《均衡》专题
-
堆插入的O(1)平均大小写复杂度的参数
Wikipedia页面上关于二进制堆的声明是,在最坏的情况下插入是O(log n),但平均为O(1): 链接的页面试图如下说明: 但是,平均来说,新插入的元素在树中并不会移动很远。特别是,假设密钥分布均匀,它有一半的机会大于其父项;它有二分之一的机会比它的祖父母更大,因为它比它的父母更大;它有一半的机会比它的曾祖父母大,因为它比它的父母大,依此类推[...]因此在一般情况下插入需要恒定的时间 不过
-
插入和冒泡排序的平均事例复杂度分析
这个网站已经有一些关于这个话题的问题,但是在阅读了一些答案后,我感到困惑。 https://cs.stackexchange.com/questions/20/evaluating-the-average-time-complexity-of-a-given-bubblesort-algorithm 在上面的链接中,“Joe”的回答表示,平均而言,泡沫排序的掉期数量与平均反转数量相同,即(n)(n
-
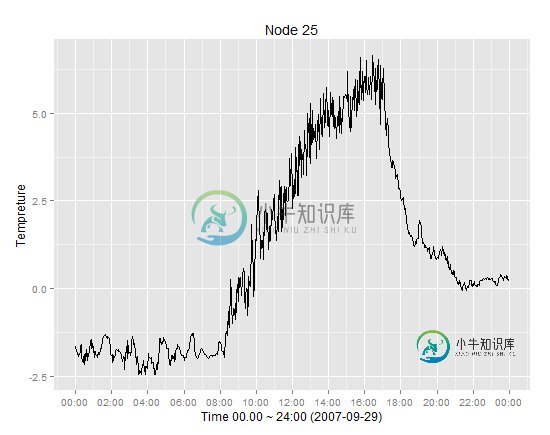 在R中的时间序列图中添加移动平均图
在R中的时间序列图中添加移动平均图我在ggplot2包中有一个时间序列的图,我已经执行了移动平均,我想把移动平均的结果添加到时间序列的图中。 数据集样本(p31): ambtemp DT -1.14 2007-09-29 00:01:57 -1.12 2007-09-29 00:03:57 -1.33 2007-09-29 00:05:57 -1.44 2007-09-29 00:07:57 -1.54 2007-09-29 00
-
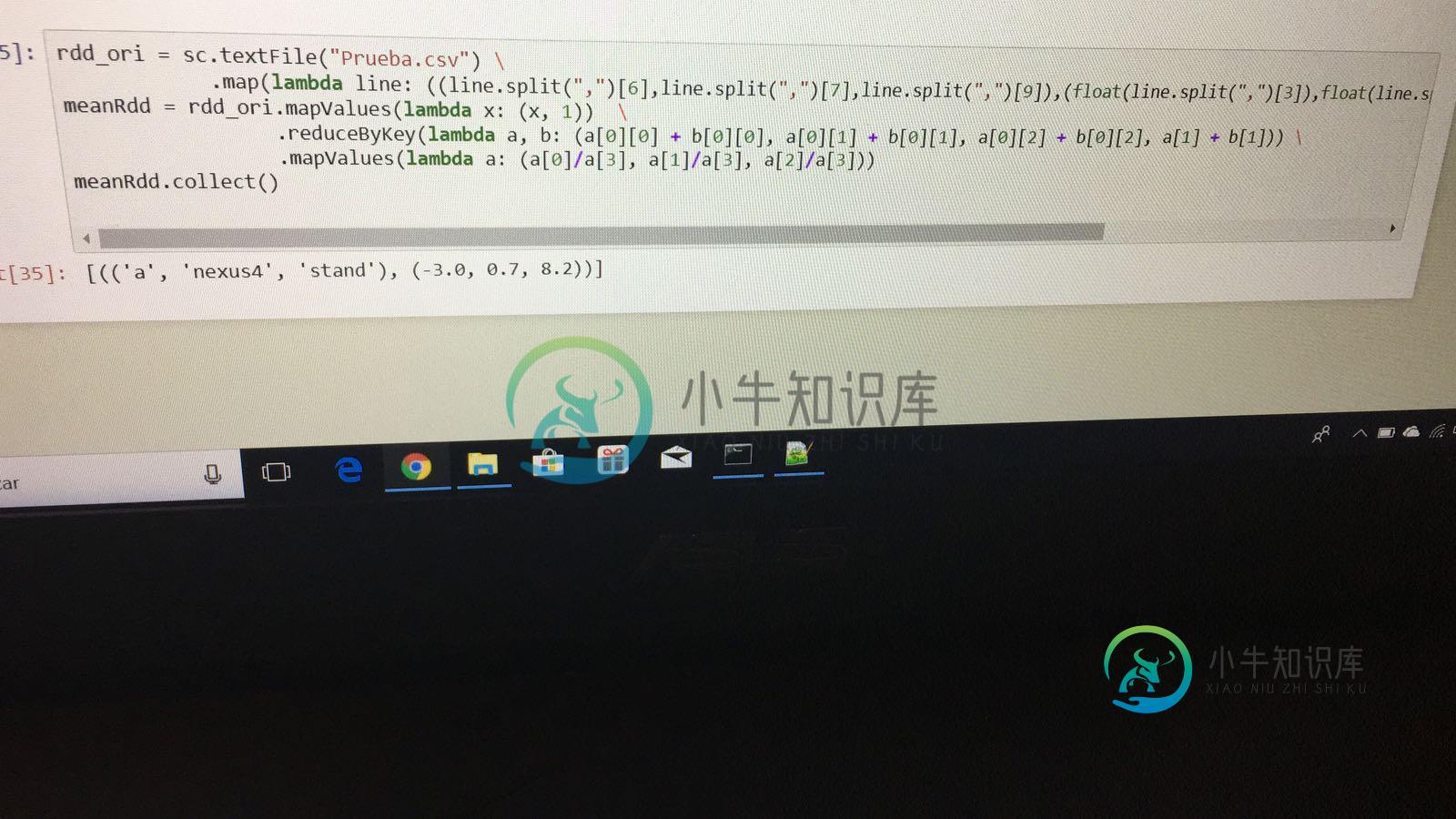 Pyspark-TypeError:使用reduceByKey计算均值时,“float”对象不可订阅
Pyspark-TypeError:使用reduceByKey计算均值时,“float”对象不可订阅我的“asdasd.csv”文件具有以下结构。 好的,我得到下面的{key,value}元组来操作它。 我的计算平均值的代码如下,我必须计算每一列的平均值,X,Y,Z为每一个键。 /opt/spark/current/python/pyspark/rdd.py in take(self,num)1341 1342 p=range(partsScanned,min(partsScanned+numP
