《性能测试》专题
-
 浅析Mysql Join语法以及性能优化
浅析Mysql Join语法以及性能优化本文向大家介绍浅析Mysql Join语法以及性能优化,包括了浅析Mysql Join语法以及性能优化的使用技巧和注意事项,需要的朋友参考一下 一.Join语法概述 join 用于多表中字段之间的联系,语法如下: table1:左表;table2:右表。 JOIN 按照功能大致分为如下三类: INNER JOIN(内连接,或等值连接):取得两个表中存在连接匹配关系的记录。 LEFT JOIN(左连
-
Akka HTTP客户端和Akka actor性能调优
我们尝试在host-connection-pool下调整池、actor实例和所有其他参数的大小,但没有更好的效果。 欢迎任何建议!
-
调整模型以获得更好的性能
我为回归问题建立了一个模型,即从9个输入变量中预测一个值。该模型的开发是基于Keras库的人工神经网络 在这个使用编译和拟合方法的模型中,我已经预测了输出值。然而,我得到了糟糕的评价分数。我使用RMSE和R2评估了模型 (已归一化的)预测值和标记值之间的RMSE为0.207,(原始形式)预测值和标记值之间的RMSE为215,R2为0.4 如何修改模型以获得更好的结果(低RMSE和高R2)?或者这种
-
相同代码的Python不同性能[重复]
我偶然发现了一些毫无意义的东西。我有这个Python代码,它做2个简单的for循环,只是测量执行时间。然而,我发现从一个函数调用完全相同的代码需要一半的时间。有人能解释一下为什么吗? 这里是输出:
-
Microsoft AZURE blob触发功能间歇性工作
我们遇到了Blob触发函数的问题。该函数是用javascript编写的。我们费了很大的劲才把自动化部署流程落实到位。以下是我们遵循的步骤。 > 使用ARM模板和参数文件在现有资源组中创建函数应用程序 通过<code>Kudu<code>api<code>调用RestMethod-Uri“$apiUrl”-方法Put-InFile“$functionCodeArchivePath”-凭证$crede
-
corda 未能设置 postgreSQL 数据库属性 url
... corda部署节点失败。日志显示: [错误] 2018-10-04T11:16:05,466Z[主] ) ~[?:-无法在目标类 ) ~[?:{} ) ~[?:: null at0_1810(本机方法)~[?: 1.8.HikariCP-2.5.1.jar]at0_181(0_181HikariCP-2.5.1.jar1.8.com.zaxxer.hikari.pool.PoolBase.
-
提高Oracle中跨DBLINK插入CLOB的性能
在尝试将CLOB从一个数据库复制到另一个数据库时,我发现Oracle(11g)的性能很差。我尝试了几件事,但都没能改善这一点。 CLOB用于收集报告数据。这可能是相当大的一个记录到记录的基础上。我在远程数据库(通过WAN)上调用一个过程来构建数据,然后将结果复制回公司总部的数据库进行比较。一般格式为: 为了提高性能,我将远程站点的结果累积到表的远程副本中。在程序运行结束时,我尝试将数据复制回来。此
-
REST框架的性能(Java vs PHP vs其他)
我们需要创建一个RESTful服务。我们想知道选择哪一个现有的框架。我们知道Java和PHP,所以我们主要考虑这两个框架,但其他选择也是可能的。 你们对不同REST框架的性能有经验吗?有什么巨大的差异吗?是否有一些框架非常沉重,如果我们非常关心性能,我们应该避免它们? 您的想法将不胜感激!
-
通过使用公共变量增强性能?
关于Java,我非常习惯于将我的所有变量声明为私有的,并生成公共的getters和setters以符合通用的约定。 不过,我觉得很奇怪:对于除了赋值和返回请求值之外没有其他功能的getters和setters,调用以下方法不会影响性能吗: 而不是: 编译器是否在这里做了一些事情来帮助函数调用不增加额外的周期?如果不是的话,那么在更健壮的应用程序中,这一理论不就是雪球吗? 编辑:: 为了澄清,这个问
-
需要帮助提高Hazelcast查询性能吗
我有大约20万张唱片要储存。我已经实现了Java客户端来从hazelcast地图中搜索记录。我没有在预期时间内得到搜索结果。 一旦我做Hazelcast喜欢或在查询,它需要最少400到500毫秒。 是否可以更改服务器端和客户端配置以提高吞吐量? 我用键值将JavaBean信息存储在Map中。我还在一个字段上创建了索引。还实现了身份序列化机制。 服务器端配置(使用XML文件设置服务器): 客户端代码
-
gRPC cpp同步与异步服务器性能
我理解同步服务器和异步服务器之间的区别,但是我想知道,如果有这两种情况,哪一种更适合异步服务器还是同步服务器? > 同步:写入调用将被阻塞,直到消息准备好从内部完成队列通过线路发送。异步:写入调用立即返回,我们需要等待完成队列。在同步服务器中,如果我们添加队列,该队列基本上为evry写入调用和其他线程填充,并将其耗尽并执行stream.write然后性能将相同? 同步:gRPC内部创建线程池,线程
-
性能问题:Kafka+Storm+三叉戟+不透明
谢谢,
-
性能hibernate @子选择与数据库视图
我有一个基于Java8 Spring Boot 2.3.3的应用程序(使用Hibernate5.4.20),我有一个Postgreql。我想最终了解使用数据库视图和@Sub选择是否更好(对于性能)。 简单概述一下:我有一个实体“Book”和3个实体“BookRank”(用户给书打1到10颗星)、“BookComment”(用户对书的评论)、“BookLike”(用户把书的评论放在一起),每个实体都
-
ArrayList和LinkedList之间的性能差异[重复]
是的,这是一个老话题,但我仍然有一些困惑。 在Java,人们说: > 如果我随机访问它的元素,ArrayList比LinkedList快。我认为随机存取意味着“给我第n个元素”。为什么ArrayList更快? LinkedList的删除速度比ArrayList快。我理解这一点。ArrayList速度较慢,因为需要重新分配内部备份阵列。代码说明: LinkedList的插入速度比ArrayList快
-
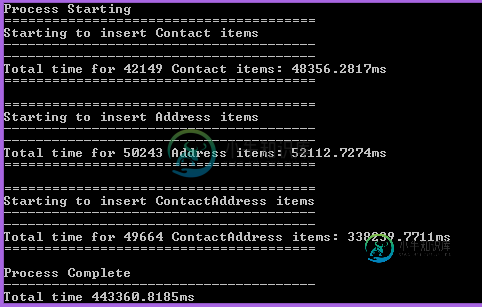 Neo4j 2.0合并唯一约束性能缺陷?
Neo4j 2.0合并唯一约束性能缺陷?情况是这样的:我有一个节点,它有一个属性ConrectId,它被设置为唯一和索引。节点标签为:联系人(节点:联系人{ConrectId: 1}) 我有另一个类似于地址模式的节点:(node2:地址{地址: 1}) 我现在尝试添加一个新节点,该节点(在其他属性中,包括ContactId(用于引用))(节点3:ContactAddress{AddressId:1,ContactId:1}) 当我为每个