《flink》专题
-
将json提取到案例类SCALA FLINK时出错
问题在于在进行案例类提取时映射函数中。case类不可序列化。我隐式地定义了格式。 错误是: INFO[main](TypeExtractor.java:1804)-未检测到类组织的字段。json4s。JsonAST$JValue。不能用作PojoType。将作为线程“main”组织中的GenericType异常处理。阿帕奇。Flink。应用程序编程接口。常见的InvalidProgrameExce
-
如何将flink snapshot jar部署到私有maven存储库?
我已经构建了Flink的快照版本,并希望将其部署到我的私有nexus存储库中。我尝试在pom中添加以下配置。xml 然后运行“mvn部署”命令。不幸的是,maven仍然试图将Flink的快照部署到官方存储库中: [错误]无法执行目标组织。阿帕奇。专家插件:maven部署插件:2.8.2:project上的部署(默认部署):未能部署工件:无法传输工件组织。阿帕奇。flink:force shadin
-
添加跟踪和span id到Flink作业
我需要向集群中运行的Flink作业添加track和span id,请求流如下所示 使用者-- 我使用Spring Boot来创建我的rest API,并使用Spring Sleuth来添加跟踪和span id到生成的日志中,当调用rest API时添加跟踪和span id,当消息被放在Kakfa-toption-1上时也添加跟踪和span id,但我不能弄清楚如何添加跟踪和跨度ID,同时在Flin
-
Flink 1.9.1无法再连接到Azure Event Hub
Java 8, Flink 1.9.1, Azure事件集线器 从2020年1月5日起,我无法再用我的flink项目连接到azure event hub。我在几个spring boot应用程序中也遇到了同样的问题,但当我升级到spring boot 2.2.2时,这个问题得到了解决,它还将Kafka客户端和Kafka依赖项更新到2.3.1。我试图更新Flink的Kafka依赖项,但没有成功。我也提
-
Flink-没有用于scheme:hdfs的文件系统
我目前正在开发一个Flink 1.4应用程序,它从Hadoop集群读取一个Avro文件。然而,在我的IDE上以本地模式运行它是非常好的。但当我将其提交给Jobmanager Flink时,它总是失败,并显示以下消息: 我使用官方的Flink Docker image运行集群,该集群应该已经包含Hadoop发行版。 我还试图将依赖项添加到我的应用程序jar中,但这也没有帮助。以下是我的sbt依赖项:
-
Flink从hdfs读取数据
我是Flink大学的一年级新生,我想知道如何从hdfs读取数据。有谁能给我一些建议或简单的例子吗?谢谢大家。
-
Spark vs Flink内存不足
我已经建立了一个Spark and Flink k-means应用程序。我的测试用例是一个3节点集群上的100万个点的集群。 当内存瓶颈开始时,Flink开始外包给磁盘,工作缓慢,但工作正常。然而,如果内存已满,Spark将失去执行器,并再次启动(无限循环?)。 我尝试在邮件列表的帮助下自定义内存设置,谢谢。但是火花仍然不起作用。 是否需要设置任何配置?我是说Flink的记忆力很差,斯帕克也必须能
-
在苹果M1硅上运行Apache Flink 1.12作业
我刚刚尝试在Apple Mac Pro上运行Apache Flink的基本示例,新的M1处理器使用Rosetta 2兼容层。 不幸的是,它在以下堆栈跟踪中失败: 所以我的问题是,有人让它运行了吗?有可能在苹果硅上执行Flink工作吗? 编辑(13.04.2021)顺便说一句:使用Rosetta兼容层运行时发生此错误。因此,不幸的是,这并不能解决当前的问题。 编辑(2021年4月14日,回应理查德·
-
如何用嵌套字段注册Flink表模式?
我正在StreamingTableEnvironment中将数据流注册为Flink表。 我没有使用Create Table命令with connector注册流,因为数据格式是自定义的,这就是我为什么要注册流的原因。
-
Apache Flink:为DataStream API添加侧输入
注:Stream-1为主流,Stream-2为侧输入。主流正在不断从Kafka那里获取数据。对于侧输入,最初在应用程序启动时从DB加载所有表数据,然后在表数据更新时读取新数据(不频繁)。 示例结构: 我被指为以下链接。 用缓慢发展的数据连接流:我们用于丰富的侧输入是随着时间发展的(数据是从DB读取的)。这可以通过等待一些初始数据可用,然后处理主输入,并在新数据到达时不断地将其摄取到内部输入结构中来
-
在Flink中分裂流
如果我想在Flink中分裂一个流,那么最好的方法是什么?
