
Pyspark-TypeError:使用reduceByKey计算均值时,“float”对象不可订阅

我的“asdasd.csv”文件具有以下结构。
Index,Arrival_Time,Creation_Time,x,y,z,User,Model,Device,gt
0,1424696633908,1424696631913248572,-5.958191,0.6880646,8.135345,a,nexus4,nexus4_1,stand
1,1424696633909,1424696631918283972,-5.95224,0.6702118,8.136536,a,nexus4,nexus4_1,stand
2,1424696633918,1424696631923288855,-5.9950867,0.6535491999999999,8.204376,a,nexus4,nexus4_1,stand
3,1424696633919,1424696631928385290,-5.9427185,0.6761626999999999,8.128204,a,nexus4,nexus4_1,stand
好的,我得到下面的{key,value}元组来操作它。
# x y z
[(('a', 'nexus4', 'stand'), ((-5.958191, 0.6880646, 8.135345)))]
# part A (key) part B (value)
我的计算平均值的代码如下,我必须计算每一列的平均值,X,Y,Z为每一个键。
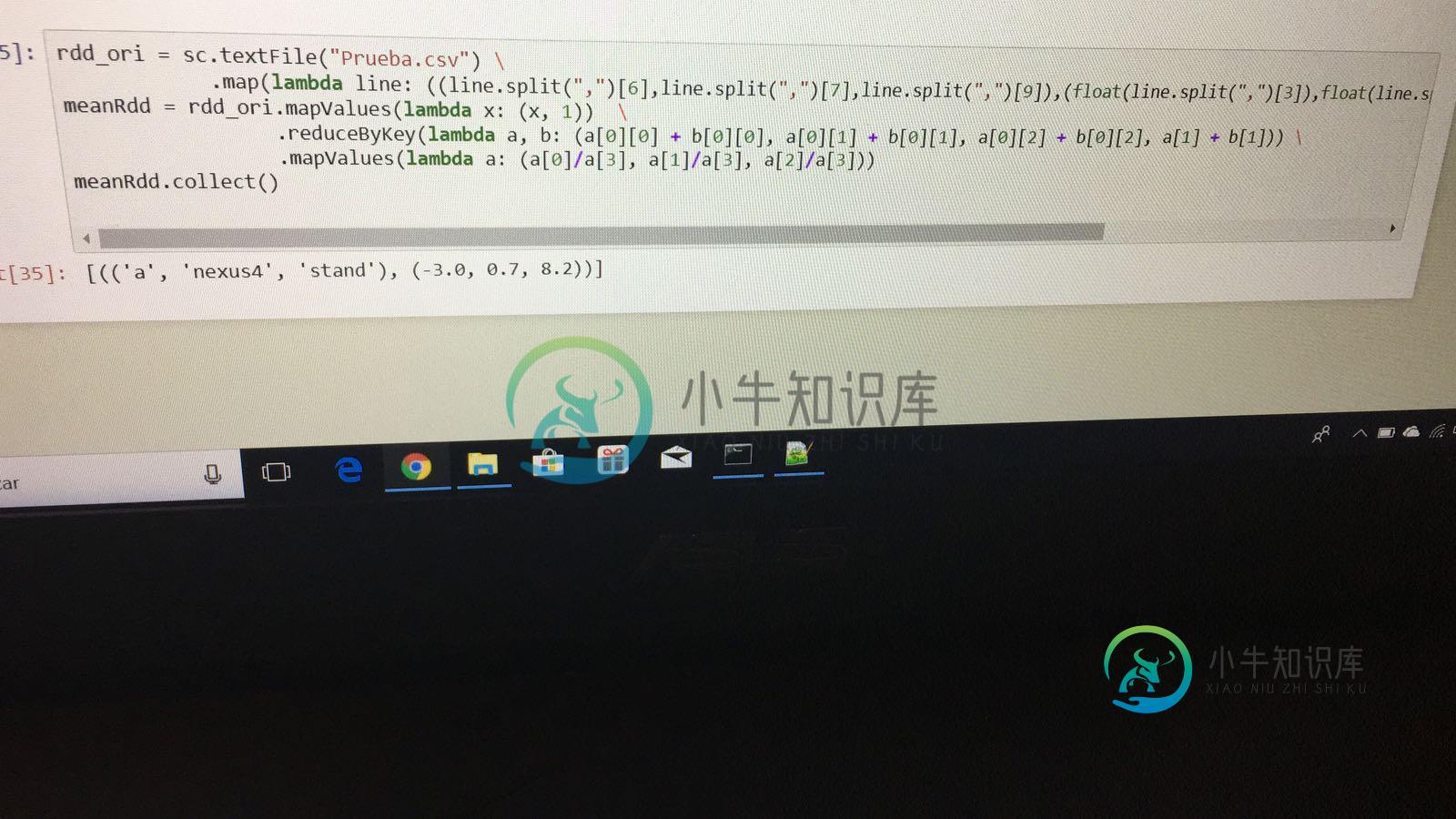
rdd_ori = sc.textFile("asdasd.csv") \
.map(lambda x: ((x.split(",")[6], x.split(",")[7], x.split(",")[9]),(float(x.split(",")[3]),float(x.split(",")[4]),float(x.split(",")[5]))))
meanRDD = rdd_ori.mapValues(lambda x: (x,1)) \
.reduceByKey(lambda a, b: (a[0][0] + b[0][0], a[0][1] + b[0][1], a[0][2] + b[0][2], a[1] + b[1]))\
.mapValues(lambda a : (a[0]/a[3], a[1]/a[3],a[2]/a[3]))
/opt/spark/current/python/pyspark/rdd.py in take(self,num)1341
1342 p=range(partsScanned,min(partsScanned+numPartsToTry,totalParts))->1343 res=self.context.runjob(self,takeUpToNumLeft,p)1344 1345 items+=res
runJob(self,rdd,partitionFunc,partitions,allowLocal)990#sparkcontext#runJob中的/opt/spark/current/python/pyspark/context.py。991 mappedRDD=rdd.mappartitions(partitionFunc)-->992 port=self._jvm.pythonrdd.runjob(self._jsc.sc(),mappdrdd._jrdd,partitions)993返回列表(_load_from_socket(port,mappdrdd._jrdd_deserializer))994
/opt/spark/current/python/lib/py4j-0.10.4-src.zip/py4j/java_gateway.py in call(self,*args)1131应答=self.gateway_client.send_command(command)1132 return_value=get_return_value(->1133应答,self.gateway_client,self.target_id,self.name)1134 1135对于temp_args中的temp_arg:
