
Spark性能:本地比集群快(执行器负载非常不均匀)

让我先说我对spark相对来说是新手,所以如果我说了一些没有意义的话,请纠正我。
总结一下这个问题,不管我做什么,在某些阶段,一个执行器做所有的计算,这使得集群执行比本地的单处理器执行慢。
完整故事:我编写了一个Spark1.6应用程序,它由一系列映射、过滤器、连接和一个简短的graphx部分组成。该应用程序只使用一个数据源-csv文件。出于开发的目的,我创建了一个由100,000行7MB组成的模型数据集,所有字段都具有分布均匀的随机数据(在文件中也有随机排序)。这些连接是PairRDD上各个字段上的自内连接(数据集有重复键,每个键有大约200个重复项来引入真实数据),导致键内的笛卡尔积。然后,我对联接的结果执行一些映射和筛选操作,将其存储为一些定制类对象的RDD,并将所有内容保存为与处的图。
我在笔记本电脑上开发了代码并运行它,大约花了5分钟(windows机器,本地文件)。令我惊讶的是,当我将jar部署到集群上(主纱,集群模式,文件在csv中,在HDFS中)并提交它时,代码执行了8分钟。我用较小的数据运行了同样的实验,结果是本地40秒,集群1.1分钟。
当我查看历史服务器时,我看到有两个阶段特别长(每个阶段几乎4分钟),在这些阶段中,有一个任务占用了超过90%的时间。我多次运行代码,尽管每次都部署在不同的数据节点上,但都是相同的任务,需要花费大量的时间。
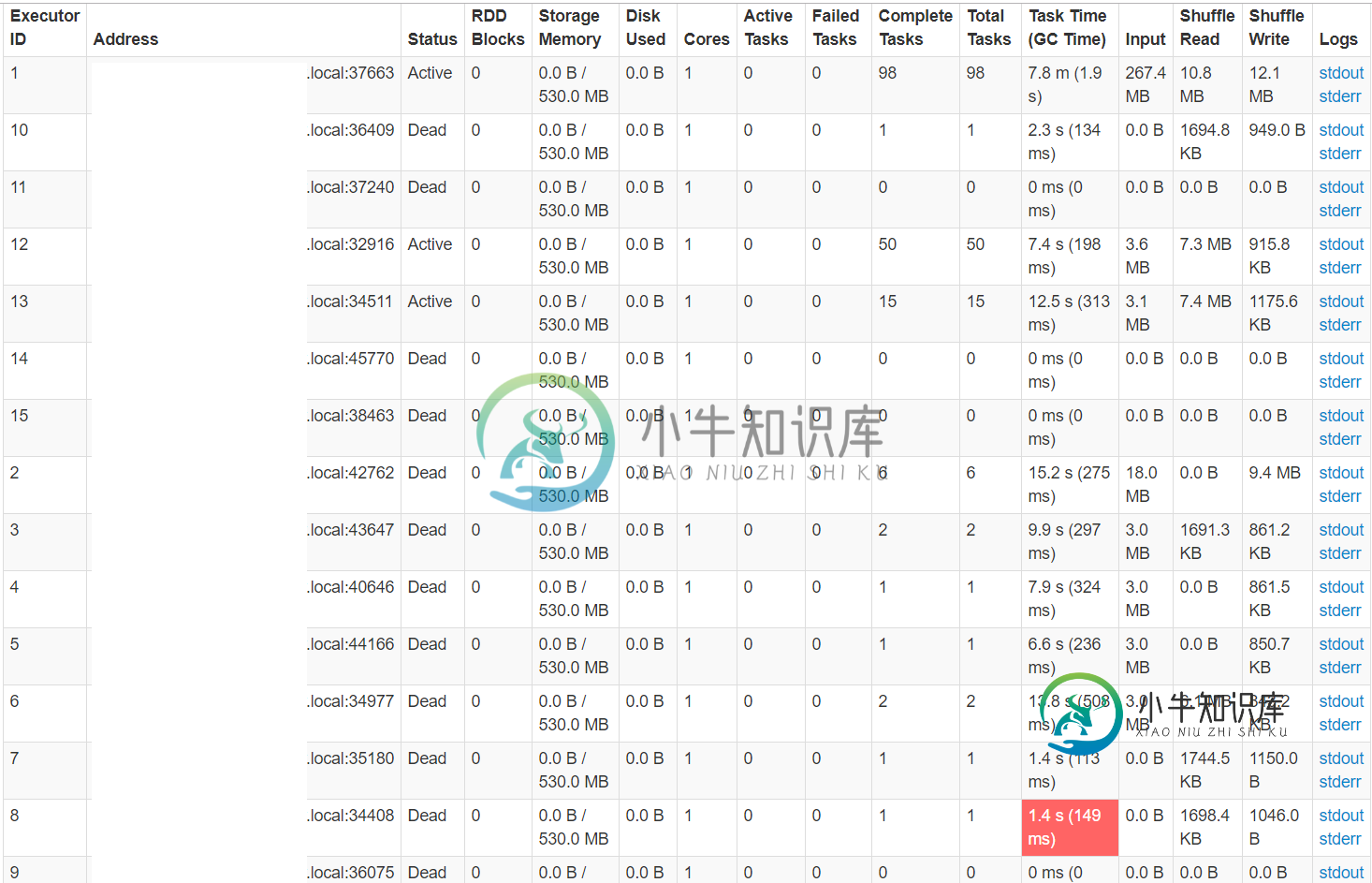
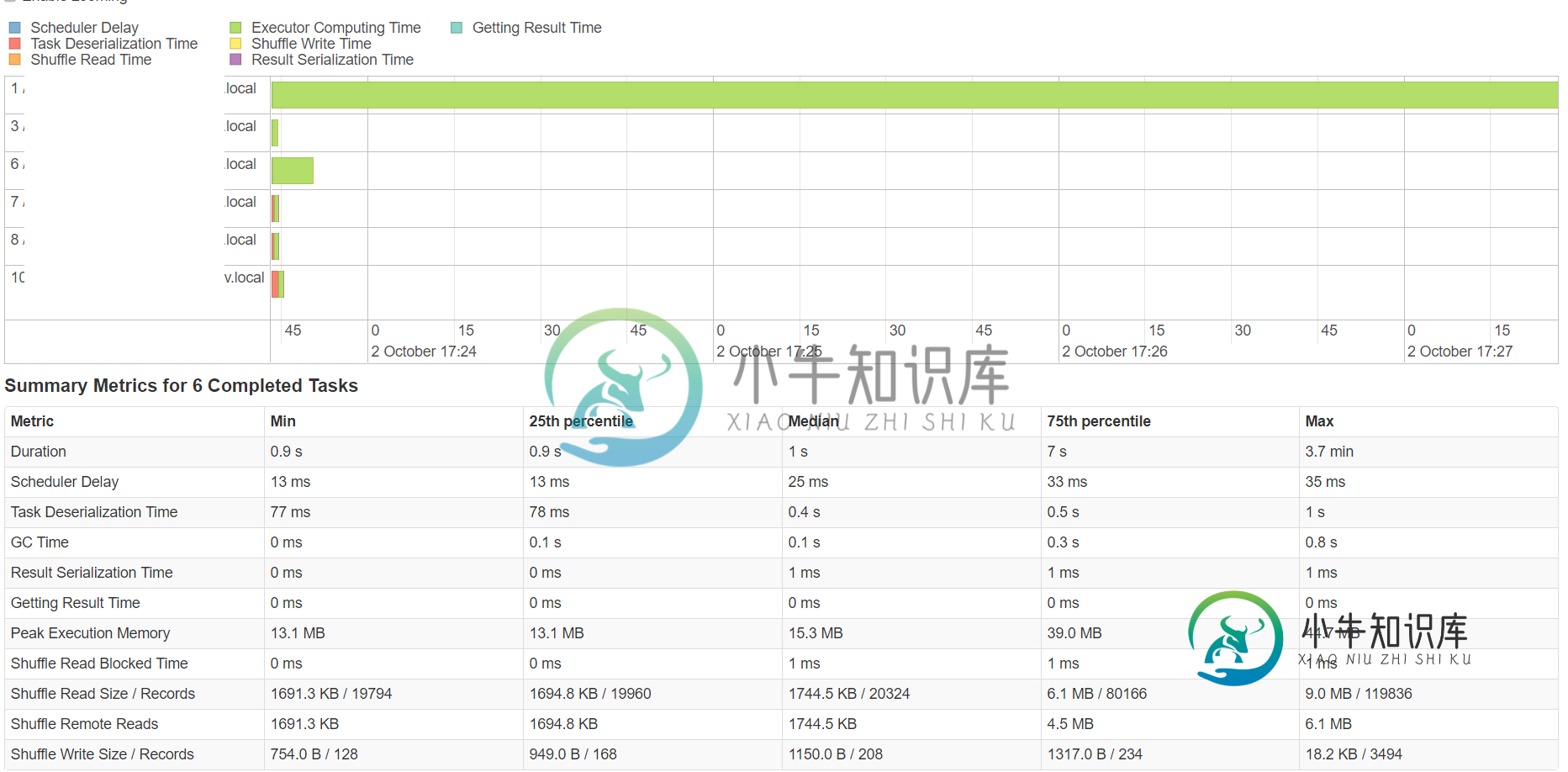
会有什么问题?任何帮助都将不胜感激。
共有1个答案

如果没有看到您的查询和理解您的数据集,这很难判断,我猜您没有包括它也是因为它非常复杂或敏感?所以这是一个有点黑暗的镜头,但这看起来很像我们在工作中处理的问题。我对正在发生的事情的粗略猜测是,在您的一个加入过程中,您有一个键空间,具有高基数,但非常不均匀的分布。在我们的案例中,我们加入了网络流量的来源,虽然我们有成千上万的可能的流量来源,但绝大多数流量来自少数几个来源。这在我们加入时引起了一个问题。密钥将均匀地分布在执行者之间,然而,由于可能95%的数据共享可能是3或4个密钥,所以很少一部分执行者在做大部分工作。当您发现一个连接受到这种影响时,要做的事情是选择两个数据集中较小的一个,并显式地执行广播连接。(Spark通常会尝试这样做,但它并不总是完美地判断何时应该这样做。)