-
4.7 实例研究:用数组计算平均值、中数和模
下面要举一个更大的例子。计算机常用于编译和分析调查结果,图4.17的程序用数组 response 初始化调查的99个答复(用常量变量 response 表示),每个答复是1到9的数值。程序计算99个值的平均值、中数和模。 1 // Fig. 4.17: fig04_lT.cpp 2 // This program introduces the topic of survey data analys
-
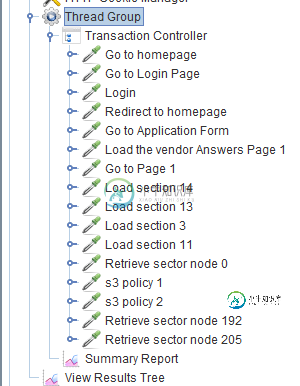 事务控制器如何在摘要报告中具有单独的平均时间,而总体报告如何具有单独的平均时间
事务控制器如何在摘要报告中具有单独的平均时间,而总体报告如何具有单独的平均时间我在一个事务控制器下运行了一个Jmeter脚本,其中包含所有示例,如下图所示 然后,当我得到这个测试的总结报告,并在reportunderaverage列中发现事务控制器显示了所有样本的平均时间的总和。问题1:为什么事务控制器也显示为示例?问题2:(勾选下面的摘要报告图像)总平均值不应该是7608/17(其中事务控制器平均值为7608,样本数为17)如果您看到下面的摘要报告,您可以看到显示的平均时
-
写一个三栏布局,中间固定,两边自适应(平均)
本文向大家介绍写一个三栏布局,中间固定,两边自适应(平均)相关面试题,主要包含被问及写一个三栏布局,中间固定,两边自适应(平均)时的应答技巧和注意事项,需要的朋友参考一下
-
熊猫数据框中的分组比加权平均值和总和
问题内容: 我有一个数据框 我需要的是Adjusted_lots,price和ajusted_lots的加权平均价格之和,并按所有其他列进行分组,即。按(合同,月,年和购买)分组 R的类似解决方案是使用dplyr通过以下代码实现的,但是在熊猫中却无法做到这一点。 groupby或任何其他解决方案是否可能相同? 问题答案: 编辑: 更新聚合,以便它与熊猫的最新版本一起使用 要将多个函数传递给grou
-
NumPy版本的“指数加权移动平均线”,等效于pandas.ewm()。mean()
问题内容: 像下面的熊猫一样,如何在NumPy中获得指数加权移动平均值? 我用NumPy尝试了以下 但是结果却与大熊猫不同。 是否有更好的方法直接在NumPy中计算指数加权移动平均值并获得与完全相同的结果? 在对熊猫解决方案提出60,000个请求时,我得到了大约230秒。我敢肯定,使用纯NumPy可以大大减少这种情况。 问题答案: 更新于08/06/2019 大型输入的纯,快速和保护的解决方案 用
