
在R中的时间序列图中添加移动平均图

我在ggplot2包中有一个时间序列的图,我已经执行了移动平均,我想把移动平均的结果添加到时间序列的图中。
数据集样本(p31):
ambtemp DT
-1.14 2007-09-29 00:01:57
-1.12 2007-09-29 00:03:57
-1.33 2007-09-29 00:05:57
-1.44 2007-09-29 00:07:57
-1.54 2007-09-29 00:09:57
-1.29 2007-09-29 00:09:57
-1.29 2007-09-29 00:11:57
Require(ggplot2)
library(scales)
p29$dt=strptime(p31$dt, "%Y-%m-%d %H:%M:%S")
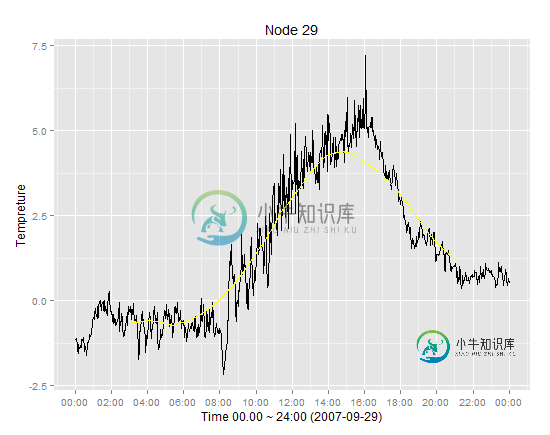
ggplot(p29, aes(dt, ambtemp)) + geom_line() +
scale_x_datetime(breaks = date_breaks("2 hour"),labels=date_format("%H:%M")) + xlab("Time 00.00 ~ 24:00 (2007-09-29)") + ylab("Tempreture")+
opts(title = ("Node 29"))
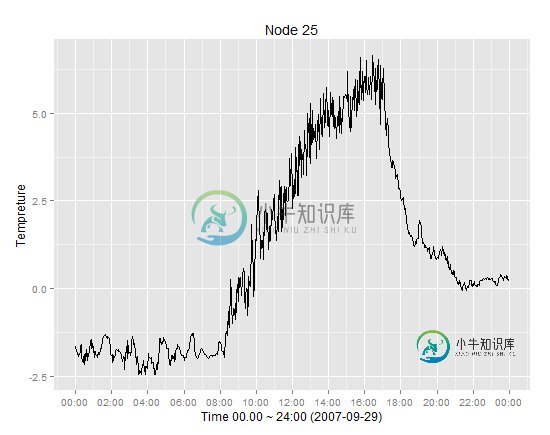
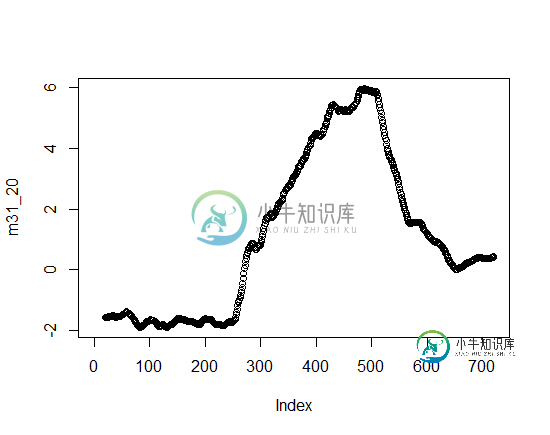
挑战在于,时间序列数据OV=btain来自数据集,其中包括时间戳和温度,而移动平均数据只包括平均列而不包括时间戳,拟合这两个数据可能会导致不一致。
共有1个答案

一个解决方案是使用libraryZoo中的rollmean()函数来计算移动平均值。
在你的问题(p31和p29)中有一些数据帧名称的混淆,所以我将使用p29。
p29$dt=strptime(p29$dt, "%Y-%m-%d %H:%M:%S")
library(zoo)
#Make zoo object of data
temp.zoo<-zoo(p29$ambtemp,p29$dt)
#Calculate moving average with window 3 and make first and last value as NA (to ensure identical length of vectors)
m.av<-rollmean(temp.zoo, 3,fill = list(NA, NULL, NA))
#Add calculated moving averages to existing data frame
p29$amb.av=coredata(m.av)
#Add additional line for moving average in red
ggplot(p29, aes(dt, ambtemp)) + geom_line() +
geom_line(aes(dt,amb.av),color="red") +
scale_x_datetime(breaks = date_breaks("5 min"),labels=date_format("%H:%M")) +
xlab("Time 00.00 ~ 24:00 (2007-09-29)") + ylab("Tempreture")+
ggtitle("Node 29")
如果线条颜色应该出现在图例中,那么必须修改ggplot()中的aes()和geom_line()并添加scale_colour_manual()。
