《性能测试》专题
-
骆驼SFTP文件传输,提高性能
通过打开到同一主机的多个连接(例如、),是否有任何方法可以提高文件传输性能?
-
快速性能:map()和reduce()vs for循环
我正在用Swift编写一些性能关键的代码。在实现了我能想到的所有优化,并在仪器中分析了应用程序之后,我意识到绝大多数CPU周期都花在了对浮点数组执行和操作上。因此,为了看看会发生什么,我用良好的老式循环替换了和的所有实例。令我吃惊的是...循环要快得多! 的平均执行时间:20.1秒。循环的平均执行时间:11.2秒。使用整数而不是浮点的结果是相似的。 我创建了一个类似的基准测试Swift的的性能。这
-
优化。NET POCOs的JSON序列化性能
我一直试图优化要导入到MongoDB中的超过500k个POCO的JSON序列化,但除了头痛之外什么也没有遇到。我最初尝试了Newtonsoft json.convert()函数,但这花费了太长时间。然后,根据SO、NewtonSoft自己的站点和其他位置上的几篇文章的建议,我尝试手动序列化这些对象。但没有注意到太多,如果有任何业绩增益。 这是我用来启动序列化过程的代码...在每行上面的注释中,是给
-
Clojure性能,大向量上的大循环
我正在对大小为50,000个元素的两个向量执行基于元素的操作,并且有不满意的性能问题(几秒钟)。是否存在明显的性能问题,例如使用不同的数据结构?
-
类级url注释对性能的影响
我对Spring请求映射的内部工作很好奇。在类级别使用requestmapping注释是否会加快解析请求的控制器? 在Spring Boot中@RequestMapping如何在内部工作?-阅读这个答案和类似的答案。控制器和URL是否在初始启动期间映射并存储在注册表中?因为我在启动Spring Boot应用程序时发现了这些日志跟踪。 控制器+方法和URL是最初在启动期间映射的,还是每次为请求迭代?
-
JavaScript性能优化之V8引擎简介
前言 本篇文章主要是介绍V8引擎,V8引擎主要有以下3个特点 1.V8引擎是市面上最流行的JavaScript引擎,目前Chrome浏览器和node.js平台也是采用V8引擎执行JavaScript代码 2. V8采用即时编译,之前其他的JavaScript引擎都是将源代码转换成字节码,再转换成机器码,然后才能执行 而V8引擎,直接将源代码转换成机器码直接执行,这样的话效率会高很多
-
用RXCollections进行函数式编程 - 性能
这一章有关函数式编程的事例代码可能会让你开始担心性能的问题。例如,在一个长数组中,给每个元素创建一个过渡的字符描述并把他们追加到前面的结果中去,比起命令式编程来说,可能需要消耗更长的时间。 这可能是个问题,但幸运的是,现在的计算机(甚至iPhone手机)性能已经足够强大,在大多数情况下,这种性能损耗是无关紧要的,况且当这种损耗变成一个性能瓶颈的时候,你随时都可以回头去优化她让她更加高效。CPU的时
-
在 DB2 中提高 Insert 性能的技巧
首先让我们快速地看看 insert 一行时的处理步骤。这些步骤中的每一步都有优化的潜力,对此我们在后面会一一讨论。 1、在客户机准备语句。对于动态 SQL,在语句执行前就要做这一步,此处的性能是很重要的;对于静态 SQL,这一步的性能实际上关系不大,因为语句的准备是事先完成的。 2、在客户机,将要插入的行的各个列值组装起来,发送到 DB2 服务器。 3、DB2 服务器确定将这一行插入到哪一页中。
-
编码 DB2 SQL 以获得最佳性能
