《性能测试》专题
-
SQL INSERT性能忽略字段名称吗?
问题内容: 有谁知道从INSERT查询中删除字段名称是否会带来一些性能改进? 我的意思是这样的: 比完成此任务更快地完成数据库: ? 我知道这可能是毫无意义的性能差异,但只是要知道。 我通常使用MySQL和PostgreSQL作为数据库。 问题答案: 不,实际上相反! 至少对于Microsoft SQL Server-您没有指定要使用的数据库..... 如果您未在SELECT或INSERT中指定字
-
异步servlet处理如何提高性能
我从http://docs.oracle.com/javaee/7/tutorial/doc/servlets012.htm Java EE为servlet和过滤器提供异步处理支持。如果servlet或过滤器在处理请求时达到潜在的阻塞操作,它可以将该操作分配给异步执行上下文,并将与请求相关联的线程立即返回到容器,而不生成响应。阻塞操作在不同线程的异步执行上下文中完成,该线程可以生成响应或将请求分派
-
SQL Server十进制数据类型性能
我有几个表存储了相当大的数字,因此我选择作为所有列的数据类型。 架构示例: Table1(value1,value2,value3,value4,value5) Table2(value1,value2,value3,value4,value5)
-
为什么JIT订单会影响性能?
为什么。NET 4.0中C#方法的及时编译顺序会影响它们的执行速度?例如,考虑两种等效的方法: 唯一的区别是引入了局部变量,这会影响生成的汇编代码和循环性能。为什么会这样,这本身就是一个问题。 可能更奇怪的是,在x86(而不是x64)上,调用方法的顺序对性能有大约20%的影响。调用如下方法。。。 ...单线测试速度更快。(使用x86版本配置编译,确保启用了“优化代码”设置,并从VS2010外部运行
-
代码对齐会显着影响性能
今天,我发现在添加了一些不相关的代码后,示例代码的速度降低了50%。调试后,我发现问题出在循环对齐中。根据循环代码的位置,有不同的执行时间,例如: 我以前没想到代码对齐会产生如此大的影响。我认为我的编译器足够聪明,可以正确对齐代码。 到底是什么导致了执行时间的如此大的差异?(我想是一些处理器架构细节)。 我用Visual Studio 2019在发布模式下编译的测试程序,并在Windows 10上
-
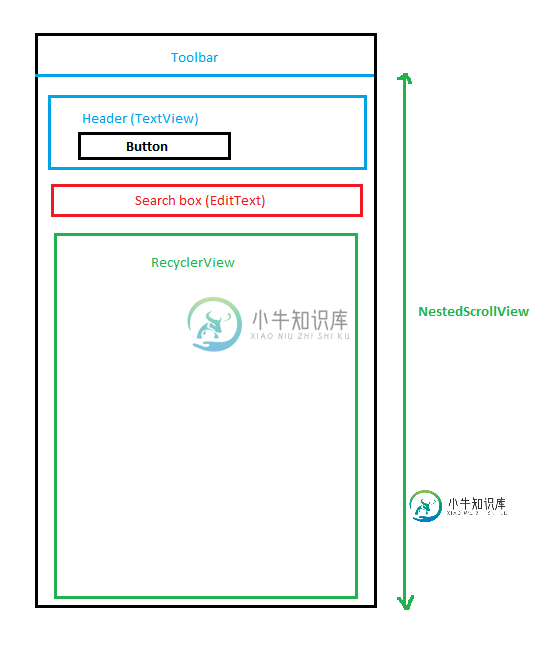 在NestedScrollView中使用RecycerView时性能不良
在NestedScrollView中使用RecycerView时性能不良在Androidmanifest中:
-
生成liquibase的可能性:diff和回滚
Liquibase在Java世界中类似于EntityFramework(EF)。并且=在中。但问题是只生成,但没有回滚。有可能在回滚的同时生成差异吗? 我试着用liquibase:rollback创建回滚脚本。但它并不能在所有情况下都生成回滚脚本,例如,当我删除了一个带有更改集的列,然后想要回滚时。设置或运行时出错
-
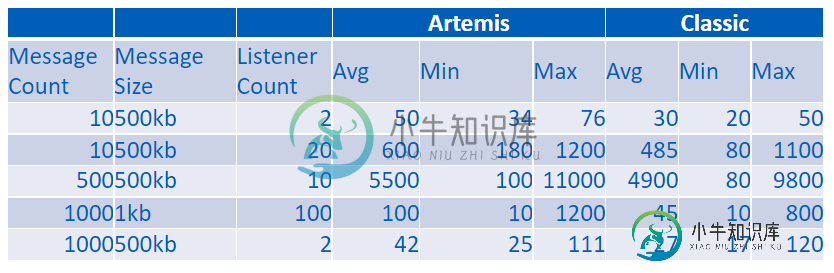 与“经典”相比,ActiveMQ Artemis性能下降
