《集群化》专题
-
由于SSD标签错误,无法创建dataproc群集
在过去的几个星期里,我使用下面的gCloud命令成功地创建了dataproc集群: gcloud dataproc--区域us-east1群集创建测试1--子网默认值--区域us-east1-c--主机类型n1-standard-4--主机启动磁盘大小250--工作机数量10--工作机类型n1-standard-4--工作机启动磁盘大小200--工作机本地SSD数量1--映像版本1.2--作用域h
-
服务器发送事件(SSE)群集连接处理
整个应该由管理(其中大多数请求与业务相关),还是应该由某个完全专用于处理的管理?目前,所有业务请求和SSE事件都由处理。 如何在集群环境中应用主动-主动模式(=master-master),其中请求在实例之间随机路由? 如果您有更多有用的信息(和注意事项),请随时分享!
-
如何检查Databricks群集是否存在Log4J漏洞?
我使用的是带有Scala 2.12的Databricks群集版本7.3 LTS。这个版本确实使用Log4J。 官方文件说它使用Log4J版本。这是否意味着我没有这个漏洞?如果我这样做了,我可以在集群上手动修补它,还是需要将集群升级到下一个LTS版本?
-
redis-py能否可靠地使用AWS ElastiCache Redis集群?
我试图从作为芹菜代理的单一AWS弹性缓存(Redis)服务器转移到Redis集群。问题是-在芹菜或redis-py留档中,我找不到连接到AWS RedisCluster的方法。 芹菜用来与redis服务器通信的redis py可以配置为使用redis Sentinel,但AWS不支持它(至少我在AWS ElastiCache文档中没有找到Sentinel支持)。 那么,有没有一种方法可以使用Red
-
顶点在 Vert.x 节点群集上的公平分布
我一直在试验Vert. x的高可用性功能来测试水平可扩展性和弹性。我有一个基于Hazelcast的几个节点的集群。我正在通过HTTP应用编程接口在任何节点上创建顶点。Verticle在创建时设置了标志。 如果我有< code>n个节点< code>Nn加载了HA-verticles,并且如果我添加了一个额外的节点,则没有从新节点上的< code>Nn节点迁移的vertices,因此负载将会平衡。有
-
带有rabbitmq集群和spring amqp的负载均衡器
我想在负载均衡器后面设置一个rabbitmq集群,并使用spring AMQP连接到它。问题: > spring客户端是否需要知道RMQ集群中每个节点的地址,或者只知道负载均衡器的地址就足够了。 如果Spring客户端只知道负载均衡器,那么它将如何为集群中的每个节点维护连接/连接工厂。 是否有任何代码示例,说明如何使spring客户端与负载均衡器一起工作。
-
集群的一个Kafka代理关闭时发生ConnectException
我有两个Kafka代理:server1:9092和server2:9092我正在使用Java客户端向这个集群发送消息,代码如下: 当其中一个代理关闭时,Test在某些情况下会抛出此异常(在此异常示例中'server1'已关闭): 2015-11-02 17:59:29138警告[org.apache.kafka.common.network.Selector]服务器1/40.35.250.227
-
Spark 1.2.1独立集群模式spark-submit不起作用
/usr/local/spark-1.2.1-bin-hadoop2.4/bin/--类com.fst.firststep.aggregator.firststepmessageProcessor--主spark://ec2-xx-xx-xx-xx.compute-1.amazonaws.com:7077--部署模式集群--监督文件:///home/xyz/sparkstreaming-0.0.1
