
用Python从数据点求移动平均线

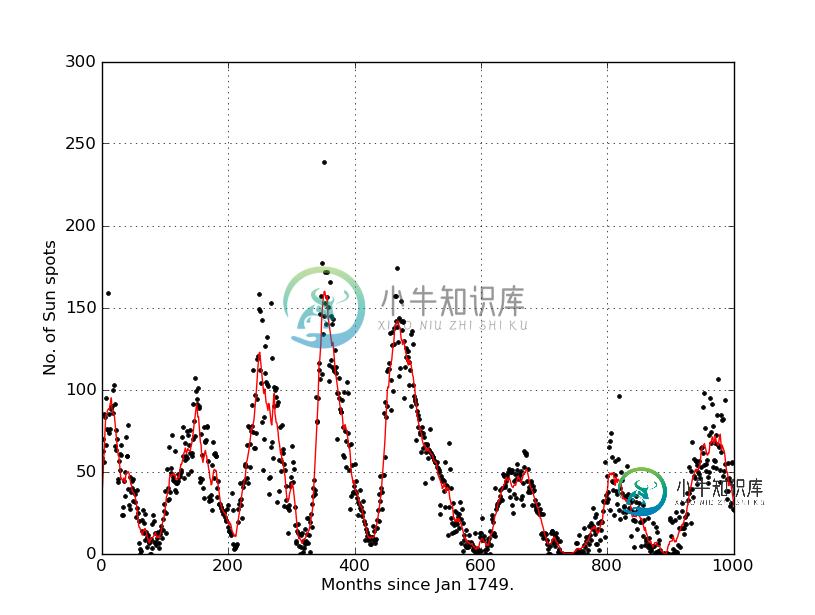
我又用Python玩了一点,我找到了一本有例子的整洁的书。其中一个例子是绘制一些数据。我有一个有两列的。txt文件,我有数据。我把数据绘制得很好,但在练习中,它说:进一步修改程序,计算并绘制数据的运行平均值,定义如下:
$Y_k=\frac{1}{2r}\sum_{m=-r}^r y_{k+m}$
其中r=5在本例中(并且y_k是数据文件中的第二列)。使程序将原始数据和运行平均值绘制在同一张图上。
到目前为止我有这个:
from pylab import plot, ylim, xlim, show, xlabel, ylabel
from numpy import linspace, loadtxt
data = loadtxt("sunspots.txt", float)
r=5.0
x = data[:,0]
y = data[:,1]
plot(x,y)
xlim(0,1000)
xlabel("Months since Jan 1749.")
ylabel("No. of Sun spots")
show()
from __future__ import division
from pylab import plot, ylim, xlim, show, xlabel, ylabel, grid
from numpy import linspace, loadtxt, ones, convolve
import numpy as numpy
data = loadtxt("sunspots.txt", float)
def movingaverage(interval, window_size):
window= numpy.ones(int(window_size))/float(window_size)
return numpy.convolve(interval, window, 'same')
x = data[:,0]
y = data[:,1]
plot(x,y,"k.")
y_av = movingaverage(y, 10)
plot(x, y_av,"r")
xlim(0,1000)
xlabel("Months since Jan 1749.")
ylabel("No. of Sun spots")
grid(True)
show()
非常感谢^^:)
共有1个答案

由于numpy.convolve非常慢,那些需要快速执行的解决方案的人可能更喜欢更容易理解的cumsum方法。代码如下:
cumsum_vec = numpy.cumsum(numpy.insert(data, 0, 0))
ma_vec = (cumsum_vec[window_width:] - cumsum_vec[:-window_width]) / window_width
其中data包含您的数据,ma_vec将包含window_width长度的移动平均值。
平均而言,cumsum的速度大约是Convolve的30-40倍。
-
Python是否有一个SciPy函数或NumPy函数或模块来计算给定特定窗口的一维数组的运行平均值?
-
问题内容: 美好的一天, 我正在使用以下代码来计算9天移动平均线。 但这是行不通的,因为它会在调用限制之前先计算所有返回的字段。换句话说,它将计算该日期之前或等于该日期的所有关闭时间,而不仅仅是最后9个。 因此,我需要从返回的选择中计算出SUM,而不是直接计算出来。 IE浏览器 从SELECT中选择SUM … 现在我将如何去做,这是非常昂贵的还是有更好的方法? 问题答案: 使用类似 内查询返回的所
-
我也看过Pyspark中的加权移动平均线,但我需要一个Spark/Scala的方法,以及10天或30天的均线。 有什么想法吗?
-
问题内容: 我有一个日期范围,并且每个日期都有一个度量值。我想计算每个日期的指数移动平均值。有人知道怎么做这个吗? 我是python的新手。似乎没有将平均值内置到标准python库中,这让我感到有些奇怪。也许我找的地方不对。 因此,给定以下代码,如何计算日历日期的IQ点的移动加权平均值? (可能是一种更好的数据结构方式,任何建议将不胜感激) 问题答案: 编辑:看来SciKits(补充SciPy的附
-
公式链接:https://sciencing.com/calculate-exponential-moving-averages-8221813.html
-
问题内容: 我有一个二维的numpy数组。我想对每个条目取n个最近条目的平均值,就像对一维数组取滑动平均值一样。什么是最干净的方法? 问题答案: 这与将 滤镜 应用于 图像的 概念类似。 幸运的是,有很多功能可以做到这一点。您所追求的是。 可以这样使用: 如果您需要5x5滤镜,请使用。该选项控制如何处理边缘。您没有指定要如何处理边缘。在此示例中,“常量”模式表示将数组边界之外的每个项目都视为常量值