《均衡》专题
-
如何在平均值为4的范围(2,10)中创建随机数
我需要在一个具有特定平均值的范围内创建数字。我尝试在excel中使用Rand在中间函数,但是,我无法考虑平均值。有没有办法从符合标准的分布中获取随机数?
-
根据最近3天数据动态计算移动平均线[PySpark]
我想根据最近3天的数字计算每个customer_id和日期的移动平均值。为了计算5月4日的移动平均数,我们需要计算5月1-3日的平均购买量 输出火花DF
-
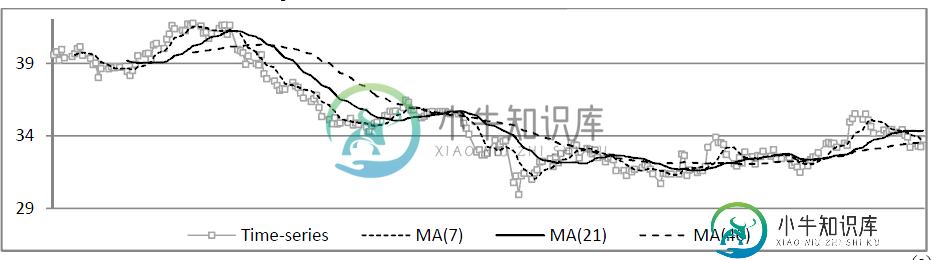 利用移动平均寻找时间序列数据集的模式
利用移动平均寻找时间序列数据集的模式对于相同的数据集和相同的时间间隔,我有时间序列数据和移动平均数据。我想摘录重叠之处。我想提取当前和最后一个交叉点(移动平均线和时间序列之间的交叉点)之间的极值的点,这取决于趋势反演的方向。我不知道是基于表来执行它(1-时间序列表包括温度和时间戳2-移动平均表只包括温度的移动平均结果)还是基于它们的图来执行它,我在时间序列图中添加了移动平均。 时间序列表: 移动平均线表:
-
带有“用户数”与“平均响应时间”的Jmeter报告图表
JMETER中是否有任何可用的报告/图表,我可以在其中看到一次的用户数量与被测应用程序的响应时间。这将帮助我确定应用程序在特定负载下的性能
-
java - 是否所有语言编写的程序均有入口文件?
部分语言明确有入口文件: 例如 Java 语言中通常有一个包含 main 方法的类作为程序的入口点。这个类文件可以被视为一种入口文件的形式,程序从这个特定的类开始执行。 C 和 C++ 语言通常也有一个 main 函数作为程序的起始点,源文件中包含这个 main 函数的可以被看作类似入口文件的存在。 那么是否是所有高级语言在写的项目中,是否都有入口文件呢? 也就是说写项目,是否都会一般给1个入口文
-
2.3.3 Dubbo 负载均衡策略和集群容错策略都有哪些?动态代理策略呢?
面试题 dubbo 负载均衡策略和集群容错策略都有哪些?动态代理策略呢? 面试官心理分析 继续深问吧,这些都是用 dubbo 必须知道的一些东西,你得知道基本原理,知道序列化是什么协议,还得知道具体用 dubbo 的时候,如何负载均衡,如何高可用,如何动态代理。 说白了,就是看你对 dubbo 熟悉不熟悉: dubbo 工作原理:服务注册、注册中心、消费者、代理通信、负载均衡; 网络通信、序列化:
-
GKE入口为负载均衡器创建多个后端服务,而NGINX入口仅创建一个
在使用GKE ingress时,我观察到GKE ingress为负载平衡器创建了多个后端服务,这导致后端服务如此之多,我们甚至面临后端服务作为其全局配额的配额耗尽问题。我的问题是,尽管ingress中有多条路径规则,但为什么NGINX ingress controller不像GCE ingress那样创建多个后端服务。我阅读了这里的文档, https://cloud.google.com/kube
-
将所有TCP和UDP端口从负载均衡器转发到Azure Kubernetes服务上的nginx入口
null null 是否可以将来自负载均衡器的所有端口直接路由到Azure Kubernetes服务下的NGINX入口 对我的用例的其他建议
-
我无法通过for循环获得整数的平均值,它一直给我0,但我需要第一个数字之后的数字的平均值
代码应该得到第一个数字之后的数字的平均值,所以对于第一行[3 1 2 3],平均值是2.0,因为(1 2 3=6/3=2.0),但代码只给了我0。
