《flink》专题
-
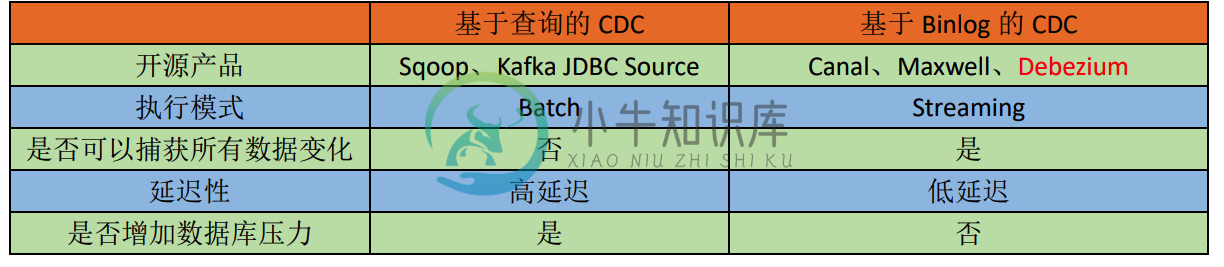 Flink CDC
Flink CDC主要内容:1.CDC概述,2.Flink CDC 编码,3.利用自定义格式编码,4.Flink Sql 编码,5.Flink CDC 2.0 的新特性1.CDC概述 1.1 CDC CDC 是 Change Data Capture()的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。 1.2 CDC 分类 分为查询CDC 和 Binlog CDC 常见的CDC 方案比较 1.3
-
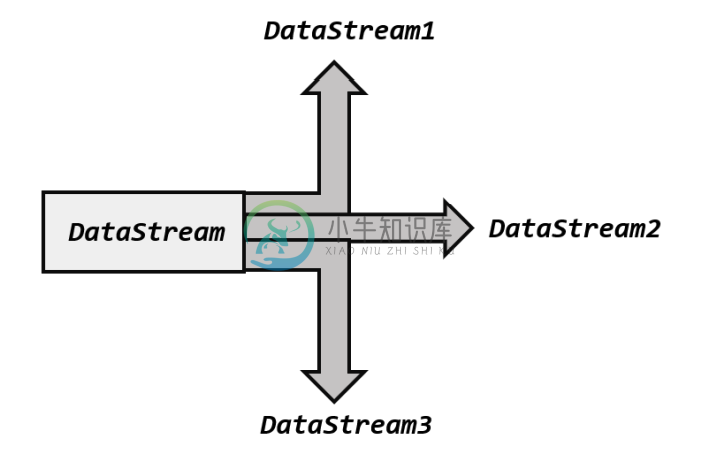 Flink 多流转换
Flink 多流转换主要内容:1.分流,2.Union聚合,3.Connect 连接,4.Join 合流,5.总结分流和合流 分流的方式: 侧输出流 合流的方式: Union, Connect, Join, CoGroup 1.分流 所谓“分流”,就是将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个DataStream,得到完全平等的多个子 DataStream,如图 8-1 所示。一般来说,我们会定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里。 1.1 简单实现 其实根据条件筛选数据的
-
 Flink教程4-Sink输出
Flink教程4-Sink输出主要内容:1.输出到File文件,2.输出到Kafka中,3.输出到Mysql中,4.输出到Redis中,5.输出到ElasticSearch中1.输出到File文件 2.输出到Kafka中 kafka -> flink转换 -> kafka 3.输出到Mysql中 maven 4.输出到Redis中 maven: 5.输出到ElasticSearch中 maven:
-
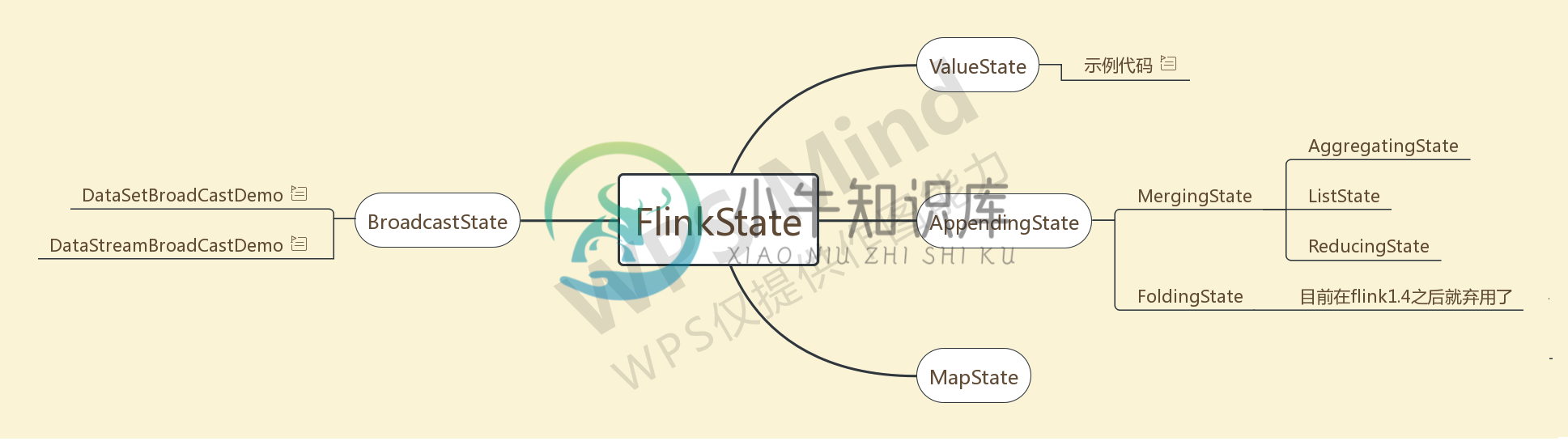 Flink之State状态编程
Flink之State状态编程主要内容:1.State分类,2.算子状态(Operator State),3.键控状态(keyed State),4.状态后端(state backends),5.状态编程1.State分类 首先是分为托管状态和原始状态, 托管状态指的是状态交给Flink去管理 托管状态分为算子状态和按键分区状态 一般我们用的就是按键分区状态, 可以支持的数据类型为值状态, 列表状态, 映射状态, 归约状态, 聚合状态 State[ValueState、ReadOnlyBroadcastState、MapSt
-
Apache Flink
