《集群化》专题
-
两种不同Kafka群集设置的Spring Kafka配置
在我们的一个基于spring boot的服务中,我们打算同时连接到两个不同的kafka集群。这些集群都有自己的引导服务器集、主题配置等。它们之间没有任何关联,就像这个问题中的情况一样。 我将有不同类型的消息从不同主题名称的每个集群中读取。可能有或可能没有多个生产者通过此服务连接到两个集群,但我们肯定每个集群至少有一个消费者。 我想知道如何在application.yml中定义属性以满足此设置,以便
-
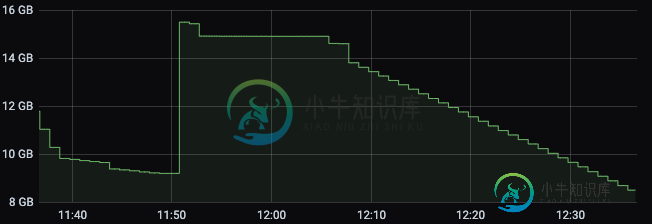 运行Apache Flink作业时K8s群集内存减少
运行Apache Flink作业时K8s群集内存减少我们正在尝试在K8s集群上部署apache Flink作业,但我们注意到一个奇怪的行为,当我们开始我们的作业时,任务管理器内存以分配的数量开始,在我们的例子中是3 GB。 最终,内存开始减少,直到达到约160 MB,此时,它会恢复一点内存,所以不会达到其极限。 这种非常低的内存通常会导致作业因任务管理器心跳异常而终止,即使在尝试查看Flink仪表板上的日志或执行作业流程时也是如此。 为什么它的内存
-
Spring云总线-刷新特定的客户端集群
我在Kafka的spring云总线上配置了一个spring云配置服务器。我正在使用Edgware。随boot 1.5.9一起发布。当我向endpoint/总线/刷新发送POST请求时,destination=clientId:dev:*在主体中通过POSTMAN to config server,所有客户端都会刷新其bean,即使其clientId与destination字段中的值不匹配。 以下是
-
实现多个唯一域名网站的K8s集群
null 优点: 每个网站的POD/容器级隔离 可能是骗局? null null null null
-
在kubernetes集群中通过Ingress公开多个服务
我使用几个独立服务运行Kubernetes单节点dev集群--Nginx proxy(端口80)和elasticsearch(端口9200)。有没有办法用ingress公开这些服务,用一个LoadBalancer IP拥有入口点?(X.X.X.X:80和X.X.X:9200) 我读过关于入口限制,它只能用80和443端口访问。但是,也许,存在一些变通方法? 请Thx提供任何建议 但如果以后您想公开
-
Spark如何处理大于集群内存的数据
如果我只有一个内存为25 GB的执行器,并且如果它一次只能运行一个任务,那么是否可以处理(转换和操作)1 TB的数据?如果可以,那么将如何读取它以及中间数据将存储在哪里? 同样对于相同的场景,如果hadoop文件有300个输入拆分,那么RDD中会有300个分区,那么在这种情况下这些分区会在哪里?它会只保留在hadoop磁盘上并且我的单个任务会运行300次吗?
-
从不同的kubectl客户端连接到kubernetes集群
我已经使用KOPS安装了kubernetes集群。 从kops安装kubectl的节点开始,kubectl全部工作完美(假设节点A)。 我正在尝试从另一个安装了kubectl的服务器(节点B)连接到kubernetes集群。我已经将~/.kube从A节点复制到B节点,但当我尝试执行以下基本命令时: 我的配置文件是: 感谢任何帮助
-
集群环境中的Quartz调度器作业发布
我有一个有两个节点的集群,它连接到同一个数据库,还有一个调度作业,由Quartz调度程序每10分钟启动一次。在quartz.properties中设置。 我感兴趣的是,调度程序是否会为同一节点发出作业,直到每隔10分钟可到达该节点为止,或者它使用某种算法来确定哪个节点将执行该作业。 我在文档(http://www.quartz-scheduler.org/documentation/quartz-
-
Storm集群中执行器多于CPU/核的影响
-
使用SSLContext.getDefault()在spring中使用SSL设置Ignite集群
我试图在我的Spring应用程序中设置一个带有SSL加密的Ignite集群。我的目标是在几个节点上建立一个复制缓存。 我们将应用程序部署到Tomcat8中,并在Tomcat启动时为密钥和信任库设置环境变量。
-
如何从外部进行健康检查elasticsearch集群
我想写一个脚本来检查我们的elasticsearch集群(部署在kubernetes上)的运行状况 我进入运行elasticsearch主容器的pod中,运行以下命令: 如您所见,索引计数和运行状况检查命令都成功。但当我从外部运行这些命令时(我给elasticsearch集群一个公共endpoint) 只有index count命令成功,健康检查命令总是产生403禁止错误。 我已经从elastic
-
K-均值迭代失败处理输出/群集-2
我刚学了几天Hadoop,当我在Hadoop中执行Mahout的示例代码时,我得到了以下错误: 代码段
-
在kubernetes集群上运行API测试的正确IP
我有kubernetes集群和pod,它们是集群IP类型。如果要运行集成测试ip:10.102.222.181或endpoint:10.244.0.157:80,10.249.5.243:80,则哪个ip是正确的ip
-
连接到Redis Sentinel集群时使用redis-py的MasterNotFoundError
当我试图按照以下部署指南连接到主节点时,我面临着MasternotFounderRorr:https://docs.bitnami.com/tutorials/deploy-redis-sentinel-production-cluster/ 连接主Redis Sentinel节点的代码是: 我面对红魔。哨兵。MasternotFounderRorr:没有为“MyMaster”错误找到master
-
Spark:检查集群UI以确保工人已注册
警告TaskSchedulerImpl:初始作业未接受任何资源;检查集群UI以确保工作人员已注册并具有足够的资源 另外,在Spark UI中,我看到了以下内容: 作业持续运行-火花 编辑: 我检查了HistoryServer,这些作业没有显示在那里(即使在不完整的应用程序中)