《flink》专题
-
Flink SQL 不支持 “table.exec.source.idle-timeout” 设置
我有一个运行FlinkSQL的Flink作业,具有以下设置: 为了用Kafka源代码在本地测试这一点,我向Flink作业触发了几个事件。Flink UI显示它生成了一个水印。我等待了3分钟,看看水印是否在没有发送新事件(即空闲分区)的情况下前进。但是,没有出现水印提升。 注意:我在本地使用具有三个分区的Kafka代理。我的测试数据被键入,因此被发送到同一个分区。但是,即使其他分区空闲并且等待3分钟
-
Apache Flink-序列化json并执行连接操作
我试图使用Jackson库读取Kafka主题中的字符串,并从另一个流执行连接。 这是一个包含两个数据流的示例代码。我想对这些消息流执行连接操作。 例如,传入的流是: 连接条件是。我如何在Flink中实现这一点? 数据流 1: 数据流 2:
-
Flink:将事件附加到有限数据流的末尾
假设存在一个有限的 DataStream(例如,来自数据库源)和事件 < li> 。 如何将另一个事件< code>b追加到此流以获取 (即在所有原始事件之后输出添加的事件,保持原始顺序)? 我知道所有有限流在所有事件之后都会发出< code>MAX_WATERMARK。那么,有没有办法“抓住”这个水印,输出它之后的附加事件呢? (不幸的是,<代码>。union()将原始数据流与由单个事件组成的另
-
为什么Flink流不支持左连接表达式?
Flink Stream支持内部连接表达式,如窗口连接,间隔连接。但不支持左连接/完全连接表达式。当然,窗口共组表达式可以实现相同的语义,即使事件已立即加入,也必须等待完全窗口大小的时间。我的问题是: 如何从设计角度解释Flink Stream不支持左连接/全连接说明? 我如何通过Flink DataStream API实现它(如果可以立即转发加入事件会更好)? 有没有办法扩展Flink Data
-
在EMR集群中提交Flink作业:未能初始化集群入口点YarnJobClusterEntrypoint
我正在使用EMR 5.30.0,并尝试使用以下命令提交Flink(1.10.0)作业 想知道是否每个提交的作业都试图创建一个Flink Yarn会话,而不是使用现有的会话。 谢谢Sateesh
-
Apache Flink生产集群详细信息
我是Flink的新手。如何了解flink的生产集群要求。以及如何确定纱线集群模式下每个作业执行的作业内存、任务内存和任务槽。例如,我每天必须使用datastream处理大约6-7亿条记录,因为这是一个实时数据。
-
无法使用Zookeeper启动Flink HA群集
我试图安装一个Flink HA群集(动物园管理员模式),但任务管理器找不到作业管理器。 这里我给你介绍一下建筑; 大师: 奴隶: flink-conf.yaml: 这里是任务管理器的日志,它试图连接到localhost而不是Machine1: PS.:/etc/hosts包含localhost、Machine1和Machine2 你能告诉我任务经理如何连接到工作经理吗? 当做
-
在Flink群集上找不到FlinkKaConsumer011
我正试图在集群上运行Flink作业。这份工作在我的开发(本地)环境下运行良好。但当我使用以下命令将其部署到集群上时: 它失败了,错误如下: 我还添加了所需的依赖项 我正在使用构建jar文件
-
远程调试Flink本地集群
我希望在开发期间将作业部署到本地Flink集群上(即在开发笔记本电脑上运行的JobManager和TaskManager),并使用远程调试。我尝试将“-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005”添加到flink-conf.yaml文件中。由于作业和任务管理器在同一台机器上运行,任务管理器引发异常,指出套接字已
-
Flink HA群集作业管理器问题
我有一个Flink 1.2集群的设置,由3个JobManager1和2个TaskManager1组成。我从JobManager1开始动物园管理员法定人数,我得到确认,动物园管理员开始其他2个JobManager1,然后我在这个JobManager1上开始一个Flink作业。 flink-conf.yaml在所有5个虚拟机上都是相同的,这意味着jobmanager。rpc。地址:指向各处的JobMa
-
Apache Flume vs Apache Flink 的区别
我需要从某个来源读取数据流(在我的情况下是UDP流,但这无关紧要),转换每条记录并将其写入HDFS。 使用Flume或Flink有什么区别吗? 我知道我可以将 Flume 与自定义拦截器一起使用来转换每个事件。 但我是 Flink 的新手,所以对我来说,看起来 Flink 也会这样做。 选哪个比较好?性能有区别吗? 拜托,救命啊!
-
Apache Flink中具有大状态的保存点
我想使用Rocksdb状态后端在Flink中保持大约2TB的状态。我将使用增量检查点,因此它将大大减少检查点时间。 但我有时不得不更改代码,例如重新缩放、错误修复、添加新的过滤器/映射、添加新的源/汇等。 所有这些都会影响作业拓扑。当状态发生任何变化时,我可以再次引导状态。但其他时候,引导状态可能很困难,因为这意味着我浪费时间。 在这种情况下,我必须采取一个保存点来重新开始我的工作。当作业运行时,
-
在跨多个作业拆分Flink工作负载时,如何避免冗余IO和反序列化
为了使Flink工作负载的部署和管理更容易,我们希望运行多个较小的作业,而不是一个完成所有工作的大型作业。我们面临的问题是,这些较小的作业中的每一个都必须读取和反序列化来自Kafka的相同输入数据。 我们已经进行了性能测试,结果表明,运行多个作业(每个作业都读取输入数据)比处理单个作业相同的数据需要更多的资源和更长的时间。 有没有一种方法可以读取一次输入数据,然后运行多个作业来只执行处理步骤,或者
-
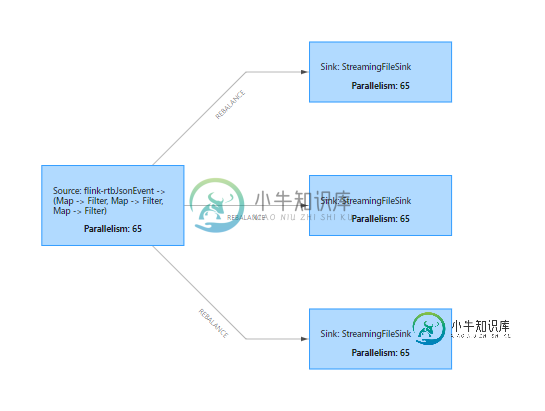 使用Flink Kafka连接器均匀地消耗事件
使用Flink Kafka连接器均匀地消耗事件我正在使用Flink处理Kafka的流数据。流程非常基本,从Kafka开始消耗,数据丰富,然后汇到FS。 在我的例子中,分区的数量大于Flink并行级别。我注意到Flink并没有均匀地消耗所有分区。 有时,在一些Kafka分区中会创建滞后。重新启动该应用程序有助于Flink“重新平衡”消费,并快速关闭滞后。然而,过了一段时间,我看到其他分区出现了滞后等现象。 看到这种行为,我试图通过使用flink
-
Flink中的缓存位置
我有一个数据流,其中包含一个键,我需要将其与与该键关联的数据进行混合和匹配。每个键都属于一个分区,每个分区都可以从数据库加载。 数据非常大,在一个任务管理器中,几十万个分区中只有几百个可以容纳。 我目前的方法是基于并将分区数据缓存在中,以混合和匹配分区数据,而无需多次重新加载分区数据。 当同一分区上的消息速率过高时,我遇到了热点/性能瓶颈。 在这种情况下,我在Flink中有哪些工具可以提高吞吐量?