
如何在Apache Flink中使用大文件丰富事件流?

我有一个用于点击流收集和处理的Flink应用程序。该应用程序由Kafka作为事件源、一个html" target="_blank">map函数和一个接收器组成,如下图所示:
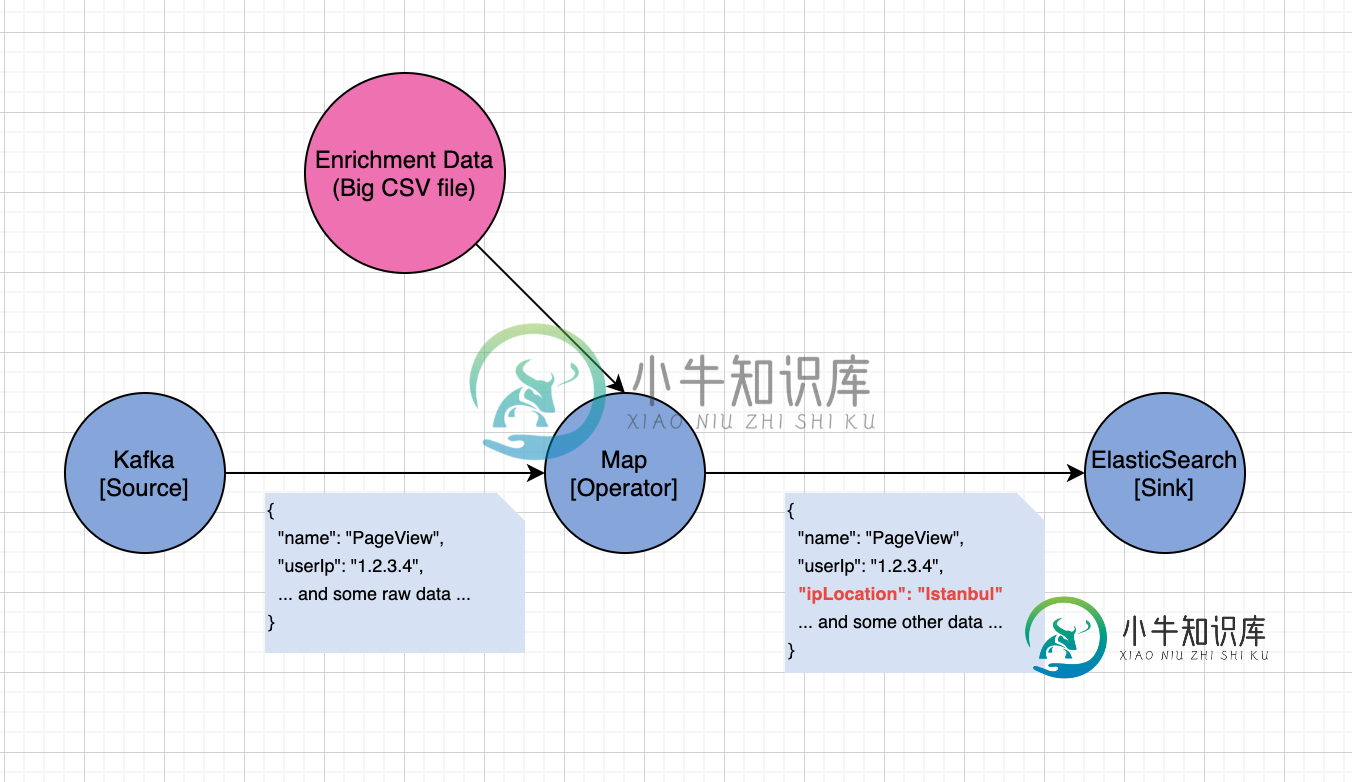
我想根据从Kafka摄取的原始事件中的userIp字段,使用用户的IP位置来丰富传入的点击流数据。
CSV文件的简化切片,如下所示
start_ip,end_ip,country
"1.1.1.1","100.100.100.100","United States of America"
"100.100.100.101","200.200.200.200","China"
我做了一些研究,发现了一些潜在的解决方案:
1.解决方案:广播浓缩数据,用一些IP匹配逻辑连接事件流。
结果:它适用于几个示例IP位置数据,但不适用于整个CSV数据。JVM堆已达到3.5 GB,由于广播状态,无法将广播状态放入磁盘(对于RocksDb)
2、解决方案:在开始事件处理之前,将RichFlatMapFunction中的open()方法中的CSV数据加载到状态(ValueState),并在flatMap方法中丰富事件数据。
结果:由于扩展数据太大,无法存储在JVM堆中,因此无法加载到ValueState。而且,对于键值性质的数据,通过ValueState进行反序列化也是一种不好的做法。
3.解决方案:为了避免处理JVM堆约束,我尝试将富集数据作为MapState的状态放入RocksDB(使用磁盘)中。
3、结果:试图在open()方法中将CSV文件加载到MapState中,给了我一个错误,告诉我不能在open()方法中放入MapState,因为我不在open()方法中的键控上下文中,如以下问题:Flink键控流键为null
4.解决方案:由于需要MapState的键控上下文(放入RocksDB),我在将DataStream放入KeyedStream后,尝试将整个CSV文件加载到进程函数中的本地RocksDB实例(磁盘)中:
class KeyedIpProcess extends KeyedProcessFunction[Long, Event, Event] {
var ipMapState: MapState[String, String] = _
var csvFinishedFlag: ValueState[Boolean] = _
override def processElement(event: Event,
ctx: KeyedProcessFunction[Long, Event, Event]#Context,
out: Collector[Event]): Unit = {
val ipDescriptor = new MapStateDescriptor[String, String]("ipMapState", classOf[String], classOf[String])
val csvFinishedDescriptor = new ValueStateDescriptor[Boolean]("csvFinished", classOf[Boolean])
ipMapState = getRuntimeContext.getMapState(ipDescriptor)
csvFinishedFlag = getRuntimeContext.getState(csvFinishedDescriptor)
if (!csvFinishedFlag.value()) {
val csv = new CSVParser(defaultCSVFormat)
val fileSource = Source.fromFile("/tmp/ip.csv", "UTF-8")
for (row <- fileSource.getLines()) {
val Some(List(start, end, country)) = csv.parseLine(row)
ipMapState.put(start, country)
}
fileSource.close()
csvFinishedFlag.update(true)
}
out.collect {
if (ipMapState.contains(event.userIp)) {
val details = ipMapState.get(event.userIp)
event.copy(data =
event.data.copy(
ipLocation = Some(details.country)
))
} else {
event
}
}
}
}
4.结果:太hacky,由于阻止文件读取操作而阻止事件处理。
你能告诉我这种情况我能做些什么吗?
