
Android中SparseArray性能优化的使用方法

之前一篇文章研究完横向二级菜单,发现其中使用了SparseArray去替换HashMap的使用.于是乎自己查了一些相关资料,自己同时对性能进行了一些测试。首先先说一下SparseArray的原理.
SparseArray(稀疏数组).他是Android内部特有的api,标准的jdk是没有这个类的.在Android内部用来替代HashMap<Integer,E>这种形式,使用SparseArray更加节省内存空间的使用,SparseArray也是以key和value对数据进行保存的.使用的时候只需要指定value的类型即可.并且key不需要封装成对象类型.
楼主根据亲测,SparseArray存储数据占用的内存空间确实比HashMap要小一些.一会放出测试的数据在进行分析。我们首先看一下二者的结构特性.
HashMap是数组和链表的结合体,被称为链表散列.
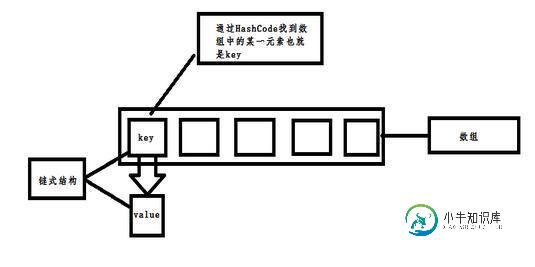
SparseArray是单纯数组的结合.被称为稀疏数组,对数据保存的时候,不会有额外的开销.结构如下:

这就是二者的结构,我们需要看一下二者到底有什么差异...
首先是插入:
HashMap的正序插入:
HashMap<Integer, String>map = new HashMap<Integer, String>();
long start_map = System.currentTimeMillis();
for(int i=0;i<MAX;i++){
map.put(i, String.valueOf(i));
}
long map_memory = Runtime.getRuntime().totalMemory();
long end_map = System.currentTimeMillis()-start_map;
System.out.println("<---Map的插入时间--->"+end_map+"<---Map占用的内存--->"+map_memory);
执行后的结果:
<---Map的插入时间--->914 <---Map占用的内存--->28598272
SparseArray的正序插入:
SparseArray<String>sparse = new SparseArray<String>();
long start_sparse = System.currentTimeMillis();
for(int i=0;i<MAX;i++){
sparse.put(i, String.valueOf(i));
}
long sparse_memory = Runtime.getRuntime().totalMemory();
long end_sparse = System.currentTimeMillis()-start_sparse;
System.out.println("<---Sparse的插入时间--->"+end_sparse+"<---Sparse占用的内存--->"+sparse_memory);
//执行后的结果:
<---Sparse的插入时间--->611
<---Sparse占用的内存--->23281664
我们可以看到100000条数据量正序插入时SparseArray的效率要比HashMap的效率要高.并且占用的内存也比HashMap要小一些..这里的正序插入表示的是i的值是从小到大进行的一个递增..序列取决于i的值,而不是for循环内部如何执行...
通过运行后的结果我们可以发现,SparseArray在正序插入的时候,效率要比HashMap要快得多,并且还节省了一部分内存。网上有很多的说法关于二者的效率问题,很多人都会误认为SparseArray要比HashMap的插入和查找的效率要快,还有人则是认为Hash查找当然要比SparseArray中的二分查找要快得多.
其实我认为Android中在保存<Integer,Value>的时候推荐使用SparseArray的本质目的不是由于效率的原因,而是内存的原因.我们确实看到了插入的时候SparseArray要比HashMap要快.但是这仅仅是正序插入.我们来看看倒序插入的情况.