-
基于mysql+mycat搭建稳定高可用集群负载均衡主备复制读写分离操作
本文向大家介绍基于mysql+mycat搭建稳定高可用集群负载均衡主备复制读写分离操作,包括了基于mysql+mycat搭建稳定高可用集群负载均衡主备复制读写分离操作的使用技巧和注意事项,需要的朋友参考一下 数据库性能优化普遍采用集群方式,oracle集群软硬件投入昂贵,今天花了一天时间搭建基于mysql的集群环境。 主要思路 简单说,实现mysql主备复制-->利用mycat实现负载均衡。 比较
-
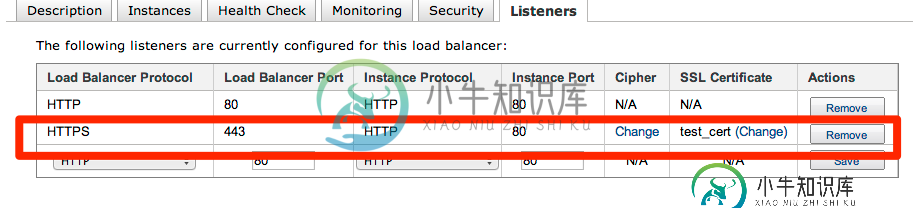 在aws弹性负载均衡器上使https与自签名证书一起工作时遇到麻烦
在aws弹性负载均衡器上使https与自签名证书一起工作时遇到麻烦我使用自签名证书在我的aws弹性负载均衡器上配置https时遇到了问题。在我完成设置之后,连接到httpsendpoint就不起作用了。http连接还是可以的。 我是这么做的。 > 使用此命令生成自签名证书 openssl rsa-in privatekey.key-check openssl x509-in certificate.crt-text-noout 将证书、密钥和证书转换为.pem编
-
解决所有Java字节均已签名的最佳方法是什么?
问题内容: 在Java中,没有无符号字节之类的东西。 使用一些低级代码,有时您需要使用无符号值大于128的字节,由于MSB被用作符号,因此Java会将其解释为负数。 解决此问题的好方法是什么?(说不使用Java不是一种选择) 问题答案: 从数组读取任何单个值时,请将其复制到short或int之类的值中,然后将负数手动转换为正值。 写入数组时,可以执行类似的转换。
-
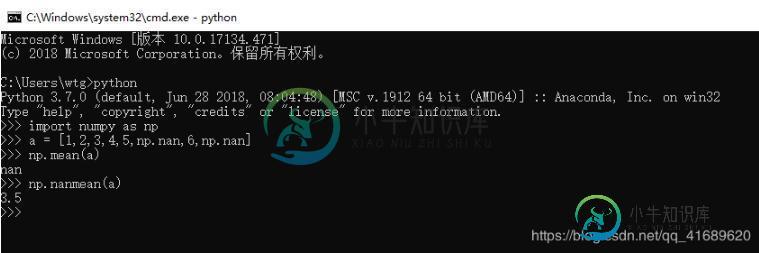 Python 实现将numpy中的nan和inf,nan替换成对应的均值
Python 实现将numpy中的nan和inf,nan替换成对应的均值本文向大家介绍Python 实现将numpy中的nan和inf,nan替换成对应的均值,包括了Python 实现将numpy中的nan和inf,nan替换成对应的均值的使用技巧和注意事项,需要的朋友参考一下 nan:not a number inf:infinity;正无穷 numpy中的nan和inf都是float类型 t!=t 返回bool类型的数组(矩阵) np.count_nonzero(
-
两个日期之间的平均差异(按第三个字段分组)?
问题内容: 假设我们有3个领域, 用户启动和停止多个记录,例如下面的bob已启动和停止了两个记录。 我需要知道每个用户(即按用户分组,而不仅是每一行)的平均时间(即开始和结束之间的时间差),以小时为单位。 我不太了解如何进行差异,平均和分组?有什么帮助吗? 问题答案: 您没有为差异指定所需的粒度。这可以在几天内完成: 如果要以秒为单位,请使用: datediff可以通过更改第一个参数(ss,mi,
-
按多个键分组并汇总/列出词典列表的平均值
问题内容: 请问用多个键分组并汇总/平均使用Python词典列表的值的最pythonic方法是什么?假设我有以下词典列表: 所需的汇总输出: 或平均: 我发现了这一点:用Python组合并汇总字典列表的值,但这似乎没有给我我想要的东西。 问题答案: 获取汇总结果 输出量 为了获得平均值,您可以像这样简单地更改for循环内的内容 输出量 建议: 无论如何,我会像这样同时添加和和 输出量