《均衡》专题
-
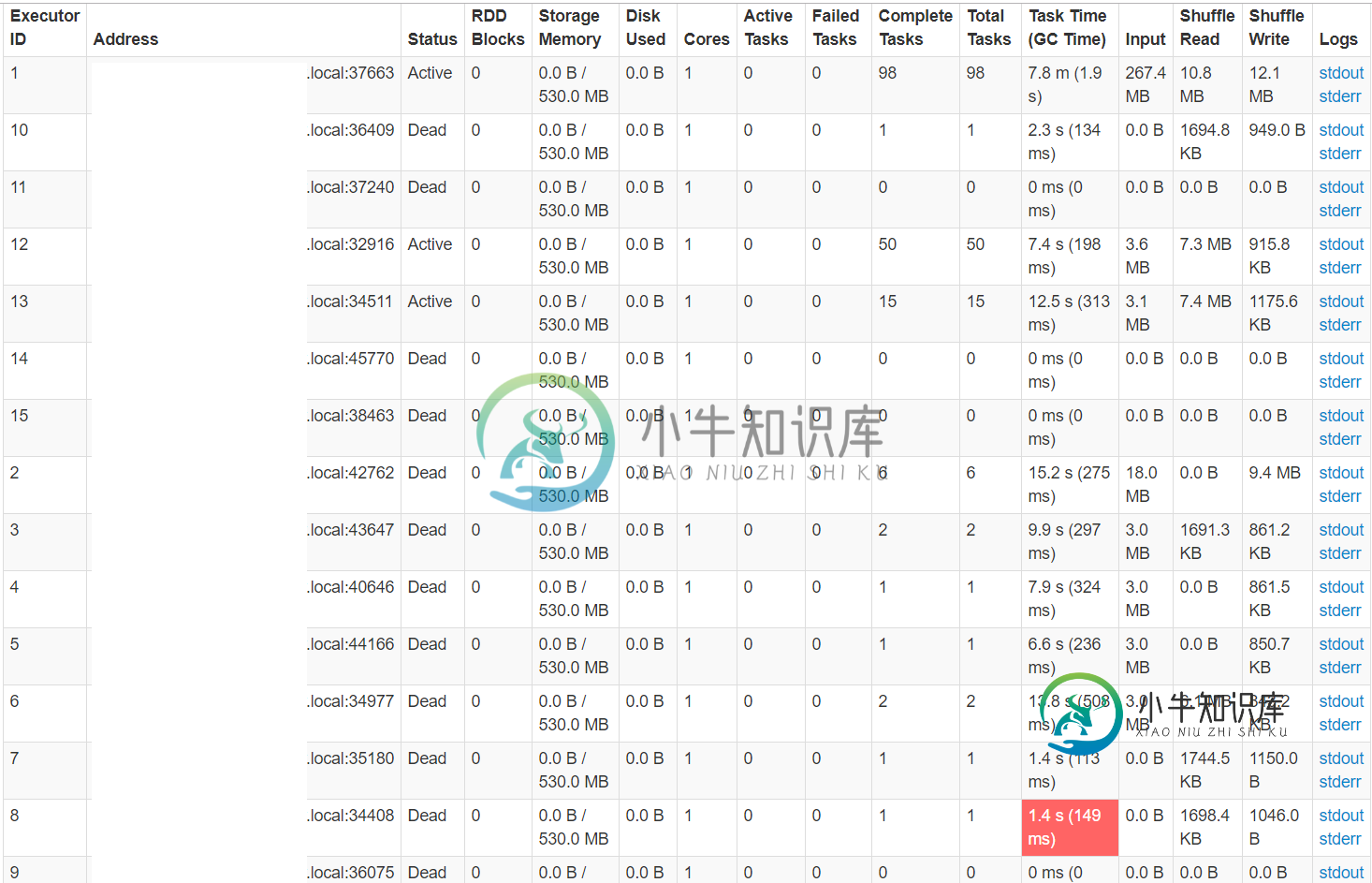 Spark性能:本地比集群快(执行器负载非常不均匀)
Spark性能:本地比集群快(执行器负载非常不均匀)让我先说我对spark相对来说是新手,所以如果我说了一些没有意义的话,请纠正我。 总结一下这个问题,不管我做什么,在某些阶段,一个执行器做所有的计算,这使得集群执行比本地的单处理器执行慢。 完整故事:我编写了一个Spark1.6应用程序,它由一系列映射、过滤器、连接和一个简短的graphx部分组成。该应用程序只使用一个数据源-csv文件。出于开发的目的,我创建了一个由100,000行7MB组成的模
-
计算每行的平均值并存储在最后一个元素中
我需要计算每行的平均值,并存储在最后一个元素中。我设法做到了,但后面的行是前一行的累计平均值。例如: 输入: 1 2 3 0 4 5 6 0 输出: 1.00 2.00 3.00 2.00 4.00 5.00 6.00 7.00(应为5.00) 这是我的代码 提前谢谢。:)
-
如何查找哪些列没有任何数据(所有值均为NULL)?