HashMap倒序插入:
System.out.println("<------------- 数据量100000 散列程度小 Map 倒序插入--------------->");
HashMap<Integer, String>map_2 = new HashMap<Integer, String>();
long start_map_2 = System.currentTimeMillis();
for(int i=MAX-1;i>=0;i--){
map_2.put(MAX-i-1, String.valueOf(MAX-i-1));
}
long map_memory_2 = Runtime.getRuntime().totalMemory();
long end_map_2 = System.currentTimeMillis()-start_map_2;
System.out.println("<---Map的插入时间--->"+end_map_2+"<---Map占用的内存--->"+map_memory_2);
//执行后的结果:
<------------- 数据量100000 Map 倒序插入--------------->
<---Map的插入时间--->836<---Map占用的内存--->28598272
SparseArray倒序插入:
System.out.println("<------------- 数据量100000 散列程度小 SparseArray 倒序插入--------------->");
SparseArray<String>sparse_2 = new SparseArray<String>();
long start_sparse_2 = System.currentTimeMillis();
for(int i=MAX-1;i>=0;i--){
sparse_2.put(i, String.valueOf(MAX-i-1));
}
long sparse_memory_2 = Runtime.getRuntime().totalMemory();
long end_sparse_2 = System.currentTimeMillis()-start_sparse_2;
System.out.println("<---Sparse的插入时间--->"+end_sparse_2+"<---Sparse占用的内存--->"+sparse_memory_2);
//执行后的结果
<------------- 数据量100000 SparseArray 倒序插入--------------->
<---Sparse的插入时间--->20222<---Sparse占用的内存--->23281664
通过上面的运行结果,我们仍然可以看到,SparseArray与HashMap无论是怎样进行插入,数据量相同时,前者都要比后者要省下一部分内存,但是效率呢?我们可以看到,在倒序插入的时候,SparseArray的插入时间和HashMap的插入时间远远不是一个数量级.由于SparseArray每次在插入的时候都要使用二分查找判断是否有相同的值被插入.因此这种倒序的情况是SparseArray效率最差的时候.
SparseArray的插入源码我们简单的看一下..
public void put(int key, E value) { int i = ContainerHelpers.binarySearch(mKeys, mSize, key); //二分查找. if (i >= 0) { //如果当前这个i在数组中存在,那么表示插入了相同的key值,只需要将value的值进行覆盖.. mValues[i] = value; } else { //如果数组内部不存在的话,那么返回的数值必然是负数. i = ~i; //因此需要取i的相反数. //i值小于mSize表示在这之前. mKey和mValue数组已经被申请了空间.只是键值被删除了.那么当再次保存新的值的时候.不需要额外的开辟新的内存空间.直接对数组进行赋值即可. if (i < mSize && mValues[i] == DELETED) { mKeys[i] = key; mValues[i] = value; return; } //当需要的空间要超出,但是mKey中存在无用的数值,那么需要调用gc()函数. if (mGarbage && mSize >= mKeys.length) { gc(); // Search again because indices may have changed. i = ~ContainerHelpers.binarySearch(mKeys, mSize, key); } //如果需要的空间大于了原来申请的控件,那么需要为key和value数组开辟新的空间. if (mSize >= mKeys.length) { int n = ArrayUtils.idealIntArraySize(mSize + 1); //定义了一个新的key和value数组.需要大于mSize int[] nkeys = new int[n]; Object[] nvalues = new Object[n]; // Log.e("SparseArray", "grow " + mKeys.length + " to " + n); //对数组进行赋值也就是copy操作.将原来的mKey数组和mValue数组的值赋给新开辟的空间的数组.目的是为了添加新的键值对. System.arraycopy(mKeys, 0, nkeys, 0, mKeys.length); System.arraycopy(mValues, 0, nvalues, 0, mValues.length); //将数组赋值..这里只是将数组的大小进行扩大..放入键值对的操作不在这里完成. mKeys = nkeys; mValues = nvalues; } //如果i的值没有超过mSize的值.只需要扩大mKey的长度即可. if (mSize - i != 0) { // Log.e("SparseArray", "move " + (mSize - i)); System.arraycopy(mKeys, i, mKeys, i + 1, mSize - i); System.arraycopy(mValues, i, mValues, i + 1, mSize - i); } //这里是用来完成放入操作的过程. mKeys[i] = key; mValues[i] = value; mSize++; } }
这就是SparseArray插入函数的源码.每次的插入方式都需要调用二分查找.因此这样在倒序插入的时候会导致情况非常的糟糕,效率上绝对输给了HashMap学过数据结构的大家都知道.Map在插入的时候会对冲突因子做出相应的决策.有非常好的处理冲突的方式.不需要遍历每一个值.因此无论是倒序还是正序插入的效率取决于处理冲突的方式,因此插入时牺牲的时间基本是相同的.
通过插入.我们还是可以看出二者的差异的.
我们再来看一下查找首先是HashMap的查找.