Apache Flink 是高效和分布式的通用数据处理平台,是一个流批一体分析引擎。 Apache Flink 声明式的数据分析开源系统,结合了分布式 MapReduce 类平台的高效,灵活的编程和扩展性。同时在并行数据库发现查询优化方案。 要求 Unix 类环境(Linux, Mac OS X, Cygwin) git Maven (at least version 3.0.4) Java 6,
-
flink-learning
Flink 学习 麻烦路过的各位亲给这个项目点个 star,太不易了,写了这么多,算是对我坚持下来的一种鼓励吧! Stargazers over time 本项目结构 How to build Maybe your Maven conf file settings.xml mirrors can add aliyun central mirror : <mirror> <id>alimaven<
-
flink
Apache Flink Apache Flink is an open source stream processing framework with powerful stream- and batch-processing capabilities. Learn more about Flink at https://flink.apache.org/ Features A streamin
-
Flink Remote Shuffle
Flink Remote Shuffle 是一种批场景下利用外部服务完成任务间数据交换的 Shuffle 实现,本文后续将详细介绍 Flink Remote Shuffle 研发的背景,以及 Flink Remote Shuffle 的设计与使用。 重要特性 存储计算分离:存储计算分离使计算资源与存储资源可以独立伸缩,计算资源可以在计算完成后立即释放,Shuffle 稳定性不再受计算稳定性影响。
-
Pulsar-Flink Connector
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展流数据存储特性。 Apache Flink是一款面向数据流处理和批量数据处理的分布式的计算引擎,它可以用来做批处理,即处理静态的数据集、历史的数据集;也
-
java - flink-connector-mysql-cdc 2.1.1 监听mysql,其中mysql的主键 是 二进制 格式,出现如下错误?
使用flink-connector-mysql-cdc 2.1.1 监听mysql,其中mysql的主键 是 二进制 格式,出现如下错误。 请问各位大佬如何解决? 按照我的理解 是拆表的时候 出现的问题,应该不是反序列化的问题吧?
-
 0.0053这样一个bigdecimal类型的数它的precision是2, flink中tableEnv使用fromValues直接报错怎么办?