当要保证用 IBM DB2 ® Universal Database™(DB2 UDB) 和 Borland® 工具(如 Delphi™、C++Builder™ 或Kylix™)构建的企业应用程序拥有最优性能时,程序员可以利用 DB2 优化器的能力来处理即使是“难以处理的”SQL 语句并给出有效的存取路径。 尽管如此,拙劣编码的 SQL 和应用程序代码仍可能给您带来性能问题,通过学习几条基本准则可
-
 Uragano 高性能 RPC 框架中文文档
Uragano 高性能 RPC 框架中文文档Uragano 旨在提供一个搭建和使用简单的高性能 RPC 框架。Uragano 是基于 netstandard2.0 开发的。Uragano 默认采用 DotNetty 实现远程通信,使用 MessagePack 进行编解码。
-
 大疆车载 高性能 二面 面经
大疆车载 高性能 二面 面经#24届软开秋招面试经验大赏# 投递岗位:高性能计算开发 面试时间:15min 面试流程 视频面试 1、自我介绍 2、简单介绍项目的难点与解决 3、你对自己的职业规划是怎样的? 4、高性能有很多落地,为什么选择车载行业? 5、为什么选择大疆? 6、反问 大大大BOSS面,我感觉主要是考察你的职业规划,来大疆的意愿是否坚定
-
 蔚来 高性能计算 1 2 3面
蔚来 高性能计算 1 2 3面【名称】蔚来高性能计算日常实习 1 2 3面 【时间】23.07 【公司】蔚来 【岗位】高性能计算 【面经】个人 一面: 1. 自我介绍 2. 深挖实习 3. 你用过TensorRT 讲讲对 TensorRT的理解 4. 讲讲TensorRT 和 OpenVINO的区别 C++ 八股: 5. C++面向对象特性 面向对象特性分别如何体现的 6. 讲一下继承 7. 讲一下虚函数 8. 讲一下vect
-
volatile为什么不能保证原子性
主要内容:可见性,原子性,举个例子首先要了解的是,volatile可以保证可见性和顺序性,这些都很好理解,那么它为什么不能保证原子性呢? 可见性 可见性与Java的内存模型有关,模型采用缓存与主存的方式对变量进行操作,也就是说,每个线程都有自己的缓存空间,对变量的操作都是在缓存中进行的,之后再将修改后的值返回到主存中,这就带来了问题,有可能一个线程在将共享变量修改后,还没有来的及将缓存中的变量返回给主存中,另外一个线程就对共享变量
-
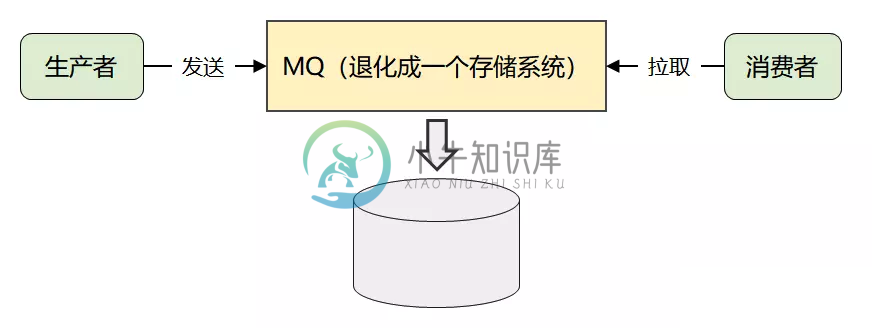 Kafka高性能设计之架构设计
Kafka高性能设计之架构设计主要内容:1.Kafka 的技术难点,2.Kafka 架构设计,3.Kafka的宏观架构设计,4.Kafka 的整体架构1.Kafka 的技术难点 Kafka 为实时日志流而生,要处理的并发和数据量非常大。可见,Kafka 本身就是一个高并发系统,它必然会遇到高并发场景下典型的三高挑战:高性能、高可用和高扩展。 为了简化实现的复杂度,Kafka 最终采用了很巧妙的消息模型:它将所有消息进行了持久化存储,让消费者自己各取所需,想取哪个消息,想什么时候取都行,只需要传递一个消息的 offset 进行
-
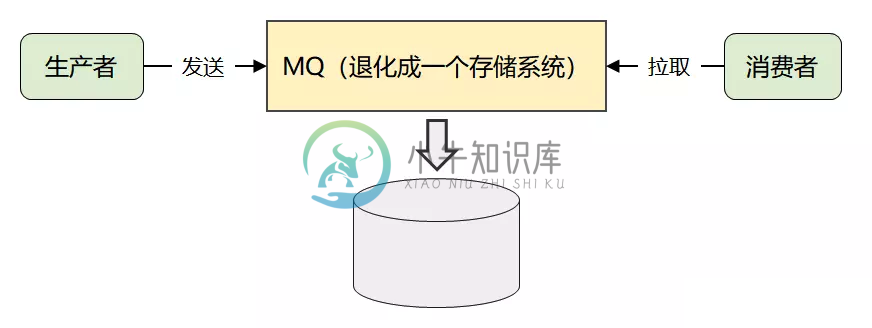 Kafka高性能设计之存储设计
Kafka高性能设计之存储设计主要内容:1.Kafka存储难度,2.Kafka 的存储选型分析,3.Kafka 的存储设计Kafka使用的是Logging(日志文件)这种很原始的方式来存储消息 对于存储设计有一些知识点: Append Only、Linear Scans、磁盘顺序写、页缓存、零拷贝、稀疏索引、二分查找等等。 Append Only Data Structures 的一些存储系统比如HBase, Cassandra, RocksDB 1.Kafka存储难度 Kafka 通过简化消息模型,将自己退化成了一