问题内容: 我在数据库中有几个表。我想查找哪些列(在哪些表中)没有任何值(列中都为NULL)。在下面的示例中,结果应该是 我不知道如何创建这种查询。非常感谢您的帮助! 问题答案: 对于单列,返回不为null的行数: 您可以为所有列生成查询。根据Martin的建议,您可以使用排除不能为空的列。例如: 如果表的数量很大,则可以类似的方式为所有表生成查询。所有表的列表在中。
-
pandas数据框:按两列分组,然后对另一列取平均值
问题内容: 假设我有一个具有以下值的数据框: 我想首先根据前两列(col1和col2)对数据框进行分组,然后对第三列的值(值)进行平均。因此,所需的输出将如下所示: 我正在使用以下代码: 出现以下错误: 任何帮助将非常感激。 问题答案: 您需要将列的列表传递给groupby,您传递的内容被解释为param,这就是它引发错误的原因:
-
数据帧列平均值上的布尔运算-这必须很简单
我至少有一个数据帧: 我想保留数据框中低于df['avg'列中平均值的所有值。当我执行以下操作时,返回所有的NAN 如果我设置一个for循环,我可以得到我想要的布尔值。 我要找的东西是这样的: 我该怎么做呢?一定有蟒蛇的方法来做到这一点。
-
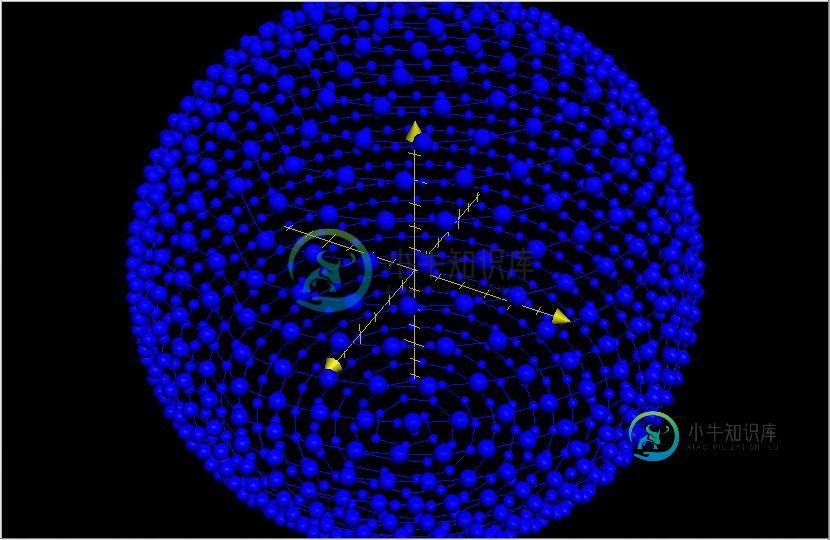 Python实现将n个点均匀地分布在球面上的方法
Python实现将n个点均匀地分布在球面上的方法本文向大家介绍Python实现将n个点均匀地分布在球面上的方法,包括了Python实现将n个点均匀地分布在球面上的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现将n个点均匀地分布在球面上的方法。分享给大家供大家参考。具体分析如下: 最近工作上遇到一个需求,将10000左右个点均匀地分布在一个球面上。所谓的均匀,即相邻的两个点之间的距离尽量一致。 我的算法是用基于正多面
-
sklearn:在测试数据集上计算k均值的准确性得分
问题内容: 我正在对30个带有2个聚类的样本进行k均值聚类(我已经知道有两个类)。我将数据分为训练集和测试集,并尝试计算测试集的准确性得分。但是有两个问题:首先,我不知道我是否真的可以针对k均值聚类做到这一点(测试集上的准确性得分)。第二:如果我被允许这样做,那么我的实现是写的还是错误的。这是我尝试过的: 但是,当我在 最后三行中 打印 测试集的k-means标签( k_means.predict
-
如何从栅格中提取和计算某些区域的平均值?
