《flink》专题
-
Apache Flink-连接流顺序和背压
下面的相同代码显示了两个源函数-一个产生0-20的偶数,另一个产生1-20的奇数,连接在一起以输出所有两个流的并集并将它们打印出来。 示例代码: 输出 Q1. Flink应该将连接流中最先到达的项目发送到协处理函数。然而,我们在这里看到的是,数字“2”是以源函数的方式在数字“11”之前生成的,但数字“11”是在“2”之前发送给协处理函数的。为什么会这样? 第二季度。 连接流中无背压发生。源函数一直
-
如何在apache flink中加入两个流?
我开始使用flink,看看官方教程之一。 据我所知,这个练习的目标是在时间属性上加入两个流。 任务: 此练习的结果是一个Tuple2记录的数据流,每个记录对应一个不同的rideId。您应该忽略结束事件,只在每次骑乘开始时加入事件,并提供相应的票价数据。 生成的流应打印到标准输出。 问:EnrichmentFunction如何连接这两个流aka。它如何知道参加哪个集市和哪个骑行?我希望它能够缓冲多个
-
当processElement依赖于广播的数据时,如何在flink中单元测试BroadcastProcessFunction
我用BroadcastProcessFunction实现了一个flink流。从processBroadcastElement获取模型,并将其应用于processElement中的事件。 我没有找到对流进行单元测试的方法,因为我没有找到确保在第一个事件之前调度模型的解决方案。我想说有两种方法可以实现这一点: 1。找到一个解决方案,首先在流中推送模型。在流的执行之前,使用模型填充广播状态,以便恢复流
-
初始化Flink作业
我们正在部署一个新的Flink流处理作业,它的状态(存储)需要使用历史数据进行初始化,并且在开始处理任何新的应用程序事件之前,该数据应该在状态存储中可用。我们不想显着修改Flink作业以同时加载历史数据。我们考虑编写另一个单独的Flink作业来处理历史数据,更新其状态存储并创建一个Savepoint并使用此Savepoint在主Flink作业中初始化状态。看起来状态处理器API仅适用于DataSe
-
是否可以在需要时调用Flink Map(在输入流上未激活)
我有一个闪烁的地图,一旦数据通过流就会被激活。 即使没有数据通过,我也要调用该地图。 我将map移动到一个函数中(无限函数调用),但是flink作业永远不会运行。如果我将其添加到map中,它只会在数据通过时被激活。 想法是,在一个infinte循环中有一个map,检查一些共享变量和另一个闪烁流监控kafka队列,如果数据进入它的过程,它会更改一个共享变量,以某种方式影响无限循环并继续。 如何调用无
-
Flink将SingleOutputStreamOP写入两个文件而不是一个
我正在为工作中的一个项目尝试闪烁。我已经到了通过应用计数窗口等来处理流的地步。然而,我注意到一个特殊的行为,我无法解释。 看起来一个流是由两个线程处理的,输出也是分成两部分的。 首先,我注意到使用将流打印到标准控制台时的行为。 然后,我打印到一个文件,它实际上正在输出文件夹中的两个名为1和2的文件中打印。 有人能解释一下为什么Flink会有这种行为吗?如何配置它?为什么有必要对结果流进行拆分? 并
-
为什么我的flink程序没有加入两条流?
我想根据id加入Customer和Address对象。这些是我对kafka stream for Customer主题的输入 和以下fro地址 我使用了间隔连接以及使用TumblingEventTimeWindows和滑动窗口的JoinFunction,但它没有连接客户和地址流。我不明白我在代码中遗漏了什么。
-
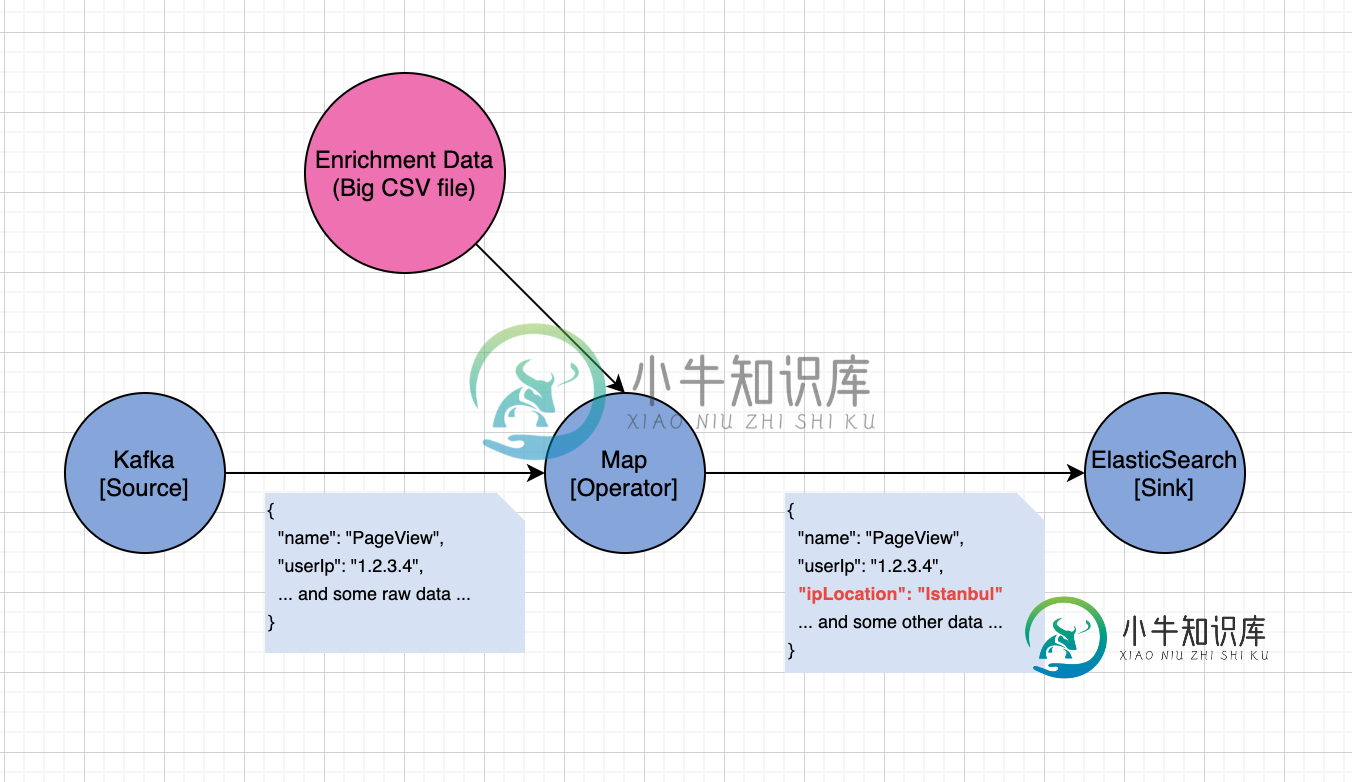 如何在Apache Flink中使用大文件丰富事件流?
