
使用Flink Kafka连接器均匀地消耗事件

我正在使用Flink处理Kafka的流数据。流程非常基本,从Kafka开始消耗,数据丰富,然后汇到FS。
在我的例子中,分区的数量大于Flink并行级别。我注意到Flink并没有均匀地消耗所有分区。
有时,在一些Kafka分区中会创建滞后。重新启动该应用程序有助于Flink“重新平衡”消费,并快速关闭滞后。然而,过了一段时间,我看到其他分区出现了滞后等现象。
看到这种行为,我试图通过使用flink留档中建议的重新平衡()来重新平衡消费率:
分区元素循环,为每个分区创建相等的负载。对于存在数据倾斜的情况下的性能优化非常有用
数据流。再平衡();
代码中的更改很小,只需将rebalance()添加到数据流源中即可。使用rebalance()运行应用程序导致Flink出现一个非常奇怪的行为:
我将并行级别设置为260并提交了一个作业,但由于某种原因,作业管理器将插槽数乘以4。查看执行计划图,我意识到现在所有数据都被260个内核消耗,然后被发送到3个接收器(希望是均匀的)。由于缺乏资源,作业失败。
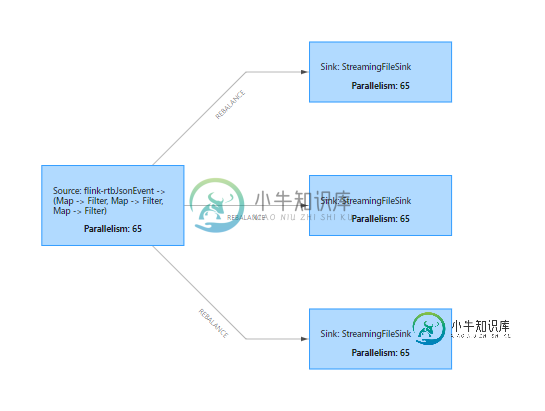

因为我想使用260个核心,所以我尝试再次提交作业,这次是65 (=260/4)的并行级别。作业运行良好,但处理率低。在web用户界面中,我发现槽的总数不等于运行任务的可用任务槽。但是,如果我将rtbJsonRequest(我提交的作业)称为具有65 (=260/4)任务槽的作业,而不是编写时的260,则等于。
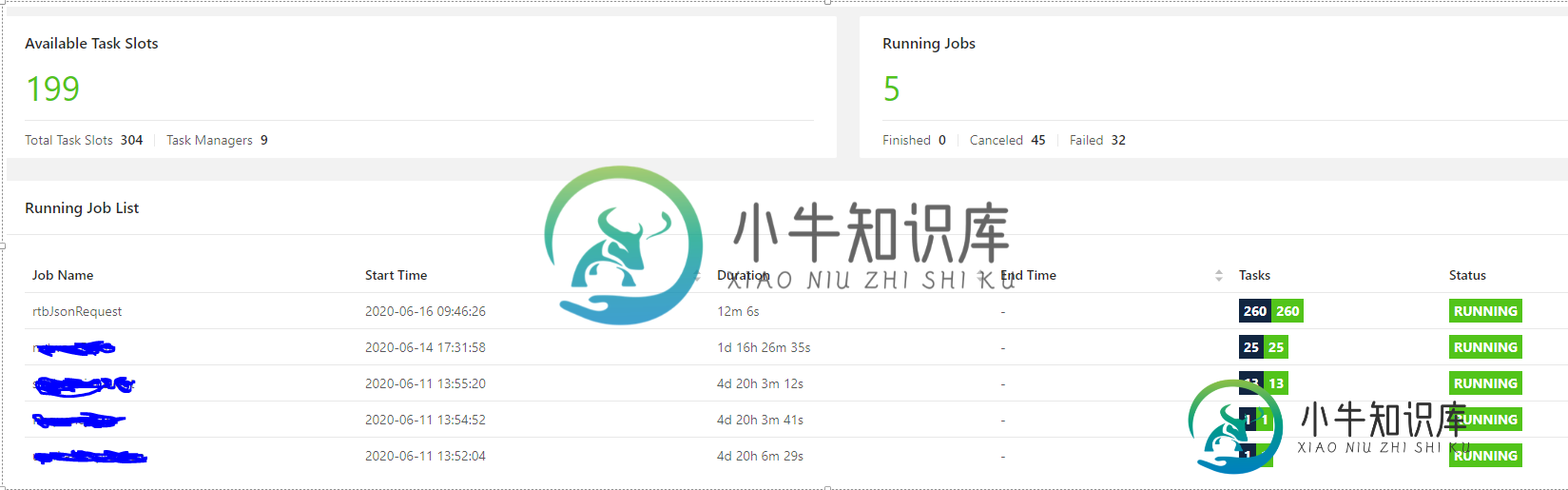
增加更多的投入。本主题共有520个分区,并行度为260(每个核心有2个分区)。
共有3个答案

Properties properties = new Properties();
properties.setProperty("group.id", consumerGroup);
properties.setProperty("auto.offset.reset", autoOffsetReset);
properties.setProperty("bootstrap.servers", kafkaBootstrapServers);
properties.setProperty(
"flink.partition-discovery.interval-millis", "30000");
我向属性添加了分区发现,作业抛出一个NPE。这是设置分区发现属性的正确方法吗?
java.lang.NullPointerException: null
at org.apache.flink.streaming.connectors.kafka.internal.Kafka09PartitionDiscoverer.getAllPartitionsForTopics(Kafka09PartitionDiscoverer.java:77)

