
运行Apache Flink作业时K8s群集内存减少

我们正在尝试在K8s集群上部署apache Flink作业,但我们注意到一个奇怪的行为,当我们开始我们的作业时,任务管理器内存以分配的数量开始,在我们的例子中是3 GB。
taskmanager.memory.process.size: 3g
最终,内存开始减少,直到达到约160 MB,此时,它会恢复一点内存,所以不会达到其极限。
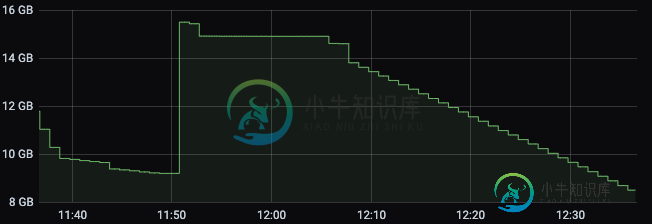
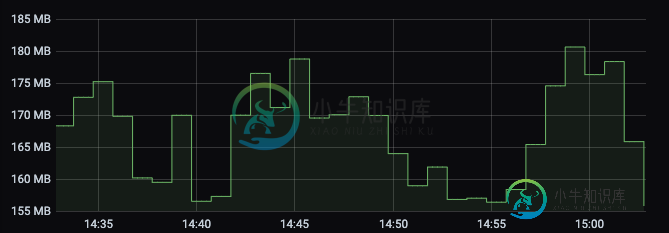
这种非常低的内存通常会导致作业因任务管理器心跳异常而终止,即使在尝试查看Flink仪表板上的日志或执行作业流程时也是如此。
为什么它的内存如此之少?我们希望有这种行为,但在GB的范围内,因为我们将这些3Gb分配给任务管理器,即使我们更改任务管理器内存大小,我们也有相同的行为。
我们的Flink conf如下所示:
flink-conf.yaml: |+
taskmanager.numberOfTaskSlots: 1
blob.server.port: 6124
taskmanager.rpc.port: 6122
taskmanager.memory.process.size: 3g
metrics.reporters: prom
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
metrics.reporter.prom.port: 9999
metrics.system-resource: true
metrics.system-resource-probing-interval: 5000
jobmanager.rpc.address: flink-jobmanager
jobmanager.rpc.port: 6123
K8s上是否有推荐的内存配置或我们在flink-conf.yml中缺少的东西?
谢谢
共有2个答案

您在部署模板中的要求/限制是什么?如果没有指定的请求大小,您可能会看到集群资源被占用。

您的配置看起来很好。这很可能是您的代码有问题和某种内存泄漏。这是一个很好的答案,描述了可能存在的问题。
您可以尝试使用taskmanager在JVM堆上设置限制。记忆力任务堆你给JVM一些额外的空间来执行GC等等,但是最后,如果你分配的是没有被引用的东西,你就会遇到这种情况。
据推测,您正在使用内存来存储您的状态,在这种情况下,您还可以尝试将RockDB作为状态后端,以防您存储大型对象。
-
我注意到,每次我运行一个新作业时,它所花费的时间比我再次启动它时长20%左右? 如果一个作业运行多次,flink是否缓存一些结果并重用它们?如果是,我如何控制这一点? 我想测量我的任务运行了多长时间,但每次我重新运行它们时,速度都比以前快。
-
我已经在 GCP Kubernetes 上设置了一个 cron 作业。它每天上午10:00运行一次。作业按预期运行,但是,我真的不明白 GCP K8S 控制台上的图表是什么。 如图所示,当cron作业没有运行时,此时大约有1.5个CPU和8G RAM。我希望当前的使用应该为零,因为它没有运行。 谁能看出出了什么问题?还是我看错了图表? 请注意,我在历史中保留了7个作业。每个作业运行了大约15秒并成
-
注: 内容翻译自 Run etcd clusters inside containers 下列指南展示如何使用 static bootstrap process 来用rkt和docker运行 etcd 。 rkt 运行单节点 etcd 下列 rkt 运行命令将在端口 2379 上暴露 etcd 客户端API,而在端口 2380上暴露伙伴API。 当配置 etcd 时使用 host IP地址。 ex
-
当Quartz群集时,如何查明某个特定作业当前是否在Quartz中运行? “获取正在运行的作业”问题的标准答案是使用,但是根据javadoc的说法,这在集群环境中不起作用。 那有什么诀窍?
-
所以我现在花了几个小时试图解决这个问题,并希望得到任何帮助。
-
我已经在我的Windows7机器上设置了一个本地spark集群(一个主节点和辅助节点)。我已经创建了一个简单的scala脚本,我用sbt构建了这个脚本,并尝试用Spark-Submit运行这个脚本。请参阅以下资源 Scala代码: 现在,我用sbt构建并打包scala代码,并将其打包到一个JAR中。我的build.sbt文件如下所示 它创建一个jar,我使用spark submit命令提交它,如下