ggplot(p29, aes(dt)) + geom_line(aes(y=ambtemp,colour="real")) +
geom_line(aes(y=amb.av,colour="moving"))+
scale_x_datetime(breaks = date_breaks("5 min"),labels=date_format("%H:%M")) +
xlab("Time 00.00 ~ 24:00 (2007-09-29)") + ylab("Tempreture")+
scale_colour_manual("Lines", values=c("real"="black", "moving"="red")) +
ggtitle("Node 29")
-
对于相同的数据集和相同的时间间隔,我有时间序列数据和移动平均数据。我想摘录重叠之处。我想提取当前和最后一个交叉点(移动平均线和时间序列之间的交叉点)之间的极值的点,这取决于趋势反演的方向。我不知道是基于表来执行它(1-时间序列表包括温度和时间戳2-移动平均表只包括温度的移动平均结果)还是基于它们的图来执行它,我在时间序列图中添加了移动平均。 时间序列表: 移动平均线表:
-
我有一个视图,其中有2个listviews绑定到CollectionViewSources,这些CollectionViewSources是从我的视图模型 每个listview项都被模板化为一个textblock和一个Button-UnitsinMeasureListView.ItemTemplate按钮绑定到一个命令,该命令将该项从其绑定的集合中移除,并将其添加到AvailableUnitsLi
-
在我的模型中,我有9个不同的服务块,每个服务可以产生9个不同的特性。每种组合都有不同的延迟时间和标准差。例如,特征3在服务块8中需要5分钟的偏差为0.05,但在服务块4中只需要3分钟的偏差为0.1。 我如何永久跟踪每个组合的最后5个需要的次数,并计算平均值(像一个移动平均线)?我想用平均值来让产品根据最短的时间来决定为各自的功能选择哪一个服务块,比较所有机器为各自的功能所做的过去时间。产品代理已经
-
我有一个数据帧,其中的行与name列重复,但与value列不重复: 我需要将重复的名称聚合到一行中,同时计算值列的平均值。预期产出如下: 我已经尝试使用< code>df[duplicated(df$name),],但是这当然不能说明重复的含义。我想使用< code>aggregate(),但问题是这个函数有趣的部分也适用于所有其他列,而且在其他问题中,它不能计算char内容。由于所有其他列在“副
-
问题内容: 我正在写一个使用numpy中的卷积函数的移动平均函数,它应该等效于(加权移动平均)。当我的权重全部相等时(如简单的算术平均值),它可以正常工作: 给 但是,当我尝试使用加权平均值时 而不是(对于相同的数据)3.667,4.667,5.667,6.667,…我希望,我得到 如果删除“有效”标志,则什至看不到正确的值。我真的很想对WMA和MA使用convolve,因为它可以使代码更整洁(相
-
问题内容: 我正在为Pyspark中的时间序列编写异常检测算法。我想计算(-3,3)或(-4,4)窗口的加权移动平均值。现在,我正在使用滞后和超前窗口功能,并将它们乘以一组权重。我的窗口当前是(-2,2)。 我想知道是否有另一种方法可以计算Pyspark中的加权移动平均值。 我正在使用的当前代码是: 问题答案: 您可以概括当前的代码: 它可以用作: 注意事项 : 您可能会考虑将滞后缺失的帧的结果标