《性能测试》专题
-
“等待退货”是否存在性能问题?
我看到有一条eslint规则,,用于禁止。 在规则的描述中,它声明一个添加。 但是,当我查看MDN函数文档时,“简单示例”显示了一个包含的示例,但没有说明这可能是性能问题的原因。 是否如eslint文档所建议的那样是一个实际的性能问题? 如果是,怎么做?
-
未能序列化“org”。springframework。http。HazelcastCache响应性
我正在使用Hazelcast进行缓存, 我的控制器如下所示: 公共响应实体查找(字符串用户){ ..... 返回响应ntity.ok(新的响应Dto(list, null)); } 当Hazelcast尝试在缓存中保存时:异常:未能序列化“org”。springframework。http。响应性 ResponseEntity不可序列化 有什么想法吗?提前谢谢。
-
Neo4j社交图在大响应上的性能
我需要一个关于改进社交图性能的建议。目标查询工作正常,结果数很小。但它可能返回1000多行的大型结果 能否在cypher查询的大响应上调整性能 使用密码查询: Neo4j core 1.9.5 该图包含连接的朋友: 朋友可以有多个数据项,这些数据项表示为具有属性的节点: 数据节点大约有8个属性。其中有一个类别属性。数据项节点按类别编制索引。 好友节点数:650,772 朋友关系号码:842755
-
heroku上的简单rails应用程序性能
我有一个非常简单的Rails3.2.6应用程序。我多年来一直使用Heroku来托管原型,总是在免费层上。我终于在我最新的应用程序上添加了一个付费的dyno,并添加了新的Relic来监控性能。 我在极其简单的页面上看到4500+ms的请求时间,几乎零流量(我们还没有推出)。New Relic表示,99%的时间都花在了渲染模板上。这是一个75行完全静态的haml模板内的100行布局。应用程序模板具有标
-
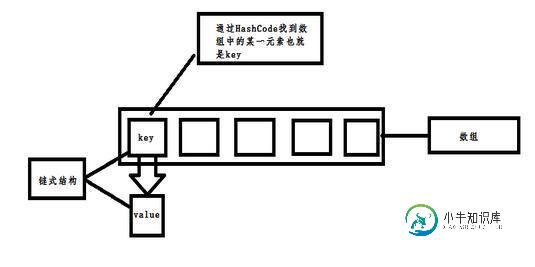 Android中SparseArray性能优化的使用方法
Android中SparseArray性能优化的使用方法本文向大家介绍Android中SparseArray性能优化的使用方法,包括了Android中SparseArray性能优化的使用方法的使用技巧和注意事项,需要的朋友参考一下 之前一篇文章研究完横向二级菜单,发现其中使用了SparseArray去替换HashMap的使用.于是乎自己查了一些相关资料,自己同时对性能进行了一些测试。首先先说一下SparseArray的原理. SparseArray
-
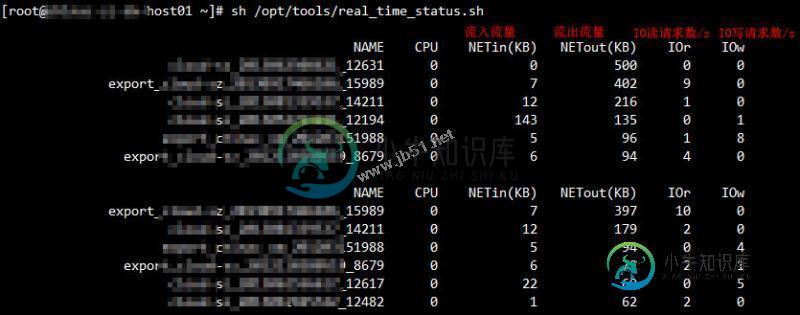 xenserver虚拟机实时性能查看方法
xenserver虚拟机实时性能查看方法本文向大家介绍xenserver虚拟机实时性能查看方法,包括了xenserver虚拟机实时性能查看方法的使用技巧和注意事项,需要的朋友参考一下 登陆服务器,执行脚本/opt/tools/real_time_status.sh:(该脚本的相关数据都是从xentop命令中提取的) [root@xen-host01 ~]# sh /opt/tools/real_time_status.sh 默认以流出流
-
JEE与Spring Boot代码性能比较分析
本文向大家介绍JEE与Spring Boot代码性能比较分析,包括了JEE与Spring Boot代码性能比较分析的使用技巧和注意事项,需要的朋友参考一下 JavaEE与Spring Boot其实很难比较测试,前者适合单体SOA架构,后者适合微服务,但是还是有好事者把两者放在一起比较性能。 我把一些JEE和Spring代码放在一起做了同样的事情。Spring做了一些开箱即用的好东西,所以我在一些J
-
提升Python程序性能的7个习惯
本文向大家介绍提升Python程序性能的7个习惯,包括了提升Python程序性能的7个习惯的使用技巧和注意事项,需要的朋友参考一下 掌握一些技巧,可尽量提高Python程序性能,也可以避免不必要的资源浪费。 1、使用局部变量 尽量使用局部变量代替全局变量:便于维护,提高性能并节省内存。 使用局部变量替换模块名字空间中的变量,例如 ls = os.linesep。一方面可以提高程序性能,局部变量查找
-
静态空数组实例的性能优势
问题内容: 将常量的空数组返回值提取为静态常量似乎是常见的做法。像这儿: 大概这样做是出于性能方面的考虑,因为直接返回会在每次调用该方法时创建一个新的数组对象-真的吗? 我一直在想,这样做是否真的有可衡量的性能优势,或者只是过时的民间智慧。空数组是不可变的。VM是否无法将所有空数组都合并为一个?VM不能基本免费赚钱吗? 将这种做法与返回空字符串进行对比:通常,我们非常乐于编写,而不是。 问题答案:
-
react性能优化是哪个周期函数?