谢谢
共有1个答案

您可以做的是实现一个自定义分区器,并将一部分丰富数据加载到每个分区中。这里有一个这种方法的示例;我将摘录一些关键部分:
工作是这样组织的:
java prettyprint-override">DataStream<SensorMeasurement> measurements = env.addSource(new SensorMeasurementSource(100_000));
DataStream<EnrichedMeasurements> enrichedMeasurements = measurements
.partitionCustom(new SensorIdPartitioner(), measurement -> measurement.getSensorId())
.flatMap(new EnrichmentFunctionWithPartitionedPreloading());
自定义分区器需要知道有多少个分区,并确定地将每个事件分配给特定的分区:
private static class SensorIdPartitioner implements Partitioner<Long> {
@Override
public int partition(final Long sensorMeasurement, final int numPartitions) {
return Math.toIntExact(sensorMeasurement % numPartitions);
}
}
然后,富集函数利用知道分区是如何完成的来仅将相关切片加载到每个实例中:
public class EnrichmentFunctionWithPartitionedPreloading extends RichFlatMapFunction<SensorMeasurement, EnrichedMeasurements> {
private Map<Long, SensorReferenceData> referenceData;
@Override
public void open(final Configuration parameters) throws Exception {
super.open(parameters);
referenceData = loadReferenceData(getRuntimeContext().getIndexOfThisSubtask(), getRuntimeContext().getNumberOfParallelSubtasks());
}
@Override
public void flatMap(
final SensorMeasurement sensorMeasurement,
final Collector<EnrichedMeasurements> collector) throws Exception {
SensorReferenceData sensorReferenceData = referenceData.get(sensorMeasurement.getSensorId());
collector.collect(new EnrichedMeasurements(sensorMeasurement, sensorReferenceData));
}
private Map<Long, SensorReferenceData> loadReferenceData(
final int partition,
final int numPartitions) {
SensorReferenceDataClient client = new SensorReferenceDataClient();
return client.getSensorReferenceDataForPartition(partition, numPartitions);
}
}
请注意,富集不是在键控流上完成的,因此您不能在富集函数中使用键控状态或计时器。
-
我只找到TextInputFormat和CsvInputFormat。那么,如何使用ApacheFlink读取HDFS中的拼花文件呢?
-
问题内容: 我正在研究python和selenium。我想使用selenium从单击事件中下载文件。我写了下面的代码。 我想从给定的URL从名称为“导出数据”的链接下载两个文件。我如何实现它,因为它仅适用于click事件? 问题答案: 使用查找链接,然后调用方法。 添加了配置文件处理代码,以防止出现下载对话框。
-
要表现色彩里的浓烈、富足感可藉由组合一个有力的色彩和它暗下来的补色。例如,深白兰地酒红色就是在红色中加了黑色,就像产自法国葡萄园里陈年纯美的葡萄酒,象征财富。白兰地酒红色和深森林绿如果和金色一起使用可表现富裕。这些深色、华丽的色彩用在各式各样的织料上,如皮革和波纹皱丝等等,可创造出戏剧性、难以忘怀的效果。这些色彩会给人一种财富和地位的感觉。 补色色彩组合 原色色彩组合 单色色彩组合 49 3 49
-
我正在实现RESTful服务(使用CXFRS组件),它应该为某些请求返回文件。每个文件都是通过其id和扩展名获取的,即。每个文件一旦添加就不会更改。文件在获取后不应移动或删除,通常它们应该可以同时访问。这是我的Camel上下文的一部分: 此配置的问题是,响应只有第二个非空主体(为什么?)请求,无超时设置服务在第二个请求时进入永恒循环,并显示调试消息 Apace Camel版本为2.10.4 任何帮
-
我有一条骆驼路线,根据一些id进行拆分和聚合。当检索到一个id时,调用另一个endpoint来根据这个id检索项目信息。在检索项目信息之后,我必须通过调用多个enrich()方法来丰富它。在第一个enrich方法中,我必须做一些xpath处理,其中我将能够检索一个primaryOrgId值,我将在交换中将其设置为属性,不要担心xpath处理,我已经解决了这个问题,但我的问题是当我在第一个enric
-
所以我必须检索存储在HDFS中的文件的内容,并对其进行某些分析。 问题是,我甚至无法读取文件并将其内容写入本地文件系统中的另一个文本文件。(我是Flink的新手,这只是一个测试,以确保我正确读取了文件) HDFS中的文件是纯文本文件。这是我的密码: 在我运行/tmp之后,它没有输出。 这是一个非常简单的代码,我不确定它是否有问题,或者我只是做了一些别的错误。正如我所说,我对Flink完全是新手 此