状态EJB实现,第一个EJB需要执行第二个EJB的查找: 助手类JndiManager如下所示: 客户端应用程序执行Bean1的查找并调用其方法。这是JBossEJB客户端。属性文件: 已成功调用Bean1,但其对Bean2的查找失败。错误是: 它在独立模式下工作正常,但在域模式下失败(运行单个主节点)。此外,JBoss
-
 在CentOS中安装Rancher2并配置kubernetes集群的图文教程
在CentOS中安装Rancher2并配置kubernetes集群的图文教程本文向大家介绍在CentOS中安装Rancher2并配置kubernetes集群的图文教程,包括了在CentOS中安装Rancher2并配置kubernetes集群的图文教程的使用技巧和注意事项,需要的朋友参考一下 准备 一台CentOS主机,安装DockerCE,用于安装Rancher2 一台CentOS主机,安装DockerCE,用于安装kubernetes集群管理主机 多台CentOS主机,