-
Hadoop集群。Map reduce作业卡在Map 100%和reduce 0%
我是Hadoop新手。我试图根据Apache hadoop站点上给出的示例创建一个hadoop集群。 然而,当我运行map reduce示例时,应用程序卡在map 100%和reduce 0%。 请帮忙 我已经设置了使用Vagrant和Virtual Box的环境。创建了两个实例。 yarn-site.xml
-
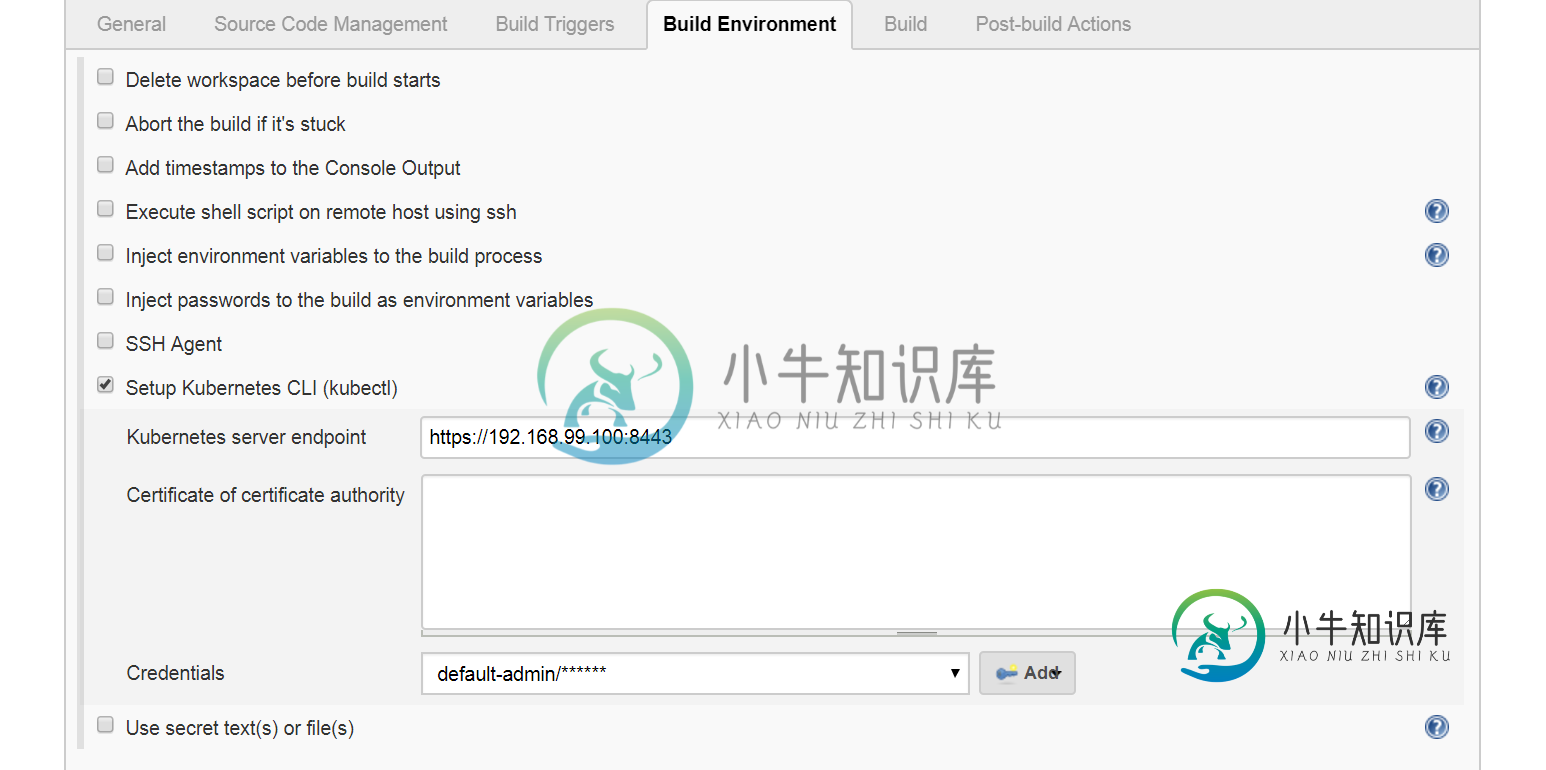 使用minikube-kubernetes集群在Jenkins中运行kubectl命令
使用minikube-kubernetes集群在Jenkins中运行kubectl命令我的http://localhost:8080/上有一个jenkins,我创建了一个项目,该项目将运行kubectl命令,使用(minikube)连接到kubernetes集群 我正在尝试运行windows命令C:\Program Files(x86)\Jenkins\workspace\test2 这是Kubernetes主机正在运行的minikube群集信息https://192.168.99
-
如何使用kubectl识别kubernetes群集提供程序
我在k8s守护程序上工作,其部署需要根据k8s群集提供程序类型(gke、eks、aks、minikube、k3s、kind、在vm上使用kubeadm安装的自我管理k8s等)更改某些值。 如果已经配置了,那么确定k8s集群提供程序类型的正确方法是什么? 一个选项是使用: 然而,这似乎是hacky,我确信它不会在所有情况下工作。例如,对于EKS,我不知道使用什么正则表达式。
-
Kafka镜像集群中如何维护客户偏移?
假设我有两个Kafka集群,我使用mirror maker将主题从一个集群镜像到另一个集群。我知道consumer有一个嵌入式生产者,可以向Kafka集群中的主题提交偏移量。我想知道如果Kafka星系团的初选失败会发生什么?我们是否也同步主题?因为第二集群可能有不同数量的代理和其他设置,我认为。 请告诉我Kafka镜像集群是如何处理消费者补偿的? auto.offset.reset设置在这里起作用
-
无法查找主机集群的TXT记录0-xxxxx.mongoDB.net
上下文初始化过程中遇到异常-取消刷新尝试:org.springframework.beans.factory.unsatisfieddependencyexception:创建名为“mongo bootapplication”的bean时出错:通过字段“repository”表示的不满足的依赖关系;嵌套异常为org.springframework.beans.factory.BeanCreatio
-
如何估算Hortonworks Hadoop集群上spark executor的数量?
null 当我运行一个火花程序时,执行器只在4个节点上运行,而不是在整个数据节点上运行。 如何估计这样的Hadoop集群上spark执行者的数量?
-
群集范围的未定义行为[ThreadName=Data-Streamer-Stripe
我实际上是在加载CA。5'000'0000条记录。过了一段时间(500'000条记录),我收到了以下消息 严重:检测到阻塞的系统关键线程。这可能导致集群范围内的未定义行为[ThreadName=Data-Streamer-Stripe-2,BlockedFor=17s]rto_1 Mar.082020 5:02:08 PM java.util.logging.logManager$RootLogg