《flink》专题
-
如何在纱线上的flink作业上配置java home
当我没有配置java home时,我提交了如下作业错误
-
flink hadoop实现问题-无法找到方案hdfs的文件系统实现
我正在努力将hdfs集成到flink。 Scala二进制版本:2.12, Flink(群集)版本:1.10.1 这里是HADOOP_CONF_DIR; hdfs的配置在这里; 这个配置和HADOOP_CONF_DIR在任务管理器中也是一样的。 pom.xml; 我试图从hdfs获取拼花地板文件的全部内容,我的示例代码就在那里; 错误就在这里; 这是一个奇怪的部分,正如您在lib文件夹下看到的Had
-
如何在nfs文件系统中存储apache flink检查点
我正在使用Apache Flink 1.10.0从RabbitMQ拉数据流,现在我在内存中使用默认检查点配置。现在为了在任务管理器重启时恢复,我需要在文件系统中存储状态和检查点,所有演示都应该使用“hdfs://namenode: 4000/......”,但是现在我没有HDFS集群,我的Apache Flink在kubernetes中运行集群,如何将我的检查点存储在文件系统中? 我阅读了Apac
-
Flink bucketing接收器使用存储点重新启动导致数据丢失
我正在使用从Kafka到HDFS的Flink bucketing水槽。Flink的版本是1.4.2 我发现每次重新启动作业时都会有一些数据丢失,即使使用保存点也是如此 我发现如果我设置writer SequenceFile,这个问题可以解决。挤压型。记录而不是序列文件。挤压型。块当Flink试图保存检查点时,有效长度似乎与实际长度不同,实际长度应该包括压缩数据 但如果不能使用压缩类型,则可能会出现
-
关于flink溪流水槽至hdfs
我正在编写一个flink代码,其中我正在从本地系统读取一个文件,并使用“writeUsingOutputFormat”将其写入数据库。 现在我的要求是写入hdfs而不是数据库。 你能帮我在Flink怎么办吗。 注意:hdfs已启动并在本地计算机上运行。
-
模板标签参考 - 全局标签 - flink|友情链接