/opt/spark/current/python/pyspark/sql/utils.py in deco(*a,**kw)61 def deco(*a,**kw):62 try:---->63返回f(*a,**kw)64除py4j.protocol.py4jJavaError为E:65 s=e.java_exception.toString()
/opt/spark/current/python/lib/py4j-0.10.4-src.zip/py4j/protocol.py in get_return_value(应答,gateway_client,target_id,name)317 Rise Py4JJavaError(318“调用{0}{1}{2}时出错.\n”。-->319 format(target_id,“.”,name),value)320 else:321 Rise Py4JError(
PY4JJavaError:调用z:org.apache.spark.api.python.pythonrdd.runjob时出错。:org.apache.spark.sparkException:由于阶段失败而中止的作业:阶段127.0中的任务0失败1次,最近的失败:阶段127.0中丢失的任务0.0(TID 102,本地主机,执行器驱动程序):org.apache.spark.api.python.pythonException:追溯(最近一次调用):文件“/opt/spark/current/python/lib/pyspark.zip/pyspark/worker.py”,第177行,在主进程中()文件“yspark.zip/pyspark/shuffle.py“,第238行,在mergeValues中d[k]=comb(d[k],v)如果k在d else creator(v)File中”“,第3行,在typeerror中:”float“对象不是subscriptable
共有1个答案

以下是reducebykey的工作原理。我以您的示例为例,即通过以下数据将其传递给reducebykey
# x y z
[(('a', 'nexus4', 'stand'), ((-5.958191, 0.6880646, 8.135345), 1))]
# part A (key) part B (value) counter
让我一步一步走
执行以下mapvalues函数后
rdd_ori.mapValues(lambda x: (x,1))
((u'a', u'nexus4', u'stand'), ((-5.9427185, 0.6761626999999999, 8.128204), 1))
((u'a', u'nexus4', u'stand'), ((-5.958191, 0.6880646, 8.135345), 1))
((u'a', u'nexus4', u'stand'), ((-5.95224, 0.6702118, 8.136536), 1))
((u'a', u'nexus4', u'stand'), ((-5.9950867, 0.6535491999999999, 8.204376), 1))
因此,当reducebykey被调用为
.reduceByKey(lambda a, b: (a[0][0] + b[0][0], a[0][1] + b[0][1], a[0][2] + b[0][2], a[1] + b[1]))
由于在您的情况下,所有键都是相同的,因此在下面的迭代中将值传递给A和B变量。
在第一次迭代中,A为((-5.9427185,0.676162699999999,8.128204),1),B为(-5.958191,0.6880646,8.135345),1),因此计算部分(A[0][0]+B[0][0],A[0][1]+B[0][1],A[0][2]+B[0][2],A[1]+B[1])是正确的,并通过。
在第二次迭代中,A是(A[0][0]+B[0][0],A[0][1]+B[0][1],A[0][2]+B[0][2],A[1]+B[1])的输出,它是(-11.9104309999999999,1.3582764,16.271881,2)
