《flink》专题
-
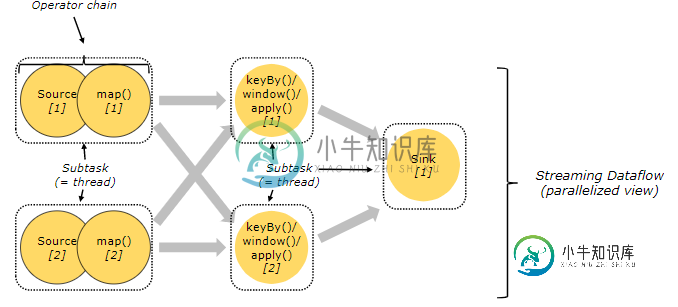 如何知道在Apache Flink中可以链接哪些操作符
如何知道在Apache Flink中可以链接哪些操作符我正在阅读Apache Flink的文档:https://ci.apache.org/projects/flink/flink-docs-stable/concepts/runtime.html. 正如医生提到的, 对于分布式执行,Flink将运算符子任务链接到任务中。每个任务都由一个线程执行。将运算符链接到任务中是一种有用的优化:它减少了线程到线程切换和缓冲的开销,并在减少延迟的同时提高了整体吞
-
Flink流:TriggerResult之间的不同。火灾和触发结果。FIRE\u和\u PURGE
我是Flink的新手。我有一个Flink流媒体程序,在10秒的会话窗口中计算Kafka的内容。 以下是我的问题: 会话windows的默认触发器为FIRE。 Flink streaming是否会将每个窗口的所有Kafka消息保留在内存中?或者只保留聚合结果。 如果使用FIRE\u和\u PURGE,将清除什么?
-
何时清理flink检查点文件?
我有一份流媒体工作: 读Kafka-- 启动时,一切都很好。问题是,过了一段时间,磁盘空间被我认为是链接检查点的东西填满了。 我的问题是,在链接作业运行时是否应该清除/删除检查点?找不到此上的任何资源。 我使用的是写入/tmp的文件系统后端(无hdfs设置)
-
从检查点还原Apache Flink作业
我正在使用Apache Flink RabbitMQ堆栈。我知道有机会手动触发保存点并从中还原作业,但问题是Flink会在成功的检查点之后确认消息,如果要使保存点和还原状态为,则会丢失上次成功的保存点和上次成功的检查点之间的所有数据。有没有办法从检查点恢复作业?这将解决在不可重放数据源(如rabbitmq)的情况下丢失数据的问题。顺便说一句,如果我们有检查点及其所有开销,为什么不让用户使用它们呢?
-
如何使用api rest传递flink流作为参数并返回转换后的流
我是阿帕奇·Flink的新手。我有一个flink scala项目,它使用来自kafka集群的数据,我需要将流结果作为参数传递,以使用返回此转换流的api。这是我的密码 有什么帮助吗?
-
除了使用他们的仪表板,如何提交flink作业?
我已经编写了使用数据集和数据流api的flink作业。我已经从相同的main()方法启动了两个程序,但是现在当我将作业提交给flink Dashboard时。只有数据集api程序正在运行,仪表板说作业完成,流没有被触发,flink仪表板也没有显示任何关于数据流执行的信息。但是当我从eclipse运行时,数据集和datastream api程序都在运行。有没有其他方法将作业提交给flink作业管理器
-
 优化flink窗口
优化flink窗口我有一份flink工作,需要在1小时内重复删除收到的记录。重复数据消除后,我需要收集所有这些重复数据消除的文档,并进行一些聚合,如计数,然后生成目标主题。 现在,由于我只需要收集那些重复数据消除的文档,所以可能不需要等待1小时。我如何避免仅为收集这些文档而设置1个小时的窗口,但一旦收集到这些文档,就继续进行聚合。 因此,资源会占用内存,检查点大小也在增加,这是我想要避免的。 水印策略: 如有任何建
-
Apache Flink中的多流迭代
我的问题是关于Apache Flink中多个流上的迭代。 我是Flink的初学者,目前正在尝试对Flink执行递归查询(例如,数据日志)。 例如,查询每5分钟计算一次传递闭包(滚动窗口)。如果我有一个输入流inputStream(由初始边缘信息组成),另一个由inputStream初始化的输出流(传递闭包)。我想通过加入inputStream来迭代地丰富outputStream。对于每个迭代,反馈
-
流式数据上Flink的全局聚合
我目前正在使用Flink 1.0编写一个聚合用例,作为该用例的一部分,我需要获得过去10分钟内登录的api数量。 这我可以很容易地使用keyBy("api"),然后应用10分钟的窗口和doe sum(count)操作。 但问题是我的数据可能会出现混乱,所以我需要一些方法来获取10分钟窗口内的api计数。。 例如:如果相同的api日志出现在两个不同的窗口中,我应该得到一个全局计数,即2,而不是两个单
-
使用Flink同步处理2个流
我有两个流A和B。 我开始同时吃A和B。 流A仅在每分钟的第59秒获得记录。 流B在每分钟的任何一秒都有记录。 我希望处理使两个流同步。 示例:在10:01:59之后从流A中,我将在10:02:59收到一条记录,直到10:02:59,我也不想从流B中读取任何内容。 这可以在Flink中实现吗?
-
处理Flink ConnectedStream中的“状态刷新”
我们正在构建一个具有两个流的应用程序: 大量信息流 我们希望连接这两个流以获得共享状态,以便第一个流可以使用第二个状态进行扩展。 每天左右,拼花文件(第二流的源代码)都会更新,这需要我们清除第二流的状态并重建它(可能需要大约2分钟)。 问题是,我们可以在该进程运行时阻止/延迟来自第一流的消息吗? 谢谢。
-
Flink:使用CSV文件的事件时间聚合
我将Flink 1.11.3与SQL API和Blink planner结合使用。我在流模式下工作,使用带有文件系统连接器和CSV格式的CSV文件。对于一个时间列,我生成水印,并希望根据这个时间进行窗口聚合。就像根据事件时间快进过去一样。 是否必须为此对时间列进行排序,因为逐行使用时间列,如果不进行排序,可能会发生延迟事件,从而导致行的删除? 我对Ververica的CDC连接器也很感兴趣。也许我
-
使用Flink和基于事件时间的流计算平均值
我想用基于历史事件的流计算Flink中基于窗口的平均值(或我定义的任何其他函数),因此流必须是事件时间(而不是基于处理时间): 我已经了解了如何在摄入时添加时间戳: 但是当我进行计算(应用函数)时,当我只是以与没有EventTime时相同的方式进行计算时,它就不起作用了。我读过一些关于我必须设置的水印的东西: 有没有人举一个简单的Scala例子? 尊敬的安德烈亚斯
-
我的Flink应用程序需要水印吗?如果没有,我是否需要水印策略。noWatermarks?
我不确定我的Flink应用程序是否需要水印。什么时候有必要? 如果我不需要它们,水印策略的目的是什么。noWatermarks()?
-
Flink按字段id对记录进行分组的最佳方法
我正在和Kafka经纪人联系阿帕奇·Flink。 我随机收到了以下消息: 消息(时间戳=[…],索引=1,someData=[…]) 消息(时间戳=[…],索引=2,someData=[…]) 消息(时间戳=[…],索引=3,某些数据=[…]) 消息(时间戳=[…],索引=2,someData=[…]) 消息(时间戳=[…],索引=3,某些数据=[…]) 消息(时间戳=[…],索引=1,someD