flink|友情链接: 标签名称:flink 标记简介: 功能说明:用于获取友情链接 适用范围:全局使用 基本语法: {dede:flink row='24'/} 参数说明: type='image' 或textall,图片链接,text文字链接; row='24' 链接数量 titlelen='24' 站点文字的长度 linktype='2' 链接位置首页 linktype='1' 链接位置内页
-
 Flink-cep-2
Flink-cep-2主要内容:1.模式Api (Partern Api),2.模式的检测,3匹配的事件的提取,4.超时事件的提取,5.CEP的状态机实现1.模式Api (Partern Api) Flink CEP 核心就是模式 1.1 个体模式 1.1.1 个体模式形式 每一个简单事件并不是任意选取的,也需要有一定的条件规则;所以我们就把每个简单事件的匹配规则称为个体模式 这些都是个体模式。个体模式一般都会匹配接收一个事件, 以begin, next开头的。 1.1.2 个体模式中的量词 .oneOrMore()
-
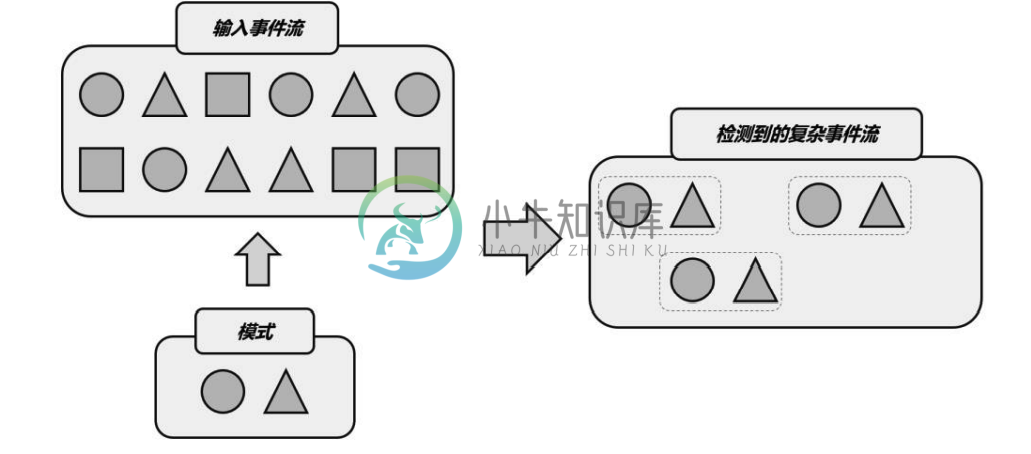 Flink-cep-1
Flink-cep-1主要内容:1.CEP概述,2.模式,3.CEP 的应用场景,4.快速上手代码1.CEP概述 复杂事件处理(Complex Event Processing) 总结起来,复杂事件处理(CEP)的流程可以分成三个步骤: 定义一个匹配规则 将匹配规则应用到事件流上,检测满足规则的复杂事件 对检测到的复杂事件进行处理,得到结果进行输出 输入的事件流在一个模式规则中输出得到的数据流 CEP 是针对流处理而言的,分析的是低延迟、频繁产生的事件流。 目的在于在无界流中检测出特定的数据组
-
 Flink-Sql和Table Api-3
Flink-Sql和Table Api-3主要内容:1.函数,2.SQL 客户端,3.连接外部系统1.函数 系统内置函数 UDF函数 1.1 系统自定义函数 标量函数(Scalar Functions) 聚合函数(Aggregate Functions) 1.1.1 标量函数 所谓的“标量”,是指只有数值大小、没有方向的量;所以标量函数指的就是只对输入数据做转换操作、返回一个值的函数。这里的输入数据对应在表中,一般就是一行数据中 1 个或多个字段,因此这种操作有点像流处理转换算子中的 map。