因此,如果您查看数据的格式,在A中没有这样的A[0][0]。您只需获得A[0]和A[1]。等等。这就是问题所在。这也是错误消息所暗示的。
TypeError:“float”对象不可订阅
解决方法是格式化数据,以便您可以将A作为A[0][0]访问,如果您将ReduceByKey格式化为以下格式,则可以这样做。
.reduceByKey(lambda a, b: ((a[0][0] + b[0][0], a[0][1] + b[0][1], a[0][2] + b[0][2]), a[1] + b[1]))
但这会困扰您的最后一个mapvalues函数
.mapValues(lambda a : (a[0]/a[3], a[1]/a[3],a[2]/a[3]))
所以您的最后一个mapvalues应该是
.mapValues(lambda a : (a[0][0]/a[1], a[0][1]/a[1],a[0][2]/a[1]))
因此,总的来说,下面的代码应该对您有效
rdd_ori = sc.textFile("asdasd.csv") \
.map(lambda x: ((x.split(",")[6], x.split(",")[7], x.split(",")[9]),(float(x.split(",")[3]),float(x.split(",")[4]),float(x.split(",")[5]))))
meanRDD = rdd_ori.mapValues(lambda x: (x, 1)) \
.reduceByKey(lambda a, b: ((a[0][0] + b[0][0], a[0][1] + b[0][1], a[0][2] + b[0][2]), a[1] + b[1]))\
.mapValues(lambda a : (a[0][0]/a[1], a[0][1]/a[1],a[0][2]/a[1]))
我希望我已经解释得足够好了。
-
问题内容: 基本上,我有一个输入,用户会将数字值(浮动输入)放入其中,然后将所有这些上述列表索引设置为该值。出于某种原因,我无法在没有设置的情况下设置它们: 错误。我是在做错事还是只是以错误的方式看待它? 问题答案: 是一个花车。正在尝试访问浮点数的第一个元素。相反,做 要么
-
当我试图在python中打开一个文件时,我得到了错误,typeerror'_csv.reader'对象是不可订阅的。代码如下,有人能帮我吗 在以下代码中,读卡器[:1]中的行出现错误: 我需要跳过第一行,因为它有标题,这就是为什么我做读者[: 1]
-
我正在学习Django和Rest框架,我有一个小项目要练习,但我在试图访问http://localhost:8000/admin:typeerror时出错:对象'module'不可订阅。 以下是我创建的Python文件: 文件“/home/jesus/.local/lib/python3.8/site-packages/django/core/handlers/base.py”,第115行,在_g
-
我可以从一个简单的脚本成功加载TextBlob模块,但不能从Flask应用程序加载。我将向您展示代码和错误。 加载一个简单的脚本工作: 从烧瓶应用程序加载时抛出错误: 错误: 我使用的是textblob版本0.11。0与pip一起安装。
-
问题内容: 我尝试在视图中使用,但收到错误`TypeError:’bool’对象不可调用。为什么会出现此错误,我该如何解决? 问题答案: 当您尝试表现对象的方法或功能时,会发生“对象不可调用”错误。 在这种情况下: 您将current_user.is_authenticated表现为一种方法,而不是一种方法。 您必须以这种方式使用它: 您在方法或函数(而不是对象)之后使用“()”。 在某些情况下,
-
问题内容: 为什么会出现此错误?我很困惑。 你需要知道什么才能回答我的问题? 问题答案: 是一个包含的模块。 你需要执行以下操作: 这就是错误消息的含义: 它表示为,因为你的代码正在调用模块对象。模块对象是导入模块时得到的东西的类型。你试图做的是在模块对象中调用恰好与包含它的模块同名的类对象。 这是一种从逻辑上分解这种错误的方法: “ 告诉我我的代码试图调用无法调用的内容。我的代码试图调用什么?”