0.0053这样一个bigdecimal类型的数它的precision是2, flink中tableEnv使用fromValues直接报错怎么办?我就纳了闷了, flink用tableAPI不允许写入0.xxx的小数数值???, 合着flink开发人员就不知道存在0.xxx的数值? 不知道bigdecimal是从非0的值开始算长度的??? 转成字符串也是写入不进去的, 类型不匹配, 但是我也设置了字段类型了: 有没有大佬知道这个怎么解决呢
-
flink可以做像报表数据一样的任务吗?
比如说有个任务的要求是以一个表的数据为主, 关联到其他表, 其他表的数据中某个字段的值要累加以及各种计算再和主表的某些字段组合成一个新的数据, flink能做这样的任务吗
-
flink任务中如果要在某个任务执行完成后再次开启另一个任务该怎么做呢?
比如说有个需求, 任务1执行完成了, 将数据存到数据库了, 然后立马要开启下一个任务, 获取所有的数据和其他表的数据进行清洗, 然后存到另一个表里 第一个任务是从kafka里获取的增量数据, 然后直接存到库里, flink执行起来就是source -> sink -> execute 这时候第一个任务完成了, 要开启第二个任务了, 需要从数据库里获取新的数据和其他表的数据进行清洗 source -
-
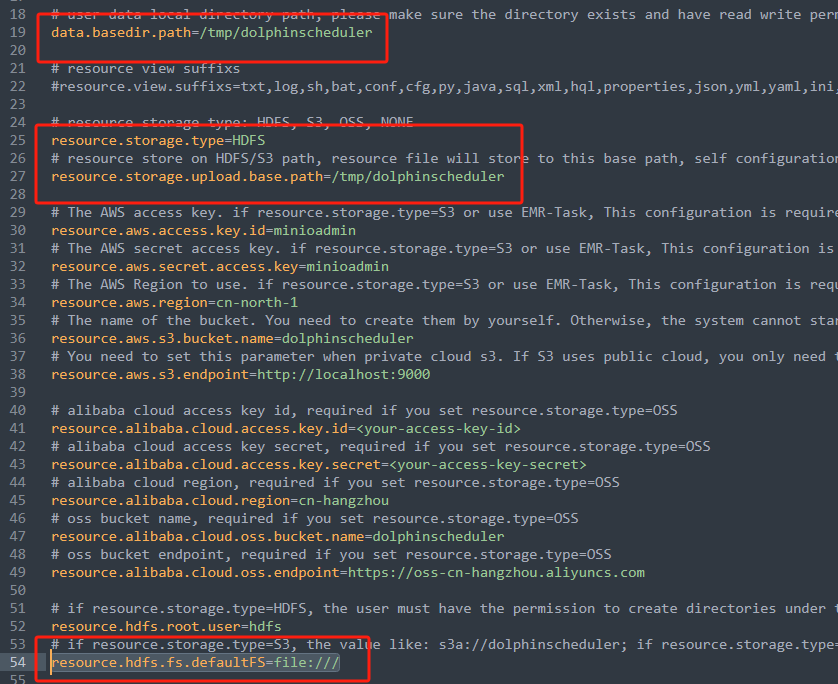 flink - dolphinscheduler在docker中执行任务上传的附件下载不到怎么回事呢?
flink - dolphinscheduler在docker中执行任务上传的附件下载不到怎么回事呢?用的本地存储, 这个是配置: 这是上传的附件: 这是任务执行的日志: 在容器中也能找到这个上传的附件: 这是怎么回事呢?
-
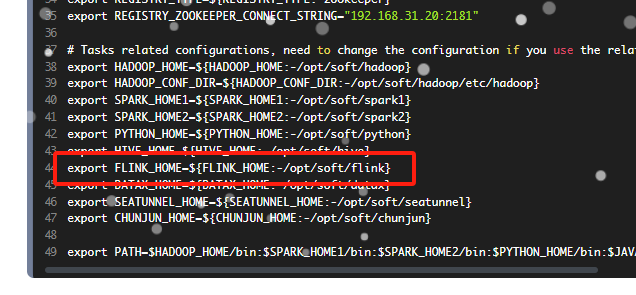 DolphinScheduler在docker中如何配置同样在docker中的flink呢, FLINK_HOME的配置那里该怎么写呢?
DolphinScheduler在docker中如何配置同样在docker中的flink呢, FLINK_HOME的配置那里该怎么写呢?DolphinScheduler和flink现在都安装在了docker中, 但是DolphinScheduler有这样一个配置, 该怎么写呢? DolphinScheduler和flink都在同一个服务器上的