-
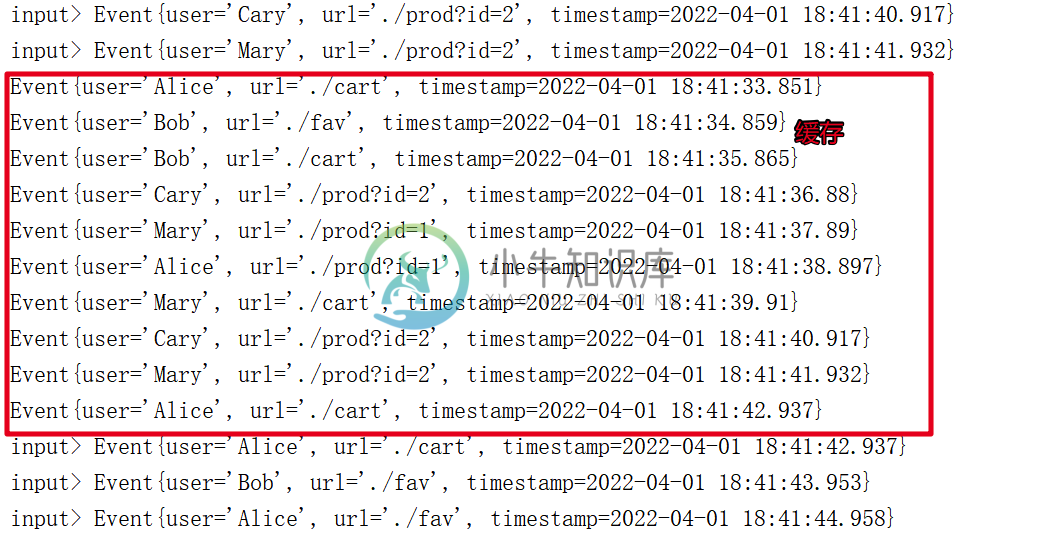
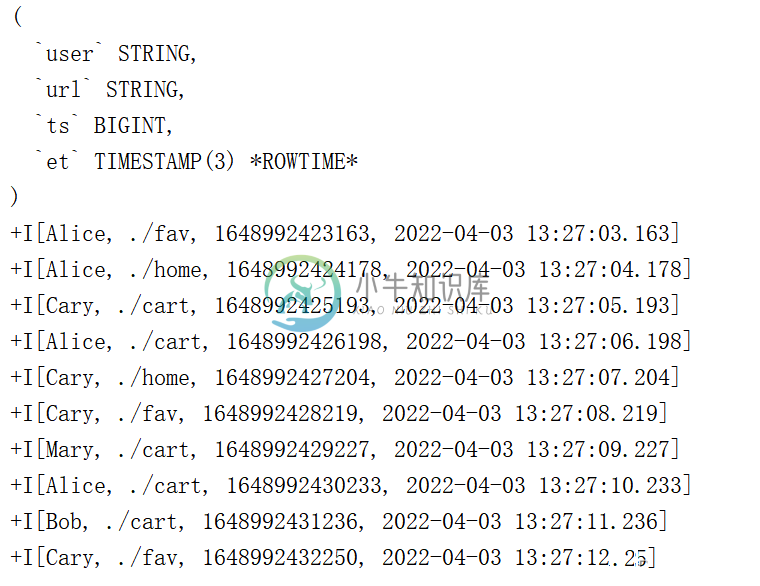 Flink-Sql和Table Api-2
Flink-Sql和Table Api-2主要内容:1.时间属性 Time,2.窗口 Window,3.聚合查询,4.TopN例子1.时间属性 Time 基于时间的操作(比如时间窗口),需要定义相关的时间语义和时间数据来源的信息。在Table API 和 SQL 中,会给表单独提供一个逻辑上的时间字段,专门用来在表处理程序中指示时间。 所以所谓的(time attributes),其实就是每个表模式结构(schema)的一部分。它可以在创建表的 DDL 里直接定义为一个字段,也可以在 DataStream 转换成表时定义。一
-
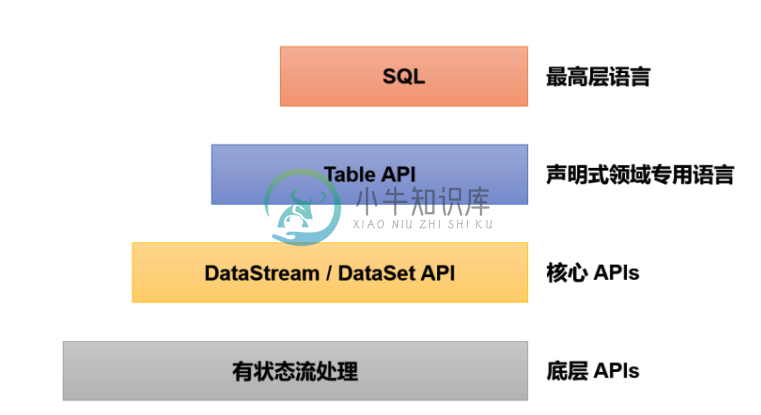 Flink-Sql和Table Api-1
Flink-Sql和Table Api-1主要内容:1.Flink Sql介绍,2.快速上手,3.相关表1.Flink Sql介绍 可以看出来Flink SQL 位于顶层 在 Flink 中这两种 API 被集成在一起,SQL 执行的对象也是 Flink 中的表(Table),所以我们一般会认为它们是一体的。 Flink 是批流统一的处理框架,无论是批处理(DataSet API)还是流处理(DataStream API),在上层应用中都可以直接使用 Table API 或者 SQL 来实现。 2.
-
 Flink-状态编程-2
Flink-状态编程-2主要内容:1.算子状态概述,2.算子状态 编程案例,3.状态持久化和状态后端,4.状态编程总结1.算子状态概述 1.1 算子状态分类 算子状态: 列表状态, 联合列表状态, 广播状态 ListState, UnionListState, BroadcastState 1.2 状态分析 列表状态: 与 Keyed State 中的 ListState 一样,将状态表示为一组数据的列表。与 Keyed State 中的列表状态的区别是:在算子状态的上下文中,不会按键(key)分别处理状态,所以