与“经典”相比,ActiveMQ Artemis性能下降我正在进行从ActiveMQ“Classic”5.15.4到ActiveMQ Artemis 2.17.0的迁移,发现性能下降。我和一个制作人就一个主题进行了测试,并有不同数量的消费者使用该主题。我在测量信息创建和消费者接收之间的时间。 测试在一个由3个节点组成的集群上进行,所有节点都相互连接。每个代理都嵌入到一个JBoss中。我使用了一个由3个节点组成的集群,因为这是我们当前的生产设置。我挑战这
-
Apache点燃:StripedExecutor队列和备份性能
我们有一个包含2个数据节点和分布式缓存的cluste(IgniteV2.7)。 我们将数据加载到这个缓存中,并开始海量读/写操作。集群工作得很好。根据JMX,StripedExecutor队列为空。 数据区域配置: 缓存配置:
-
角度单向绑定不影响性能
我正在从事一个项目,该项目在很大程度上依赖angular来完成前端任务。在一个显示了大约50个带有ng repeat的条目的列表页面上,每个条目都有大量的观察者,因此我决定使用angular的静态绑定减少观察者的数量,并能够将数量从12k观察者减少到8k观察者,但即使在观察者数量大幅减少之后,加载时间、dom呈现或摘要周期时间也没有改善。digest cyle使用8k观察程序所需的时间与使用12k
-
Java BigInteger源代码性能基准[重复]
我试图弄清楚为什么Java的BigInteger乘法基准比使用从BigInteger.java源代码复制到我的项目中的实例要快3倍。使用jmh运行基准测试。下面是一个示例输出,注意加法的运行大致相同。
-
突出显示时Solr性能非常慢
我配置了一个Solr 4.4.0内核,其中包含约630k文档,原始大小约为10 GB。为了查询和高亮显示,每个字段都会复制到文本字段中。当我在没有突出显示的情况下执行搜索时,结果会在大约100毫秒后返回,但当打开突出显示时,相同的查询需要10-11秒。我还注意到,对相同术语的后续查询持续大约10-11秒。 我对该字段的初始配置如下 发送的查询类似于以下内容 我所有的研究似乎都没有提供线索来解释为什
-
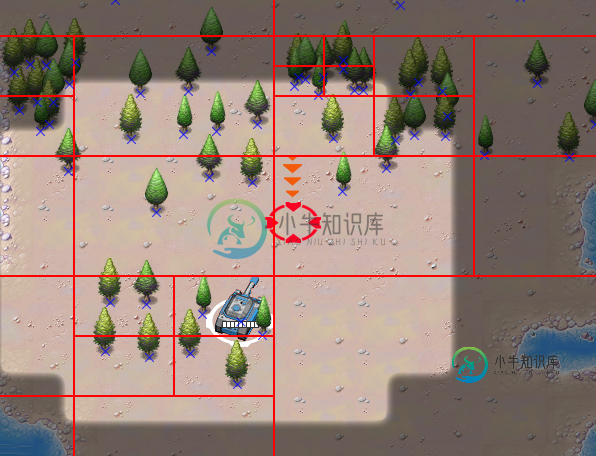 四叉树性能:正方形与矩形?
四叉树性能:正方形与矩形?对于我正在编写的游戏,我在非正方形地图上使用四叉树。四叉树用于查找给定最大半径(圆)内的相邻单位的冲突检测、要攻击的敌人、最近的基地等。 我想知道的是,如果将四边形树由矩形而不是正方形制成,是否存在性能问题?矩形地图不是将正方形地图划分为正方形,而是在四边形树中划分为大小相等的矩形。 矩形地图上的方形四叉树:将创建一个四叉树,填充整个地图,但左侧或底部有空白/未使用区域,具体取决于地图的方向(水平
-
喷气背包撰写懒惰列性能
我是jetpack compose的新手,从< code>JetpackCompose基础代码中学习它,所以我在创建一个高性能的懒惰列表中找到了它 注意:LazyColumn不会像那样回收其子项。当您滚动浏览它时,它会发出新的,并且仍然具有高性能,因为与实例化Android视图相比,发出相对便宜。 因此,发出新的可组合项是多么的便宜和高效,那么为什么不使用列并一次性组合整个列表,而不是在滚动时不断
-
Lucene中多值字段的性能问题
我们使用Lucene4.7构建和查询一个相当大的数据集(1亿1千万以上的文档)。 详情: 硬件:Xen VM,8核至强CPU E5-2670 v2,2.5GHz,64 GB RAM 操作系统:Windows Server 2012标准 JVM:以-xmx8000m开始(Lucene使用了其中的45%) Lucene查询是单线程的