为此,假设您有两个数据副本。其中一个有两列,number和stringrep,其中number对于0-10000中的所有整数来说只是一行,而stringrep只是它的字符串表示形式,所以“One”、“two”、“three”等等。我们将此numtostring称为numtostring
另一个DataFrame有一些键列要连接到numtostring中的number名为kind、其他一些不相关的数据和100,000,000行。我们将此DataFrame称为ourdata。假设ourdata中100,000,000行的分布是,90%具有kind==1,5%具有kind==2,其余5%相当均匀地分布在其余99,998个数字中。执行以下代码时:
val numToString: DataFrame = loadNumToString()
val ourData: DataFrame = loadOurCode()
val joined = ourData.join(numToString).where(ourData("kind") === numToString("number"))
...Spark很可能会将%90的数据(具有种类==1)发送到一个执行器,%5的数据(具有种类==2)发送到另一个执行器,而剩下的%5则会在其余的执行器之间涂抹,从而使两个执行器具有巨大的分区,其余的执行器具有非常小的分区。
正如我之前提到的,解决这个问题的方法是显式地执行广播联接。这样做就是获取一个数据流并将其完全分发到每个节点。所以你可以这样做:
val joined = ourData.join(broadcast(numToString)).where(ourData("kind") === numToString("number"))
...它将向每个执行器发送NumtoString。假设ourdata事先被均匀分区,那么数据应该在执行器之间保持均匀分区。这可能不是你的问题,但听起来确实很像我们遇到的问题。希望有帮助!
-
包含负载均衡集群及节点。 云联壹云 平台提供的本地IDC的负载均衡功能需要管理员先部署负载均衡集群和LBAgent转发节点。 云联壹云 支持负载均衡多集群功能,用户可根据需求配置负载均衡集群以及集群下的转发节点LBAgent,部署集群和转发节点后才可以部署负载均衡实例等。 集群为一组LBAgent转发节点的集合,同一时刻集群中只有一个转发节点处于MASTER,用于监控负载监控实例配置的IP地址和端