我想在第一个光栅中选择一个小区域,计算该区域的空间平均值,并对其他11个光栅执行相同的操作。最终将得到12个值。 我试过这个: 这样做对吗? 那么我如何计算所选区域的空间平均值?并对所有其他光栅执行相同的操作。提前谢谢。
-
不支持的major.minor版本51.0,但所有内容均设置为JDK 1.6
问题内容: 我有一个Maven Eclipse应用程序,正在尝试使用以下命令在命令提示符下运行: 不幸的是,它引发了一个错误: 我做了一些挖掘,发现它与在较新版本的JDK上运行的应用程序(而不是在其上运行的JRE)有关。显然51意味着它是为1.7构建的,但是我的计算机上没有JDK 7。 因此,我确保一切都设置为1.6版: 根目录中的system.properties文件包含 添加了Maven属性
-
在2个日期和平均每小时输出之间选择数据
问题内容: 我有一系列的温度数据,每分钟收集一次,并放入MySQL数据库中。我想编写一个查询以选择过去24小时内的所有温度,然后将其平均并划分为小时数。是否可以通过SQL命令执行? 我认为这是在两个日期/时间之间选择所有记录的情况,但这就是我遇到的问题。 数据示例: 所需的输出/结果 我希望您能有所帮助,因为我对SQL命令一无所知。 问题答案: 试试这个查询
-
SQL触发功能可在插入时更新每日移动平均值
问题内容: 我正在尝试创建一个SQL触发函数,当将数据插入表中时,该函数应该更新列。该更新基于被插入的值中存在的值。 我有下表存储股票的每日OHLC数据。 INSERT命令: 当执行此命令时,我想基于当前值“ INSERTed”和表中已有的值来更新“ sma8”列。 到目前为止,我正在使用以下SQL查询来计算每一行的值,然后使用结果使用python更新“ sma8”列。 上面的查询计算最后8条记录
-
如何让Spring Boot指标将平均值和绝对值导出到csv
我需要将计数器和仪表导出到csv,以便以后处理它们。通过使用gradle,我获得了codahale metrics 3.1.2的JAR: 对于csv导出,我使用以下代码行创建了一个reporter: 我可以看到创建的文件包含时间戳和值(在本例中,值是为仪表设置的): 唯一的问题是,文件重复最后设置的值,直到我使用gaugeService覆盖它。submit()。在这种情况下,我将仪表值设置为42.
-
 利用K均值聚类精确检测图像中的颜色区域
利用K均值聚类精确检测图像中的颜色区域我在基于颜色的图像分割中使用了K-均值聚类。我有一个2D图像,它有3种颜色,黑色,白色,和绿色。这是图像, 我想让K-means产生3个簇,一个代表绿色区域,第二个代表白色区域,最后一个代表黑色区域。 这是我使用的代码, 但我没有按要求得到结果。我得到一个带有绿色区域的簇,一个带有绿色区域边界的簇,还有一个带有灰色、黑色和白色的簇。下面是产生的集群。 这样做的目的是,在得到正确的聚类结果后,我想利
-
在一个均匀的分支中有一个非束缚的取样器
假设我有一个像素着色器,有时需要从一个采样器读取,有时需要从两个不同的采样器读取,这取决于一个统一的变量 第二个采样器需要绑定到有效的纹理,即使如果为,纹理也不会被读取。
-
在K.ctc\U批量成本()中,输入长度的平均值是多少
我已经下载了一个使用Keras的ocr代码,它应用了CRNN网络,并使用CTC损失作为损失函数。然而,我对CTC损失非常陌生,只是对的用法有困难,尤其是input_length的含义。在keras的文件中, tf.keras.backend.ctc_batch_cost论证(y_truey_predinput_lengthlabel_length) > 然而,我的问题是输入长度的含义是什么?这是L