《flink》专题
-
Flink是否可以产生聚合/滚动/累积数据的每小时快照?
流处理的教科书示例是一个带有时间戳的单词计数程序。使用以下数据示例 但是,我还没有找到一个在滚动时间窗口上的单词计数程序的例子,即我希望每小时产生一个从时间开始的每个单词的单词计数: 对于Apache Flink或任何其他流处理库,这是可能的吗?谢谢! 编辑: 马里奥,路易吉,马里奥,马里奥,维尔马,弗雷德,鲍勃,鲍勃,马里奥,丹,迪伦,迪伦,弗雷德,马里奥,马里奥,卡尔,班巴姆,萨默,安娜,安娜
-
Apache Flink:如何在摄取时间模式下获取事件的时间戳?
我想知道是否可以通过使用Flink的摄取时间模式获得记录的时间戳。考虑以下flink代码示例(https://github.com/apache/flink/blob/master/flink-examples/flink-examples-streaming/src/main/scala/org/apache/flink/streaming/scala/examples/join/windowj
-
Apache Flink:如何应用多个计数窗口函数?
我有一个数据流是键控的,需要计算不同时间段(1分钟,5分钟,1天,1周)的翻滚计数。 有可能在一个应用程序中计算所有四个窗口计数吗?
-
Apache Flink作业中的多数据流支持
其他流式框架(如Apache Samza、Storm或Nifi)是否可以实现这一点? 我们非常期待得到答复。
-
Apache Flink:如何处理延迟事件?
-
Flink中的会话窗口会产生意外结果
我有一个由两个字段“键控”的记录流,然后分配一个间隔为30秒的会话窗口。我使用附加在记录上的“时间戳”作为事件时间。我正在使用“Assign AscendingTimeStamps”水印。 以下面的记录为例。该流由(用户,place)键控。 Record1:user1,place1,timestamp t1 Record2:user2,place1,timestamp在t1之后30秒 桶1 Rec
-
Flink:在时间窗口中合并所有键的结果
我使用的是EventTime,它从Kafka记录中的一个字段中派生出时间戳。在apply运算符之后,事件不再有时间戳记录,而是有一个很长的WindowStartTime。
-
在Flink流中使用静态数据集丰富数据流
我正在编写一个Flink流程序,其中我需要使用一些静态数据集(信息库,IB)来丰富用户事件的数据流。 对于例如。假设我们有一个买家的静态数据集,并且我们有一个事件的clickstream,对于每个事件,我们要添加一个布尔标志,指示事件的实施者是否是买家。 另一个选择可以是使用托管操作员状态来存储购买者设置,但是我如何保持按用户id分配的该状态,以避免在单个事件查找中使用网络I/O呢?在内存状态后端
-
Flink状态后端密钥原子性和分布
在阅读了flink文档之后(相关部分在下面注明),我仍然没有完全理解原子性和密钥分配。 即考虑一个由keyby->flatmap(包含一个map状态)组成的图,并将并行度设置为1和4个任务槽,flink是否确保每个键在分布式环境中只存在一次(在一个任务槽中),它是原子单元?提前感谢所有的帮助者。 密钥状态被进一步组织成所谓的密钥组。密钥组是Flink重新分配密钥状态的原子单位;关键组的数量与定义的
-
Flink中算子并行性的几个难题
我刚刚得到了下面的例子,用于并行性,并有一些相关的问题: > setParallelism(5)将并行度5设置为sum或同时设置flatMap和sum? 有没有可能,我们可以将不同的并行度分别设置到不同的运算符如flatMap和sum上?比如将并行度5设置到sum,将并行度10设置到flatMap上。
-
如果Flink的keyBy操作符被赋予不同的键,然后是滚动窗口,会发生什么
我的flink作业有keyBy操作符,它将date~clientID(date为yyyymmddhmm,MM为5分钟后更改的分钟)作为键。这个操作员之后是5分钟的翻滚窗口。我们的Kafka输入平均为每分钟300万个事件,在峰值时间大约为每分钟2000万个事件。检查点持续时间和两次检查点之间的最小暂停时间为3分钟。 现在我的疑虑是: 1)keyBy创建的状态是永久保持还是在5分钟后被驱逐。 5)我每
-
将包含3列的CSV文件读入数据流。JAVA Apache Flink
我一直在努力设置一个flink应用程序,该应用程序从csv文件创建。这个文件中的列(列)都是String,但应该将它们转换为Integer、java.sql.time和double。我想要的另一件事是创建包含每天数据的滚动窗口,并对该窗口中列的值进行平均。问题是我不知道它的确切语法。请参阅下面我尝试的代码。最后一部分我有sum(2),但我想计算窗口的平均值。我在文档中没有看到这方面的函数。我需要为
-
Apache Flink-如何在启动时跳过除最新窗口以外的所有窗口
在Flink有可能吗?如果是的话,那该怎么做呢?