如何在Apache Flink中使用大文件丰富事件流?我有一个用于点击流收集和处理的Flink应用程序。该应用程序由Kafka作为事件源、一个map函数和一个接收器组成,如下图所示: 我想根据从Kafka摄取的原始事件中的userIp字段,使用用户的IP位置来丰富传入的点击流数据。 CSV文件的简化切片,如下所示 我做了一些研究,发现了一些潜在的解决方案: 1.解决方案:广播浓缩数据,用一些IP匹配逻辑连接事件流。 结果:它适用于几个示例IP位置数据
-
Kafka·Flink:Kafka制作人错误取决于Flink作业
当我与Kafka·Flink一起进行概念验证时,我发现了以下几点:似乎Kafka制作人的错误可能会由于Flink方面的工作量而发生?! 以下是更多细节: 我有样本文件,如样本??。EDR由约700000行组成,具有“实体”、“值”、“时间戳”等值 我使用以下命令创建kafka主题: 我使用以下命令加载主题的示例文件: 我有一些在flink方面的工作,这些工作通过6小时和72小时的滑动窗口为每个实体
-
Apache Flink Kafka集成
我正在尝试将Apache Kafka 2.11-0.10.0.0与Apache Flink 1.1.2集成。我正在使用scalashell来测试它,我得到了以下错误。 类别组织。阿帕奇。Flink。流式处理。api。检查点。未找到检查点通知程序 我已经添加了组织。阿帕奇。Flink。将jar流式传输到类路径,但这没有帮助。我一直导入到org。阿帕奇。Flink。流式处理。api。检查点。\u。这仍
-
在运行时优雅地关闭Flink Kafka Comsumer
我正在将FlinkKafkaConsumer010与Flink 1.2.0一起使用,我面临的问题是:如果出现某种情况,是否有办法通过编程关闭整个管道? 一种可能的解决方案是,我可以通过调用FlinkKafkaConsumer010中定义的close()方法关闭kafka消费源,然后调用带有shutdown的管道。对于这种方法,我创建了一个列表,其中包含对所有FlinkKafkaConsumer01
-
Flink流未完成
我正在使用kafka和elasticsearch设置flink流处理器。我想重播我的数据,但当我将并行度设置为1以上时,它不会完成程序,我认为这是因为Kafka流只看到一条消息,将其标识为流的结尾。 有没有办法告诉flink消费群中的所有线程在一个线程完成后立即结束?
-
如何扩展一个占用大量话题的Flink工作
设置: Flink版本1.12 在纱线上展开 编程语言:Scala Flink作业: > 两个输入kafka主题和一个输出kafka主题 输入1:是一个巨大的主题,每秒有300K到500K条消息。每条消息有600个字段。 Input2:是一个关于每天一次每秒20K条消息的小话题。每条消息有22个字段。 目标是用Input2丰富Input1,输出是一个Kafka主题,其中每条消息都有来自Input1
-
动态限制flink kafka源
我们正在使用多个Kafka主题,但希望优先考虑其中一些主题(~服务质量)。 根据我在网上找到的,共识是不要限制运算符,而是限制源,更具体地说是反序列化器[1]。 我们如何访问源中有关流媒体环境状态的信息(即主题落后于当前偏移量的程度)。 目前,我们计划将我们的整个设置转换为CoFlatMaps[2],并拥有一个控制流,该控制流为所有主题发出当前偏移滞后-低优先级流运算符,然后根据高优先级流的滞后H
-
使用onTimer和Process Element的Apache Flink超时
我使用Apache Flink processElement1、processElement2和onTimer流设计模式来实现超时用例。我观察到,当我加入超时功能时,系统的吞吐量下降了几个数量级。 关于Flink中onTimer内部实现的任何提示:是每个密钥流一个线程(不太可能),还是池/单执行线程连续轮询缓冲回调并拾取超时回调以执行。 据我所知,Flink基于参与者模型和反应模式(AKKA),它