-
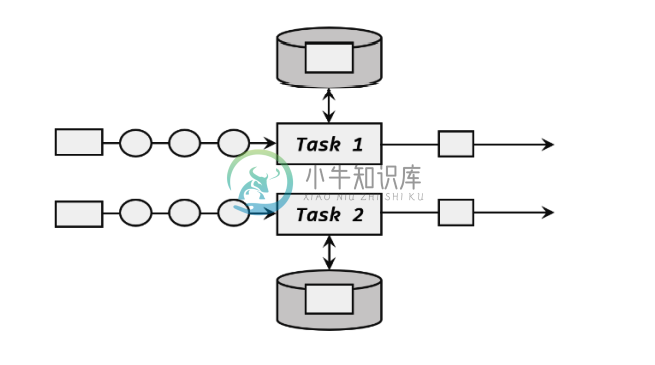 Flink-状态编程-1
Flink-状态编程-1主要内容:1.Flink 中的状态,2.按键分区状态 (keyed state),3.状态生存时间 Ttl,4.状态一致性说明1.Flink 中的状态 1.1 状态管理 状态的访问权限。我们知道 Flink 上的聚合和窗口操作,一般都是基于 KeyedStream的,数据会按照 key 的哈希值进行分区,聚合处理的结果也应该是只对当前 key 有效。然而同一个分区(也就是 slot)上执行的任务实例,可能会包含多个 key 的数据,它 们同时访问和更改本地变量,就会导致计算结果错误。所以这时状态
-
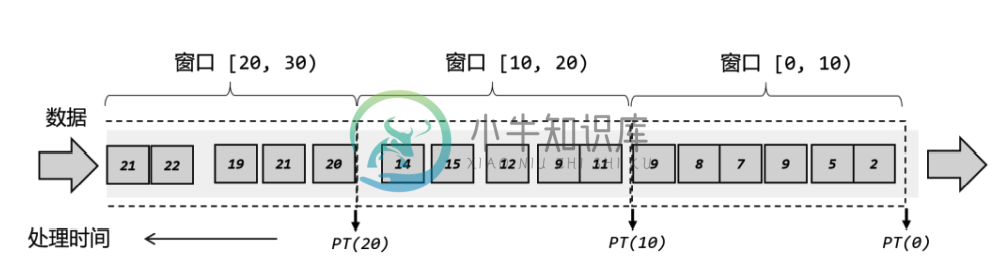 Flink-窗口-Window
Flink-窗口-Window主要内容:1.窗口概述,2.窗口分类,3.细分,4.窗口Api,5.窗口分配器 Window Assigners,6.窗口函数,7.TopN 实例1.窗口概述 Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。 在 Flink 中, 窗口就是用来处理无界流的核心。我们很容易把窗口想象成一个固定位置的“框”,数据源源不断地流过来,到某个时间点窗口
-
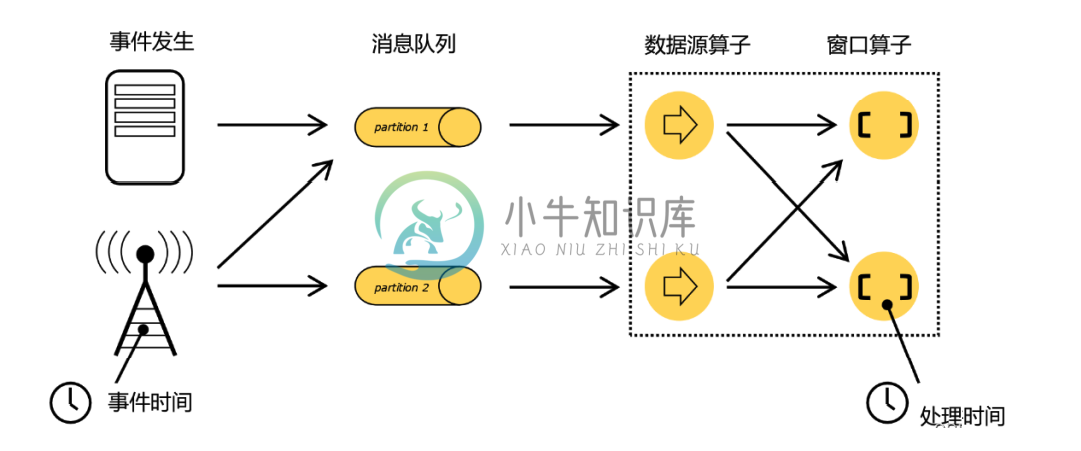 Flink-Time-时间语义-水平线
Flink-Time-时间语义-水平线主要内容:1.时间语义概述,2.水平线 Watermark1.时间语义概述 对于一台机器而言,“时间”自然就是指系统时间。但我们知道,Flink 是一个分布式处理系统。分布式架构最大的特点,就是节点彼此独立、互不影响,这带来了更高的吞吐量和容错性;但有利必有弊,最大的问题也来源于此。 在事件发生之后,生成的数据被收集起来,首先进入分布式消息队列,然后被 Flink 系统中的 Source 算子读取消费,进而向下游的转换算子(窗口算子)传递,最终由窗口算子