《性能测试》专题
-
性能缓存事件是什么意思?
问题内容: 我试图弄清楚为什么修改后的C程序比未修改的计数器部分运行得更快(我添加了很少的代码行来执行一些其他工作)。在这种情况下,我怀疑“ 缓存效果 ”是主要的解释(指令缓存)。因此,我到达了(https://perf.wiki.kernel.org/index.php/Main_Page)分析工具,但是不幸的是,我无法理解其有关缓存未命中的输出的含义。 提供了有关缓存的几个事件: 在哪里可以找
-
23.3 性能优化 CPU 使用率过高
什么是 CPU 使用率 CPU 使用率是单位时间内 CPU 使用情况的统计,以百分比的方式展示,我们通常所说的 CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比 怎么查看 CPU 使用率 top 和 ps 是最常用的性能分析工具:top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。ps 则只显示了每个进程的资源使用情况。 top 默认每 3 秒刷新一
-
23.2 性能优化 CPU 上下文切换
什么是 CPU 上下文 Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运行的错觉。而在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)。
-
SQLite表别名影响查询的性能
问题内容: SQLite如何在内部处理别名? 创建表名别名是在内部创建同一表的副本还是仅引用同一表而不创建副本? 当我在代码中创建同一表的多个别名时,查询性能会受到严重影响! 在我的情况下,我有一个表,将其称为MainTable,即2列,即名称和值。我想在一行中选择多个值作为不同的列。例如 名称:a,b,c,d,e,f 值:p,q,r,s,t,u ,使得a对应于p,依此类推。 我想在一行中选择名称
-
SQL Server 2005存储过程性能问题
问题内容: 我有以下问题:从我的应用程序一次调用存储的proc时,有时(例如1000次调用中有1次),需要10到30秒才能完成。通常,存储过程在不到一秒钟的时间内运行。这是一个非常简单的proc,只需单击一次即可将几个表联系在一起。所有表名都设置有(NOLOCK)提示,因此它可能没有锁定。索引也就位,否则它会一直很慢。 问题是,无论它运行sproc多少次,我都无法在SSMS中复制此问题(因为它始终
-
SQL Server中INNER JOIN与LEFT JOIN的性能
问题内容: 我创建了在9个表上使用INNER JOIN的SQL命令,无论如何,此命令将花费很长时间(超过五分钟)。所以我的同事建议我将INNER JOIN更改为LEFT JOIN,因为尽管我知道,但LEFT JOIN的性能更好。更改后,查询速度得到了显着提高。 我想知道为什么LEFT JOIN比INNER JOIN快? 我的SQL命令看起来象下面这样: 等 更新: 这是我的架构的简要介绍。 问题答
-
如何加快PostgreSQL中的插入性能
问题内容: 我正在测试Postgres插入性能。我有一张表,其中一列以数字作为其数据类型。也有一个索引。我使用以下查询填充数据库: 通过上面的查询,我一次非常快地插入了4百万行10,000。数据库达到600万行后,性能每15分钟急剧下降到100万行。有什么技巧可以提高插入性能?我需要此项目的最佳插入性能。 在具有5 GB RAM的计算机上使用Windows 7 Pro。 问题答案: 请参阅Post
-
Python性能提升之延迟初始化
本文向大家介绍Python性能提升之延迟初始化,包括了Python性能提升之延迟初始化的使用技巧和注意事项,需要的朋友参考一下 所谓类属性的延迟计算就是将类的属性定义成一个property,只在访问的时候才会计算,而且一旦被访问后,结果将会被缓存起来,不用每次都计算。构造一个延迟计算属性的主要目的是为了提升性能 property 在切入正题之前,我们了解下property的用法,property可
