
利用移动平均寻找时间序列数据集的模式

对于相同的数据集和相同的时间间隔,我有时间序列数据和移动平均数据。我想摘录重叠之处。我想提取当前和最后一个交叉点(移动平均线和时间序列之间的交叉点)之间的极值的点,这取决于趋势反演的方向。我不知道是基于表来执行它(1-时间序列表包括温度和时间戳2-移动平均表只包括温度的移动平均结果)还是基于它们的图来执行它,我在时间序列图中添加了移动平均。
时间序列表:
ambtemp dt
1 -1.14 2007-09-29 00:01:57
2 -1.12 2007-09-29 00:03:57
3 -1.33 2007-09-29 00:05:57
4 -1.44 2007-09-29 00:07:57
5 -1.54 2007-09-29 00:09:57
6 -1.29 2007-09-29 00:11:57
7 -1.42 2007-09-29 00:13:57
8 -1.37 2007-09-29 00:15:57
9 -1.32 2007-09-29 00:17:57
10 -1.37 2007-09-29 00:19:57
11 -1.14 2007-09-29 00:21:57
12 -1.16 2007-09-29 00:23:57
13 -1.08 2007-09-29 00:25:57
14 -1.21 2007-09-29 00:27:57
15 -1.26 2007-09-29 00:29:57
16 -1.50 2007-09-29 00:31:57
17 -1.35 2007-09-29 00:33:57
18 -1.56 2007-09-29 00:35:57
19 -1.60 2007-09-29 00:37:57
20 -1.30 2007-09-29 00:39:57
21 -1.24 2007-09-29 00:41:57
22 -1.24 2007-09-29 00:43:57
23 -1.10 2007-09-29 00:45:57
24 -0.99 2007-09-29 00:47:57
25 -1.04 2007-09-29 00:49:57
26 -0.97 2007-09-29 00:51:57
27 -0.92 2007-09-29 00:53:57
28 -0.70 2007-09-29 00:55:57
29 -0.58 2007-09-29 00:57:57
30 -0.49 2007-09-29 00:59:57
31 -0.54 2007-09-29 01:01:57
32 -0.37 2007-09-29 01:03:57
33 -0.24 2007-09-29 01:05:57
34 -0.34 2007-09-29 01:07:57
35 -0.43 2007-09-29 01:09:57
36 -0.52 2007-09-29 01:11:57
37 -0.16 2007-09-29 01:13:57
38 -0.50 2007-09-29 01:15:57
39 -0.15 2007-09-29 01:17:57
40 -0.04 2007-09-29 01:19:57
41 0.00 2007-09-29 01:21:57
42 -0.08 2007-09-29 01:23:57
43 -0.30 2007-09-29 01:25:57
44 -0.14 2007-09-29 01:27:57
45 -0.06 2007-09-29 01:29:57
46 -0.02 2007-09-29 01:31:57
47 -0.25 2007-09-29 01:33:57
48 -0.33 2007-09-29 01:35:57
49 0.01 2007-09-29 01:37:57
50 -0.28 2007-09-29 01:39:57
51 -0.26 2007-09-29 01:41:57
52 -0.34 2007-09-29 01:43:57
53 -0.43 2007-09-29 01:45:57
54 -0.20 2007-09-29 01:47:57
55 0.19 2007-09-29 01:49:57
56 0.28 2007-09-29 01:51:57
57 0.07 2007-09-29 01:53:57
58 -0.32 2007-09-29 01:55:57
59 -0.20 2007-09-29 01:57:57
60 -0.42 2007-09-29 01:59:57
61 -0.40 2007-09-29 02:01:57
62 -0.54 2007-09-29 02:03:57
63 -0.67 2007-09-29 02:05:57
64 -0.42 2007-09-29 02:07:57
65 -0.57 2007-09-29 02:09:57
66 -0.73 2007-09-29 02:11:57
67 -0.54 2007-09-29 02:13:57
68 -0.70 2007-09-29 02:15:57
69 -0.70 2007-09-29 02:17:57
70 -0.58 2007-09-29 02:19:57
移动平均线表:
[1] NA NA NA NA NA NA NA NA NA
[10] NA NA NA NA NA NA NA NA NA
[19] NA -1.3250 -1.3300 -1.3360 -1.3245 -1.3020 -1.2770 -1.2610 -1.2360
[28] -1.2025 -1.1655 -1.1215 -1.0915 -1.0520 -1.0100 -0.9665 -0.9250 -0.8760
[37] -0.8165 -0.7635 -0.6910 -0.6280 -0.5660 -0.5080 -0.4680 -0.4255 -0.3765
[46] -0.3290 -0.2955 -0.2770 -0.2475 -0.2370 -0.2230 -0.2215 -0.2310 -0.2240
[55] -0.1930 -0.1530 -0.1415 -0.1325 -0.1350 -0.1540 -0.1740 -0.1970 -0.2155
[64] -0.2295 -0.2550 -0.2905 -0.3050 -0.3235 -0.3590 -0.3740 -0.3860 -0.3880
[73] -0.3695 -0.4045 -0.4450 -0.4900 -0.5125 -0.5215 -0.5515 -0.5825 -0.6140
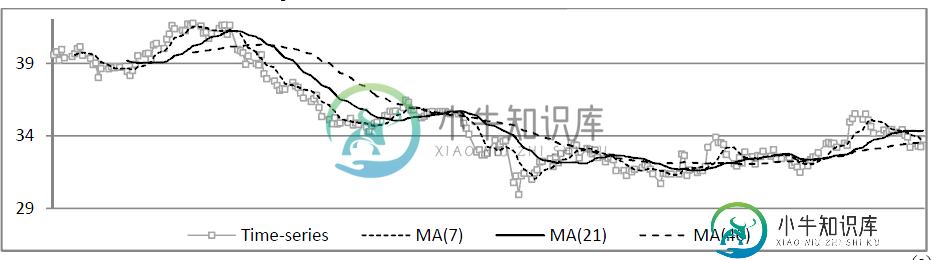
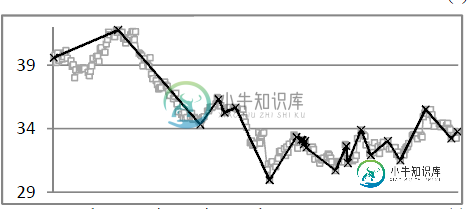
共有1个答案

一旦你有了正确的设置,这是一个简单的三步过程。
第一步:对这类事情使用一个严肃的时间序列包。我建议xts--太棒了。
步骤2:一旦您有了这种格式,它只是几个滞后命令和几个逻辑测试。
require(xts)
require(TTR)
dd <- read.table("~/Downloads/Timeseries.txt", skip=1)
dd <- dd[,-1] # cut off the row numbers
colnames(dd) <- c('ambtemp', 'date', 'time')
dt <- as.POSIXct(paste(dd$date, dd$time))
tempdata_x <- xts(dd$ambtemp, order.by = dt)
colnames(tempdata_x) <- 'ambtemp'
tempdata_x$ma20 <- SMA(tempdata_x$ambtemp, n=20)
max(diff(tempdata_x$ambtemp), na.rm=TRUE)
[1] 1.92
match(max(diff(tempdata_x$ambtemp), na.rm=TRUE), diff(tempdata_x$ambtemp))
[1] 357
tempdata_x$overlap <- ifelse(tempdata_x$ambtemp == tempdata_x$ma20, 1, 0)
tempdata_x$aboveMA <- ifelse(tempdata_x$ambtemp > tempdata_x$ma20, 1, 0)
tempdata_x$belowMA <- ifelse(tempdata_x$ambtemp < tempdata_x$ma20, 1, 0)
tempdata_x$crossUp <- ifelse(lag(tempdata_x$belowMA) & tempdata_x$aboveMA, 1, 0)
tempdata_x$crossDown <- ifelse(lag(tempdata_x$aboveMA) & tempdata_x$belowMA, 1, 0)
现在,您的数据帧tempdata_x有了一些新列--我们稍后将使用这些列进行索引。
当ambtemp==ma20时标记为1的列重叠;当ambtemp>ma20时,aboveMA标记为1;当ambtemp
限制在有移动平均线的情况下(去掉领先部分)
tempdata_x.trim <- tempdata_x[complete.cases(tempdata_x),]
tempdata_x.trim[as.logical(tempdata_x.trim$overlap), 1:2]
tempdata_x.trim[as.logical(tempdata_x.trim$aboveMA), 1:2]
tempdata_x.trim[as.logical(tempdata_x.trim$belowMA), 1:2]
tempdata_x.trim[as.logical(tempdata_x.trim$crossUp), 1:2]
tempdata_x.trim[as.logical(tempdata_x.trim$crossDown), 1:2]
-
我在ggplot2包中有一个时间序列的图,我已经执行了移动平均,我想把移动平均的结果添加到时间序列的图中。 数据集样本(p31): ambtemp DT -1.14 2007-09-29 00:01:57 -1.12 2007-09-29 00:03:57 -1.33 2007-09-29 00:05:57 -1.44 2007-09-29 00:07:57 -1.54 2007-09-29 00
-
Python是否有一个SciPy函数或NumPy函数或模块来计算给定特定窗口的一维数组的运行平均值?
-
本文向大家介绍利用python实现平稳时间序列的建模方式,包括了利用python实现平稳时间序列的建模方式的使用技巧和注意事项,需要的朋友参考一下 一、平稳序列建模步骤 假如某个观察值序列通过序列预处理可以判定为平稳非白噪声序列,就可以利用ARMA模型对该序列进行建模。建模的基本步骤如下: (1)求出该观察值序列的样本自相关系数(ACF)和样本偏自相关系数(PACF)的值。 (2)根据样本自相关系
-
在我的模型中,我有9个不同的服务块,每个服务可以产生9个不同的特性。每种组合都有不同的延迟时间和标准差。例如,特征3在服务块8中需要5分钟的偏差为0.05,但在服务块4中只需要3分钟的偏差为0.1。 我如何永久跟踪每个组合的最后5个需要的次数,并计算平均值(像一个移动平均线)?我想用平均值来让产品根据最短的时间来决定为各自的功能选择哪一个服务块,比较所有机器为各自的功能所做的过去时间。产品代理已经
-
编辑:我已经更改了模式,以便做出一些澄清。 每天都会为当天创建一个新表。所以一个表只包含一天的日志。 我的查询条件如下。 查询特定用户在特定日期(日期而不是时间)的所有日志。 因此原因、项目、价格和计数根本不会用作查询的提示或条件。
-
我又用Python玩了一点,我找到了一本有例子的整洁的书。其中一个例子是绘制一些数据。我有一个有两列的。txt文件,我有数据。我把数据绘制得很好,但在练习中,它说:进一步修改程序,计算并绘制数据的运行平均值,定义如下: 其中在本例中(并且是数据文件中的第二列)。使程序将原始数据和运行平均值绘制在同一张图上。 到目前为止我有这个: 非常感谢^^:)