System.out.println("<------------- 数据量100000 Map查找--------------->");
HashMap<Integer, String>map = new HashMap<Integer, String>();
for(int i=0;i<MAX;i++){
map.put(i, String.valueOf(i));
}
long start_time =System.currentTimeMillis();
for(int i=0;i<MAX;i+=100){
map.get(i);
}
long end_time =System.currentTimeMillis()-start_time;
System.out.println(end_time);
//执行后的结果
<!---------查找的时间:175------------>
SparseArray的查找:
System.out.println("<------------- 数据量100000 SparseArray 查找--------------->");
SparseArray<String>sparse = new SparseArray<String>();
for(int i=0;i<10000;i++){
sparse.put(i, String.valueOf(i));
}
long start_time =System.currentTimeMillis();
for(int i=0;i<MAX;i+=10){
sparse.get(i);
}
long end_time =System.currentTimeMillis()-start_time;
System.out.println(end_time);
//执行后的结果
<!-----------查找的时间:239---------------->
我这里也简单的对查找的效率进行了测试.对一个数据或者是几个数据的查询.二者的差异还是非常小的.当数据量是100000条.查100000条的效率还是Map要快一点.数据量为10000的时候.这就差异性就更小.但是Map的查找的效率确实还是赢了一筹.
其实在我看来.在保存<Integer,E>时使用SparseArray去替换HashMap的主要原因还是因为内存的关系.我们可以看到.保存的数据量无论是大还是小,Map所占用的内存始终是大于SparseArray的.数据量100000条时SparseArray要比HashMap要节约27%的内存.也就是以牺牲效率的代价去节约内存空间.我们知道Android对内存的使用是极为苛刻的.堆区允许使用的最大内存仅仅16M.很容易出现OOM现象的发生.因此在Android中内存的使用是非常的重要的.因此官方才推荐去使用SparseArray<E>去替换HashMap<Integer,E>.官方也确实声明这种差异性不会超过50%.所以牺牲了部分效率换来内存其实在Android中也算是一种很好的选择吧.
-
本文向大家介绍angularjs性能优化的方法,包括了angularjs性能优化的方法的使用技巧和注意事项,需要的朋友参考一下 学习angularjs有一段时间了,但是一直都没有怎么考虑过性能方面的问题,上次在研究过滤器的时候涉及到了性能问题。所以自己也总结了下常用的性能优化。 优化$watch 1.及时移除不必要的watch 2.尽量避免深度watch 我们都知道$watch有三个参数,第三个参
-
Android 应用性能优化系列 原文链接分别为 : https://www.youtube.com/playlist?list=PLWz5rJ2EKKc9CBxr3BVjPTPoDPLdPIFCE https://www.udacity.com/course/ud825 译者 : 胡凯 Android性能优化典范 Android性能优化之渲染篇 Android性能优化之运算篇 Android性能
-
ANR ANR全称Application Not Responding,意思就是程序未响应。 出现场景 主线程被IO操作(从4.0之后网络IO不允许在主线程中)阻塞。 主线程中存在耗时的计算 主线程中错误的操作,比如Thread.wait或者Thread.sleep等 Android系统会监控程序的响应状况,一旦出现下面两种情况,则弹出ANR对话框 应用在5秒内未响应用户的输入事件(如按键或者触摸
-
本文向大家介绍react性能优化方案相关面试题,主要包含被问及react性能优化方案时的应答技巧和注意事项,需要的朋友参考一下 重写shouldComponentUpdate来避免不必要的dom操作0 使用 production 版本的react.js0 使用key来帮助React识别列表中所有子组件的最小变化。 参考链接: https://segmentfault.com/a/119000000
-
一、Android性能优化的方面 针对Android的性能优化,主要有以下几个有效的优化方法: 1.布局优化 2.绘制优化 3.内存泄漏优化 4.响应速度优化 5.ListView/RecycleView及Bitmap优化 6.线程优化 7.其他性能优化的建议 下面我们具体来介绍关于以上这几个方面优化的具体思路及解决方案。 二、布局优化 关于布局优化的思想很简单,就是尽量减少布局文件的层级。这个道
-
本文向大家介绍react性能优化达到最大化的方法 immutable.js使用的必要性,包括了react性能优化达到最大化的方法 immutable.js使用的必要性的使用技巧和注意事项,需要的朋友参考一下 一行代码胜过千言万语。这篇文章呢,主要讲述我一步一步优化react性能的过程,为什么要用immutable.js呢。毫不夸张的说。有了immutable.js(当然也有其他实现库)。。才能将r