《均衡》专题
-
这是在SQL中强制转换、舍入和平均对象的正确方法吗?
问题 如何使用和在PostgreSQL中提供小数点? 将字符串转换为十进制数需要什么函数? 使用的功能 第1功能 第一个错误 第二功能 第二个错误 第三功能 什么函数用于将字符串转换为数字? 编辑 看起来我有一个精神失误。粘位澄清说int没有小数!我从原来的帖子中删除了int位。
-
需要Java数组帮助使用扫描仪类输出平均和排序方法
过了几个小时,在做一个输出平均值的方法上还没有进展,还需要做一个排序类,总体来说,作业需要。 开发方法以: < Li >“main”方法打印数组 < li >对数组排序 < li >确定最大值 < li >确定最低值 < li >计算平均值(双精度)
-
渐近时间复杂度与最佳、平均和最坏情况输入的组合
我被许多声称渐近符号与最好情况、一般情况和最坏情况的时间复杂度无关的说法搞糊涂了。如果是这种情况,那么下面的组合可能都是有效的: 最佳情况 - 最佳情况输入的上限 为了尽可能好的输入,该算法执行的基本操作的数量永远不会超过n的某个常数倍。 对于平均输入,该算法执行的基本操作的数量永远不会超过n的某个常数倍。 对于最坏的可能输入,该算法执行的基本操作的数量永远不会超过n的某个常数倍。 为了获得最佳输
-
如何计算由Spark中的(键,[值])对组成的RDD中每对的平均值?
我对斯卡拉和Spark都很陌生,所以如果我做错了,请原谅我。在接收csv文件,过滤和映射之后;我有一个RDD,它是一堆(字符串,双)对。 当我在RDD上使用.groupByKey()时, 得到一个有一堆(String,[Double])对的RDD。(我不知道CompactBuffer是什么意思,可能会导致我的问题?) 一旦他们被分组,我将尝试取平均值和标准偏差。我只想使用.mean()和.samp
-
如何计算具有相同列名的数据帧中这些列的平均值
我有一个由66个变量的10299个观测值组成的数据框。其中一些变量共享一个通用的列名,我想计算每个观测值的这些变量的平均值。 具有以下矩阵,列名: 我想得到: 我尝试了循环,命令,但没有得到所需的结果。 抱歉,如果这个问题看起来太基本了,我已经在谷歌上查过可能的解决方案,但没有找到任何解决方案。
-
如何覆盖功能区.server列表刷新Spring云功能区中的平均值?
我编写了一个简单的Spring Cloud Ribbon应用程序,来调用在Eureka注册的REST服务。 但是如何覆盖值呢?默认值是30秒,我想缩短时间间隔。 提前致谢。
-
从R中具有精确均值和sd的截断正态分布生成数据
-
如何在单个jenkins作业中使用maven生成Jacoco和Sco平均值报告
我有一个java和scala的多模块项目。这两个Jacoco插件和Sco平均值都安装在Jenkins中,我想在Jenkins中的单个构建作业中生成Jacoco和Sco平均值报告(两者),但只有一个报告正在生成,无论是Jacoco还是Sco平均值。 下面的mvn命令尝试到目前为止- 和 我pom文件的片段- 当我使用-mvn-B-s$mvn_设置时,jacoco:prepare agent inst
-
Jmeter上GUI模式和非GUI模式的平均响应时间有巨大差异
我发现Jmeter上GUI模式和非GUI模式的平均响应时间有很大差异。 GUI模式:2777毫秒,非GUI模式:5412毫秒。1个线程,1个RampupTime,1个循环计数,100个样本请求。 两个测试是如何在同一台机器上运行的。应该考虑哪些结果。
-
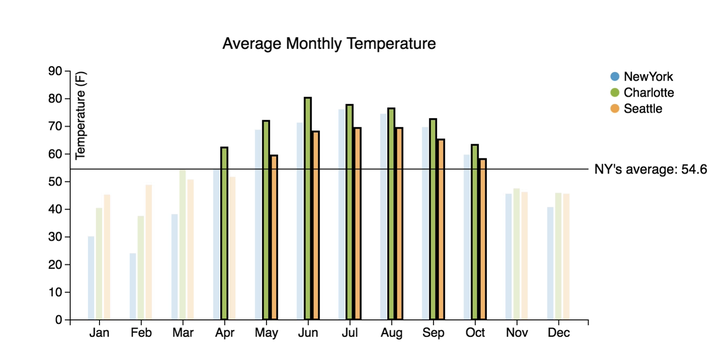 前端 - 能否给图表添加基于数据值计算的平均线横线?
前端 - 能否给图表添加基于数据值计算的平均线横线?在使用 VChart 图表库时,能否做到类似于下图的效果,在图表中添加标注线表示数据的平均值?
-
Java,通过多线程环境中的哈希将传入的工作均匀地划分
问题内容: 我已经实现了一个Java代码,以根据其hashCode模块的n个线程来执行传入任务。理想情况下,工作应该均匀地分布在这些线程之间。具体来说,每个任务都有一个字符串。 这是此Java代码段: 重要说明: 在大多数情况下,dispatchId为: 但是,我担心nThreads的模除法不是一个好选择,因为nThreads应该是质数,以便更均匀地分配dispatId键。 关于如何更好地传播作品
-
在平均堆栈应用程序中显示图像(服务图像)的有效方式?
我正在开发一个平均堆栈应用程序,我想显示一些响应的图像。具体要求:有搜索框,当用户输入图像名称时,服务器响应该图像,浏览器显示该图像。我有最大的70个图像大小30KB最大。我应该将这些存储在mongoDB中,并且对于每个请求节点,服务器应该点击mongoDB并在响应中提供该映像,还是使用Angular.js提供该映像?请推荐这样做的有效方法。
-
如何在Python中将读取的大型csv文件拆分为均匀大小的块?
问题内容: 基本上,我要进行下一步。 请参阅此相关问题。我想每100行发送一次处理行,以实现批量分片。 有关实现相关答案的问题是csv对象无法下标并且不能使用len。 我该如何解决? 问题答案: 只需将您的下标包装到即可。显然,这会在大型文件上中断(请参见下面的 更新 中的替代方法): 进一步阅读:如何在Python中将列表分成均匀大小的块? 更新1 (列表版本):另一种可能的方法是处理每个卡盘,
-
如何不断调整随机数生成器的权重,使结果分布更均匀?
我试图想出一个解决方案,可以生成具有更均匀分布结果的随机整数。 其基本思想是: 例如,我想生成一个0-9之间的随机整数。随着每个新随机数的生成,我还保留了一个列表,该列表计算每个数字生成了多少次。例如,如果第一个结果是5,那么5的计数为1,这将使数字5下次生成的可能性降低,因为其他数字的计数只有0。 起初,我想做这件事就像一个常规加权随机数生成器一样,它将所有权重相加,并在总和范围内创建一个随机数
-
如何自下而上遍历树以计算PostgreSQL中节点值的(加权)平均值?
问题内容: 例如,在PostgreSQL中对整个树求和的典型示例是使用WITH RECURSIVE(公用表表达式)。但是,这些示例通常从上到下,将树展平,并对整个结果集执行汇总功能。对于我要解决的问题,我没有找到合适的示例(在StackOverflow,Google等上): 考虑一个不平衡的树,其中每个节点可以具有一个关联的值。大多数值都附加到叶节点,但其他值也可能具有值。如果节点(是否有叶子)具