-
在K-均值Java程序中检索每个簇的质心位置
我有一个Java程序,它将使用我从这里找到的K-Means算法将坐标聚类成2组。我已经成功地获得了每个组中的聚集元素,但是我不确定如何检索每个集群的形心位置。 这是我的节目: 有没有一种方法可以在聚类后检索质心位置?
-
数据表中的行和、平均值、最小值、最大值(如dplyr)?
还有其他关于datatable上的行运算符的帖子。它们要么太简单,要么解决了特定的场景 我这里的问题更一般。有一个使用dplyr的解决方案。我已经尝试过了,但没有找到一个使用数据的等效解决方案。表语法。你能推荐一个优雅的数据吗。与dplyr版本复制相同结果的表解决方案? 编辑1:真实数据集上建议解决方案的基准总结(10MB,73000行,24个数字列上的统计数据)。基准结果是主观的。然而,经过的时
-
spark如何将培训任务平均分配给各个执行者?
-
使用Boost计算C ++中样本向量的均值和标准差
问题内容: 有没有一种方法可以使用Boost计算包含样本的向量的均值和标准差? 还是我必须创建一个累加器并将向量馈入其中? 问题答案: 使用累加器 是 在Boost中计算均值和标准差的方法。
-
Pandas:计算整个数据框的均值或标准差(标准差)
问题内容: 这是我的问题,我有一个像这样的数据框: 我只想计算整个数据帧的平均值,因为以下方法不起作用: 然后我想出了: 但是,此技巧不适用于计算标准偏差。我最后的尝试是: 除了在后一种情况下,它使用了numpy中的mean()和std()函数。这不是平均值的问题,而是std的问题,因为pandas函数默认使用,而不是numpy的where 。 问题答案: 您可以将数据框转换为单列(将形状从5x3
-
用滚动平均值或其他插值替换NaN或缺失值
问题内容: 我有一个熊猫数据框,其中包含每月数据,我想为其计算12个月的移动平均值。但是缺少一月每个月的数据(NaN),所以我正在使用 但这只是给我所有的NaN值。 有没有一种简单的方法可以忽略NaN值?我了解实际上,这将成为11个月的移动平均值。 数据框还有其他包含一月数据的变量,所以我不想只扔掉一月的列并进行11个月的移动平均。 问题答案: 有几种方法可以解决此问题,最好的方法取决于一月份的数