本文向大家介绍 react性能优化是哪个周期函数?相关面试题,主要包含被问及 react性能优化是哪个周期函数?时的应答技巧和注意事项,需要的朋友参考一下 shouldComponentUpdate这个方法用来判断是否需要调用render方法重新描绘dom。因为dom的描绘非常消耗性能,如果我们能在shouldComponentUpdate方法中能够写出更优化的dom diff算法,可以极大的提高
-
改善Python中超大型字典的性能
问题内容: 我发现如果在开始时初始化一个空字典,然后在for循环中向字典中添加元素(大约110,000个键,每个键的值是一个列表,并且在循环中也在增加),则速度会降低循环。 我怀疑问题在于,字典在初始化时不知道键的数量,并且执行的操作也不是很聪明,因此存储冲突可能会变得很频繁并且会减慢速度。 如果我知道键的数量以及这些键的确切含义,python中有什么方法可以使字典(或哈希表)更有效地工作?我隐约
-
SQL中的LIKE解决方法(性能问题)
问题内容: 我一直在阅读,发现使用LIKE会导致查询速度大大降低。 同事推荐我们使用 替代 现在我不是SQL专家,并且我不太了解这些语句的内部工作原理。这是一个更好的选择,值得在每个like语句中键入一些额外的字符吗?是否有更好(更容易键入)的替代方法? 问题答案: 有几个性能问题需要解决… 如果可能,不要多次访问同一张表 不要将子查询用于无需参考同一表的其他副本即可完成的条件。如果由于使用聚合函
-
浅谈优化Django ORM中的性能问题
本文向大家介绍浅谈优化Django ORM中的性能问题,包括了浅谈优化Django ORM中的性能问题的使用技巧和注意事项,需要的朋友参考一下 Django是个好工具,使用的很广泛。 在应用比较小的时候,会觉得它很快,但是随着应用复杂和壮大,就显得没那么高效了。当你了解所用的Web框架一些内部机制之后,才能写成比较高效的代码。 怎么查问题 Web系统是个挺复杂的玩意,有时候有点无从下手哈。可以采用
-
 IntelliJ IDEA 2020.3 重大特性(新功能一览)
IntelliJ IDEA 2020.3 重大特性(新功能一览)本文向大家介绍IntelliJ IDEA 2020.3 重大特性(新功能一览),包括了IntelliJ IDEA 2020.3 重大特性(新功能一览)的使用技巧和注意事项,需要的朋友参考一下 今天发现 idea 2020.3 版本发布了 ,那么废话不多说,赶紧更新起来; IntelliJ IDEA:https://www.jetbrains.com/idea ps:继续推荐使用 toolbox 进
-
 Android高级开发之性能优化典范
Android高级开发之性能优化典范本文向大家介绍Android高级开发之性能优化典范,包括了Android高级开发之性能优化典范的使用技巧和注意事项,需要的朋友参考一下 本章介绍android高级开发中,对于性能方面的处理。主要包括电量,视图,内存三个性能方面的知识点。 1.视图性能 (1)Overdraw简介 Overdraw就是过度绘制,是指在一帧的时间内(16.67ms)像素被绘制了多次,理论上一个像素每次只绘制一次