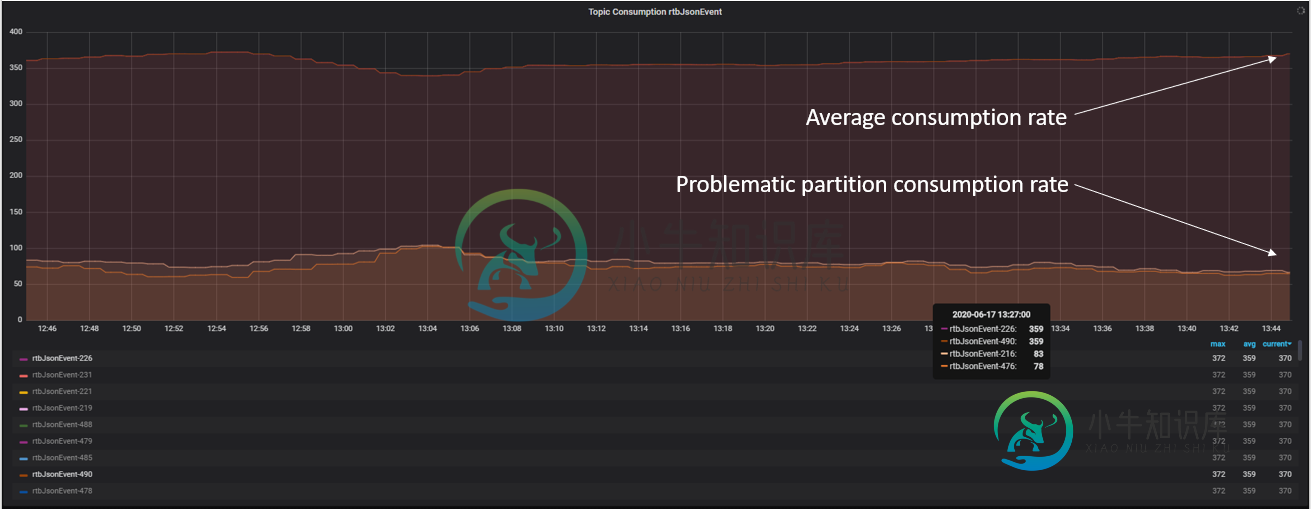
我发现我的两个Flink任务经理与其他员工相比处理率非常低。
正如您在下面的屏幕截图中所看到的,每秒少于5K个事件,而其他处理至少37K个事件:
这真的让我明白了,我面临的是一个环境问题,而不是一个棘手的问题。在我的例子中,安装CPU控制器并重新启动机器解决了问题。
在这个过程中,我学到了一件非常重要的事情,默认情况下,Flink不会发现Kafka分区。如果您想添加它,只需添加到您的属性:
"flink.partition-discovery.interval-milis","time_interval"

在源之后插入再平衡不会平衡源本身,而是通过在作业图中插入循环网络洗牌来平衡后续输入。这最多只能平衡水槽上的负载,这对解决问题没有帮助。
您总共使用了多少个Kafka分区?您使用的是主题还是分区发现?重新开始工作是有帮助的,这看起来确实很奇怪。
-
我有一个有几个消费者的消费群体。每个使用者被分配到一组分区。消费者何时轮询选择了已使用分区的消息?它是在消费者端完成的,还是Kafka服务器决定使用哪个分区? 我的一些分区有很多消息,但有些分区没有或几乎没有。但我仍然需要我的消费者平等地使用分配给它的每个分区。因此,我需要我的消费者快速遍历分区,最好从每个分配的分区轮询x条消息。 我在用https://github.com/appsignal/r
-
0.1-0.2:********** 0.2-0.3:******** 0.3-0.4:********* 0.5-0.6:********* 0.6-0.7:********* 0.7-0.8:********* 0.4-0.5:********* 0.5-0.6:********* 0.6-0.7:********* 0.1-0.2:********* 0.2-0.3:********* 0.
-
这是我的kafka连接器属性 这是我用来创建Elasticsearch水槽的POST主体 我遇到的问题是,有时这个接收器会工作并将数据发送到Elasticsearch并显示 〔2020-09-15 20:27:05904〕INFO WorkerLinkTask{id=test-distributed-connector-0}使用序列号1异步提交偏移。。。。。。。 但大多数时候,它只会卡住并重复这一
-
如图所示,在队列-上发布的n条消息中,消费者(和)之间的分布是不均匀的。我可以观察到,只接收到n条消息中的一条。 两个使用者都传递完全相同的STOMP报头。以下是- STOMP连接头 null null broker.xml 使用的受体是端口为61616的artemis受体
-
用户上传一个由一百万字组成的巨大文件。我解析文件并将文件的每一行放入< code>LinkedHashMap中 我需要按键访问和删除O(1)。此外,我需要保留访问顺序,从任何位置迭代并排序。 内存消耗是巨大的。我启用了的重复数据删除功能,该功能出现在Java 8中,但事实证明,消耗了大部分内存。 我找到了< code>LinkedHashMap。Entry占用40个字节,但是只有2个指针——一个指
-
大家好,我正在努力将一个简单的avro模式与模式注册表一起序列化。 设置: 两个用java编写的Flink jobs(一个消费者,一个生产者) 目标:生产者应该发送一条用ConfluentRegistryAvroSerializationSchema序列化的消息,其中包括更新和验证模式。 然后,使用者应将消息反序列化为具有接收到的模式的对象。使用。 到目前为止还不错:如果我将架构注册表上的主题配置