-
编写高性能Lua代码的方法
本文向大家介绍编写高性能Lua代码的方法,包括了编写高性能Lua代码的方法的使用技巧和注意事项,需要的朋友参考一下 前言 Lua是一门以其性能著称的脚本语言,被广泛应用在很多方面,尤其是游戏。像《魔兽世界》的插件,手机游戏《大掌门》《神曲》《迷失之地》等都是用Lua来写的逻辑。 所以大部分时候我们不需要去考虑性能问题。Knuth有句名言:“过早优化是万恶之源”。其意思就是过早优化是不必要的,会浪费
-
React性能:使用PureRenderMixin渲染大列表
问题内容: 我以TodoList为例来反映我的问题,但是显然我的实际代码更加复杂。 我有一些这样的伪代码。 我所有的数据都是不可变的,并且使用了并且一切正常。修改待办事项数据后,仅 重新渲染父项和已编辑的待办事项。 问题是,随着用户的滚动,我的列表有时会变得很大。并且,当更新单个待办事项时,渲染 父项,调用shouldComponentUpdate所有待办事项以及渲染单个待办事项所花费的时间越来越
-
SAP HANA中服务器的性能数据
本文向大家介绍SAP HANA中服务器的性能数据,包括了SAP HANA中服务器的性能数据的使用技巧和注意事项,需要的朋友参考一下 统计服务器用于管理HANA系统的运行状况。您可以从系统环境中的所有服务器获取与状态,资源性能消耗有关的信息。您还可以提取与服务器组件性能相关的报告以进行分析。
-
SQL连接与单个表:性能差异?
问题内容: 我试图坚持保持数据库规范化的做法,但这导致需要运行多个联接查询。如果许多查询使用联接而不是调用可能包含冗余数据的单个表,性能是否会下降? 问题答案: 直到发现瓶颈后,数据库才能正常化。然后,只有在仔细分析后,您才能对它们进行反规范化。 在大多数情况下,拥有一套覆盖面广的索引和最新的统计信息将可以解决大多数性能和阻塞问题,而不会进行任何非规范化。 如果对表进行写入和读取操作,则使用单个表
-
最小化会影响Node.js的性能吗?
问题内容: 在浏览器中,缩小和隐藏或加载异步JavaScript会对性能产生积极影响。在Node.js中运行的代码是否也是如此? 如Example那样,过多的注释和为实例化的类的属性使用长名称通常会严重影响性能和内存使用吗? 问题答案: 是的 ,它可以提高编译时的性能,但是编译时对您的整个过程生命周期而言无关紧要,因此无关紧要。唯一的区别是,如果您出于某种奇怪的原因而不断地启动和停止节点程序,那么
-
 golang、python、php、c++、c、java、Nodejs性能对比
golang、python、php、c++、c、java、Nodejs性能对比本文向大家介绍golang、python、php、c++、c、java、Nodejs性能对比,包括了golang、python、php、c++、c、java、Nodejs性能对比的使用技巧和注意事项,需要的朋友参考一下 本人在PHP/C++/Go/Py时,突发奇想,想把最近主流的编程语言性能作个简单的比较, 至于怎么比,还是不得不用神奇的斐波那契算法。可能是比较常用或好玩吧。 好了,tal
-
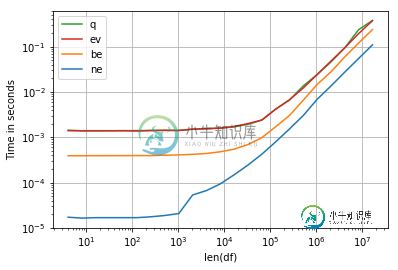 pandas数据框:位置与查询性能
pandas数据框:位置与查询性能问题内容: 我在python中有2个数据框,我想查询数据。 DF1:4M记录x 3列。查询函数比loc函数更有效。 DF2:2K记录x 6列。loc函数的接缝比查询函数更有效。 这两个查询都返回一条记录。通过将相同的操作循环运行10K次来完成仿真。 运行python 2.7和pandas 0.16.0 有什么建议可以提高查询速度? 问题答案: 为了提高性能,可以使用: