
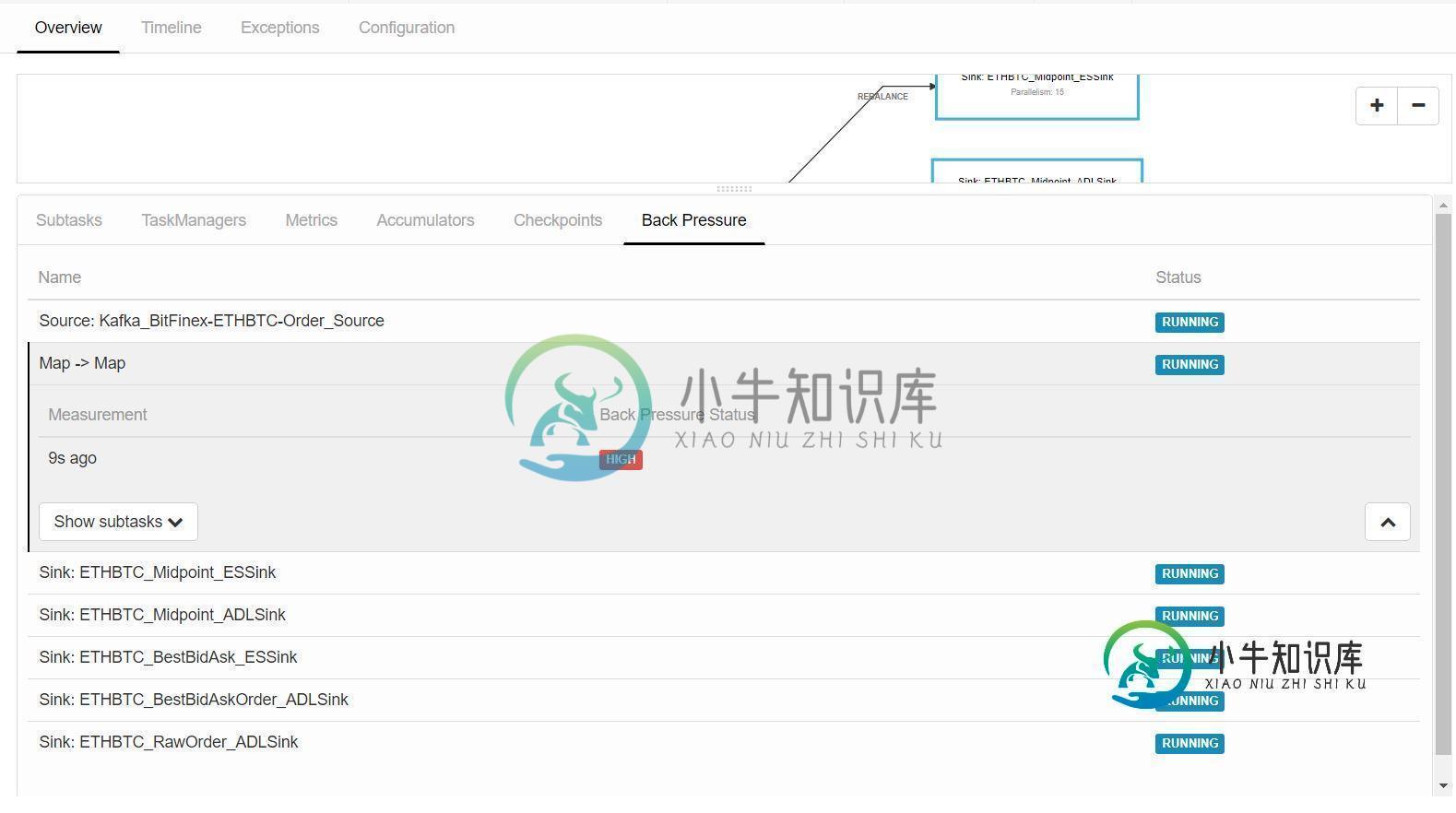
如何处理flink流作业中的背压?

我正在运行一个流式flink作业,它消耗来自kafka的流式数据,在flink映射函数中对数据进行一些处理,并将数据写入Azure数据湖和弹性搜索。对于map函数,我使用了1的并行性,因为我需要在作为全局变量维护的数据列表上逐个处理传入的数据。现在,当我运行该作业时,当flink开始从kafka获取流数据时,它的背压在map函数中变得很高。有什么设置或配置我可以做以避免背压在闪烁?
共有1个答案

给定运算符上的背压表明下一个运算符正在缓慢地消耗元素。从你的描述看来,其中一个水槽的性能很差。考虑放大接收器,为故障排除的目的注释接收器,和/或调查您是否达到了Azure速率限制。
-
null 其中lambda1、2等是条件检查函数,例如 但不知什么原因对我不起作用,也许还有其他方法?正如我从文档(https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/side_output.html)中了解到的,OutputTag用于创建标记为tag的附加消息。还是我错了?
-
我有一个java应用程序,它对通过查询数据库中的表获得的批进行flink批处理,并将其输入kafka主题。我将如何定期安排这项工作。有flink调度程序吗?例如,我的java应用程序应该在后台持续运行,flink调度程序应该定期从数据库查询表,flink批处理它并将其输入kafka(flink批操作和输入Kafca已经在我的应用程序中完成了)。如果有人有这方面的建议,请帮忙。
-
我们正在努力计算 1 分钟翻滚时间窗口内不同类型的事件的最大并发计数。 这些事件就像传感器数据,这些数据是从我们的桌面代理每分钟收集的,然而,一些代理得到了一个错误的时间戳,比如说,它甚至比现在晚了几个小时。 所以,我的问题是如何处理/删除这些事件,目前我只是应用过滤器(s = 我的第一个问题是,如果我不这样做,我怀疑这个坏的“未来”事件会触发窗口计算,即使是那些不完整的数据窗口 第二个问题是,我
-
我想在一个操作符中接收和处理三个流。例如,Storm中实现的代码如下: <代码>生成器。setBolt(“C\u螺栓”,C\u螺栓(),parallelism\u提示)。字段分组(“A\u bolt”,“TRAINING”,新字段(“word”))。字段分组(“B\U螺栓”,“分析”,新字段(“word”))。所有分组(“A\U螺栓”、“总和”) 在Flink中,实现了和的处理: 但我不知道如何添
-
我正在尝试为Flink流媒体作业创建JUnit测试,该作业将数据写入kafka主题,并分别使用和从同一kafka主题读取数据。我正在通过生产中的测试数据: 以及检查来自消费者的数据是否与以下数据相同: 使用。 通过打印流,我能够看到来自消费者的数据。但无法获得Junit测试结果,因为即使消息完成,使用者仍将继续运行。所以它并没有来测试这个部件。 在或中是否有任何方法停止进程或运行特定时间?
-
我有一个瞬移工作,接受Kafka的主题,通过一堆操作员。我想知道什么是最好的方法来处理中间发生的异常。 假设存在异常,使用并在catch块中输出到,并在调用外部服务以更新另一个相关作业状态的末尾为提供单独的接收器函数 但是,我的问题是,通过这样做,我似乎仍然需要调用并传入一个空值,以便继续到下面的运算符并进入最后一个阶段,在这个阶段,将流入单独的接收器函数。这样做对吗? 另外,我不确定如果不在操作