-
Flink如何处理迭代循环中的时间戳?
如何在Flink中的迭代数据流循环中处理时间戳? null
-
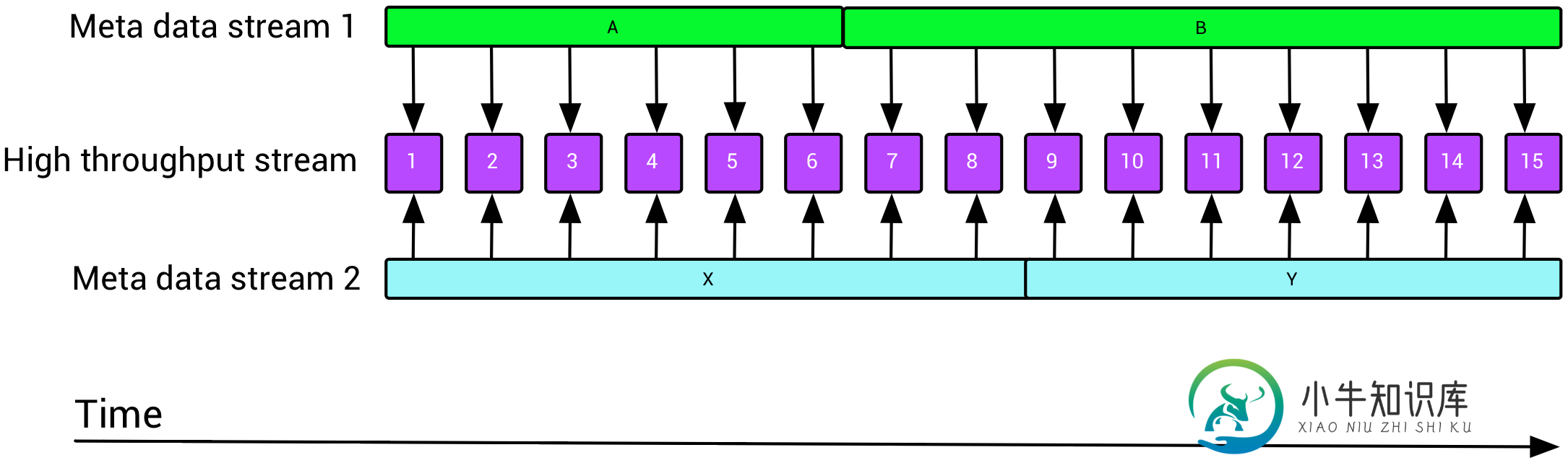 在Flink(浓缩)中结合低延迟流和多元数据流
在Flink(浓缩)中结合低延迟流和多元数据流我正在评估Flink,用于流式分析场景,但还没有找到足够的信息,说明如何实现我们今天在遗留系统中所做的ETL设置。 一个非常常见的场景是,我们有一个键控的低吞吐量元数据流,我们希望使用这些数据流来丰富高吞吐量数据流,如下所示: 这就提出了两个关于Flink的问题:如何使用时间窗口重叠但不相等的缓慢更新流来丰富快速移动的流(元数据可以活几天,而数据可以活几分钟)?如何有效地将多个(最多10个)流与F
-
多个Apache Flink windows验证
我刚刚开始使用Apache Flink进行流处理,我收到的Json流如下所示: 并被问到我是否可以履行以下业务规则: > 如果在过去10秒内此IP的令牌数>5,则拒绝 在另一个类中,我将对规则进行所有的逻辑操作,我将计算IP地址出现的次数,如果它超过了时间窗口中允许的次数,我将返回一条包含一些信息的消息: ruleMaker.java 到目前为止,我认为这段代码是有效的,但我对Apache Fli
-
在apache flink中筛选唯一事件
我在一个java类中定义某些变量,然后用另一个类访问它,以便在流中筛选唯一的元素。请参阅代码以更好地理解该问题。 我面临的问题是这个过滤函数不能很好地工作,无法过滤唯一的事件。我怀疑这个变量在不同的线程之间是共享的,它是原因!?如果这不是正确的方法,请建议另一种方法。提前道谢。