-
无法通过curl请求使用post请求在Flink中提交作业(请求不匹配……)
我试图向运行在Kubernetes集群上的Flink作业管理器发送post请求。当为一个不需要任何命令行参数的类发送/jar/run的post请求时,它工作得很好。但是,当尝试在同一个jar中提交一个不同的类时(这需要命令行参数),会出现以下错误。-: 但是,在传递命令行参数并直接提交作业时,像下面的works-: 然而,这给出了前面提到的错误。我只是想将上面的命令行作业提交转换为一个基于rest
-
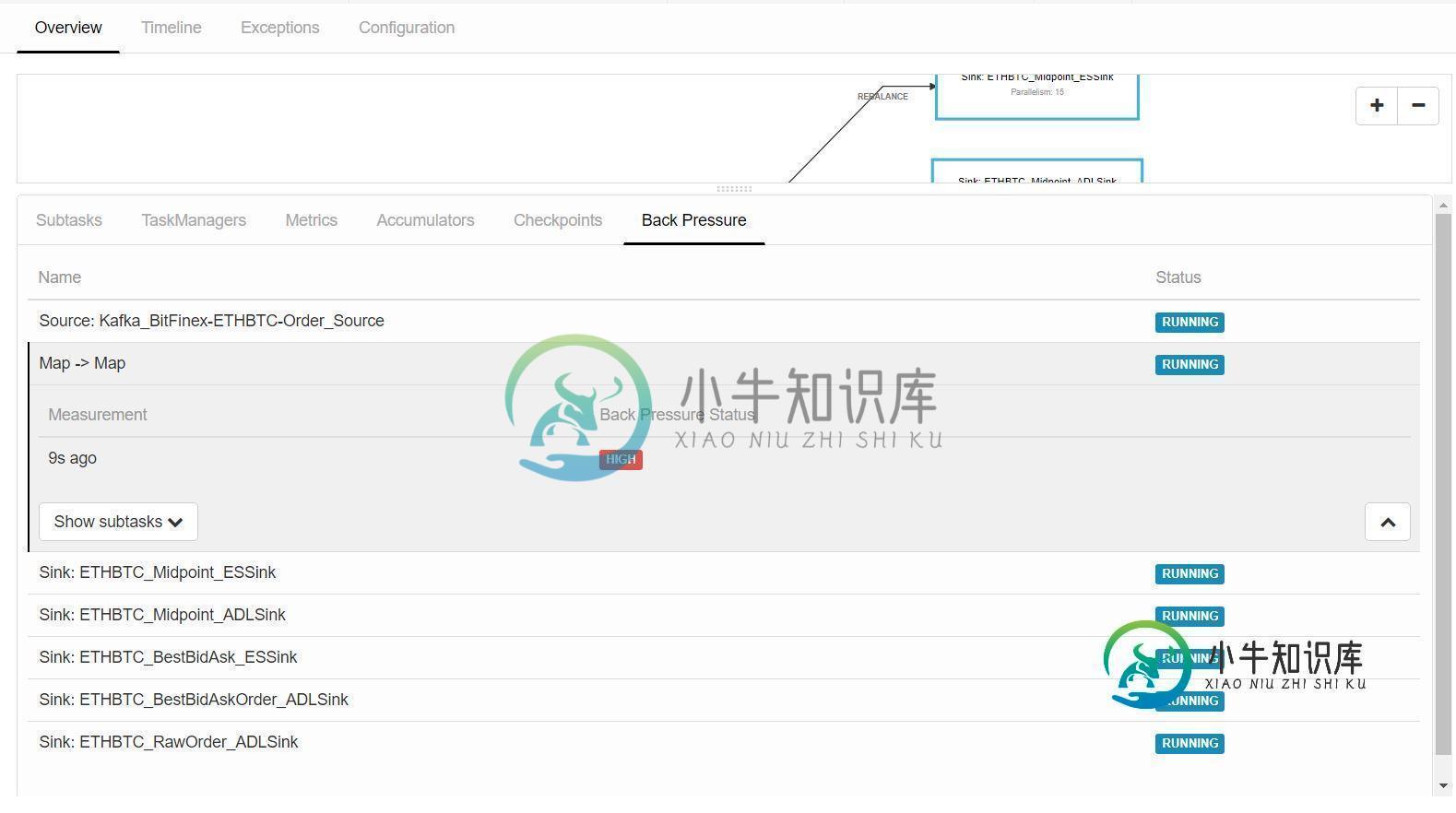 如何处理flink流作业中的背压?
如何处理flink流作业中的背压?我正在运行一个流式flink作业,它消耗来自kafka的流式数据,在flink映射函数中对数据进行一些处理,并将数据写入Azure数据湖和弹性搜索。对于map函数,我使用了1的并行性,因为我需要在作为全局变量维护的数据列表上逐个处理传入的数据。现在,当我运行该作业时,当flink开始从kafka获取流数据时,它的背压在map函数中变得很高。有什么设置或配置我可以做以避免背压在闪烁?