
如何在简单的Express应用程序中使用Node.js集群?

—我构建了一个简单的应用程序,该应用程序从Redis数据库中提取数据(50个项目)并将其扔到localhost。我做了一个ApacheBench(c =
100,n =
50000),并且在1.73GHz(我的6岁笔记本电脑)的双核T2080上获得了半不错的150个请求/秒,但是proc的使用非常令人失望显示:
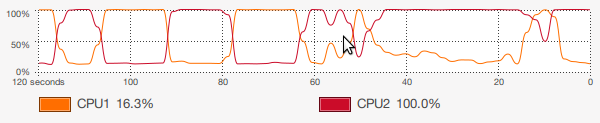
仅使用了一个内核,这是按照Node中的设计进行的,但是我认为,如果我可以使用Node.js集群,我的请求/秒几乎可以提高一倍,达到〜300,甚至可能更高。我摆弄了很多东西,但是我无法弄清楚如何将此处给出的代码与下面列出的我的应用程序一起使用:
var
express = require( 'express' ),
app = express.createServer(),
redis = require( 'redis' ).createClient();
app.configure( function() {
app.set( 'view options', { layout: false } );
app.set( 'view engine', 'jade' );
app.set( 'views', __dirname + '/views' );
app.use( express.bodyParser() );
} );
function log( what ) { console.log( what ); }
app.get( '/', function( req, res ) {
redis.lrange( 'items', 0, 50, function( err, items ) {
if( err ) { log( err ); } else {
res.render( 'index', { items: items } );
}
});
});
app.listen( 8080 );
我还想强调一下,该应用程序是I / O密集型的(不是CPU密集型的,这会使“ 线程多线程”比集群成为更好的选择)。
希望能帮助您解决这一问题。
问题答案:
实际上,您的工作负载并不是真正的I /
O约束:由于基于Jade的动态页面生成的成本,因此它是CPU约束。我无法猜测您的Jade模板的复杂性,但是即使使用简单的模板,生成HTML页面也很昂贵。
对于我的测试,我使用了以下模板:
html(lang="en")
head
title Example
body
h1 Jade - node template engine
#container
ul#users
each user in items
li User:#{user}
我在Redis的item键中添加了100个虚拟字符串。
在我的盒子上,使用100%的node.js CPU可获得475 re / s(这意味着该双核盒子上的CPU消耗为50%)。让我们替换:
res.render( 'index', { items: items } );
通过:
res.send( '<html lang="en"><head><title>Example</title></head><body><h1>Jade - node template engine</h1><div id="container"><ul id="users"><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li><li>User:NOTHING</li></ul></div></body></html>' );
现在,基准测试的结果接近2700 req / s。因此,瓶颈显然归因于HTML页面的格式。
在这种情况下使用群集程序包是一个好主意,而且很简单。该代码可以修改如下:
var cluster = require('cluster')
if ( cluster.isMaster ) {
for ( var i=0; i<2; ++i )
cluster.fork();
} else {
var
express = require( 'express' ),
app = express.createServer(),
redis = require( 'redis' ).createClient();
app.configure( function() {
app.set( 'view options', { layout: false } );
app.set( 'view engine', 'jade' );
app.set( 'views', __dirname + '/views' );
app.use( express.bodyParser() );
});
function log( what ) { console.log( what ); }
app.get( '/', function( req, res ) {
redis.lrange( 'items', 0, 50, function( err, items ) {
if( err ) { log( err ); } else {
res.render( 'index', { items: items } );
}
});
});
app.listen( 8080 );
}
现在基准测试的结果接近750 req / s,CPU消耗为100%(与最初的475 req / s进行比较)。
-
我试图理解我们什么时候需要使用这个应用程序。在我们的node Express中使用 当我在网上搜索时,我在reddit上偶然发现了这个答案,它说明了应用程序之间的区别。获取和应用程序。使用 在此基础上,我总结了以下几点。 充当超级路由或中间件?这意味着它在? 此外,如果有人能添加更多关于app.use.的信息/练习,我将不胜感激
-
使用Apache Open NLP和node的最佳方式是什么。js? 具体来说,我想使用名称实体提取应用编程接口。下面是关于它的说明——留档很糟糕(我认为是新项目): http://opennlp.apache.org/documentation/manual/opennlp.html#tools.namefind 来自文档: 要在生产系统中使用名称查找器,强烈建议将其直接嵌入到应用程序中,而不是
-
问题内容: 我正在使用带有Mongoose ORM的MongoDB在Node.js / Express中构建一个基本博客。 我有一个预“保存”钩子,可以用来为我自动生成一个博客/想法。除在我要查询的部分之前,我想查询一下是否有其他现有的帖子,然后再继续操作,这一切都很好。 但是,似乎无法访问.find或.findOne(),因此我不断收到错误消息。 解决此问题的最佳方法是什么? 问题答案: 不幸的
-
问题内容: 我正在将以下JSON字符串发送到我的服务器。 在服务器上,我有这个。 当我发送字符串时,它表明我得到了200的响应,但是其他两种方法从未运行。这是为什么? 问题答案: 我认为您正在将对象的使用与的使用混为一谈。 该对象用于将HTTP响应发送回调用方客户端,而您想访问的正文。请参阅此答案,它提供了一些指导。 如果您使用的是有效的JSON并通过进行发布,则可以使用中间件解析请求正文并将结果
-
我正在向服务器发送以下JSON字符串。 我在服务器上有这个。 当我发送字符串时,它显示我得到了一个200的响应,但是那些其他两个方法从来没有运行过。这是为什么?
-
问题内容: 我是Node.js编程的新手,我最近使用mongoDB创建了一个示例工作Web应用程序(express,bone和其他免费视图技术)。现在,我正要在暂存环境中部署该应用程序,但我不确定如何打包此应用程序并将其分发。[我可以照顾mongoDb并单独进行设置] 我来自Java世界,在那里我们为可重用的libs创建了jars,并为servlet容器中部署的Web应用程序创建了war / ea