-
本文向大家介绍Nginx+Tomcat高性能负载均衡集群搭建教程,包括了Nginx+Tomcat高性能负载均衡集群搭建教程的使用技巧和注意事项,需要的朋友参考一下 Nginx是一个高性能的HTTP服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。其占有内存少,并发能力强,在同类型的网页服务器中表现较好。Nginx可以在大多数Unix Linux OS上编译运行,并有Windows移
-
作为开发人员,我们在Azure Service Fabric上编写了微服务,我们可以在Azure中以某种PaaS概念为许多客户运行它们。但我们的一些客户不想在云中运行,因为数据库是内部的,不能从外部获得,甚至不能通过DMZ获得。没关系,我们promise支持它,因为Azure Service Fabric可以作为集群安装在现场。 我建议在一台(或多台)独立的机器上使用负载平衡器,如HA-Proxy
-
本文向大家介绍Nginx+Tomcat搭建高性能负载均衡集群的实现方法,包括了Nginx+Tomcat搭建高性能负载均衡集群的实现方法的使用技巧和注意事项,需要的朋友参考一下 一、 目标实现高性能负载均衡的Tomcat集群: 二、步骤 1、首先下载Nginx,要下载稳定版: 2、然后解压两个Tomcat,分别命名为apache-tomcat-6.0.33-1和apache-tomcat-6.
-
我想在负载均衡器后面设置一个rabbitmq集群,并使用spring AMQP连接到它。问题: > spring客户端是否需要知道RMQ集群中每个节点的地址,或者只知道负载均衡器的地址就足够了。 如果Spring客户端只知道负载均衡器,那么它将如何为集群中的每个节点维护连接/连接工厂。 是否有任何代码示例,说明如何使spring客户端与负载均衡器一起工作。
-
什么平均负载 简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。 所谓可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。 不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断