《flink》专题
-
为什么flink无法从保存点恢复
版本flink 1.7 我正在尝试从保存点(或检查点)还原flink作业,该作业所做的是读取kafka的内容- 我使用rocksdb和启用的检查点。 现在我尝试手动触发一个保存点。每个聚合的预期值为30(1个数据/每分钟)。但是当我从保存点(flink run-d-s{url})恢复时,聚合值不是30(小于30,取决于我取消flink作业和恢复的时间)。当作业正常运行时,它得到30。 我不知道为什
-
如果Flink作业在两个检查点之间重新启动,会发生什么情况?
这个问题与这里提出的问题基本相似:Apache Flink容错。i、 e.如果作业在两个检查点之间重新启动,会发生什么情况?它会重新处理在最后一个检查点之后已经处理过的记录吗? 例如,我有两份工作,工作1和工作2。Job1使用来自Kafka的记录,对其进行处理,然后再次将其生成到第二个Kafka主题。Job2使用第二个主题并处理记录(在我的例子中,它使用AerospikeClient更新aeros
-
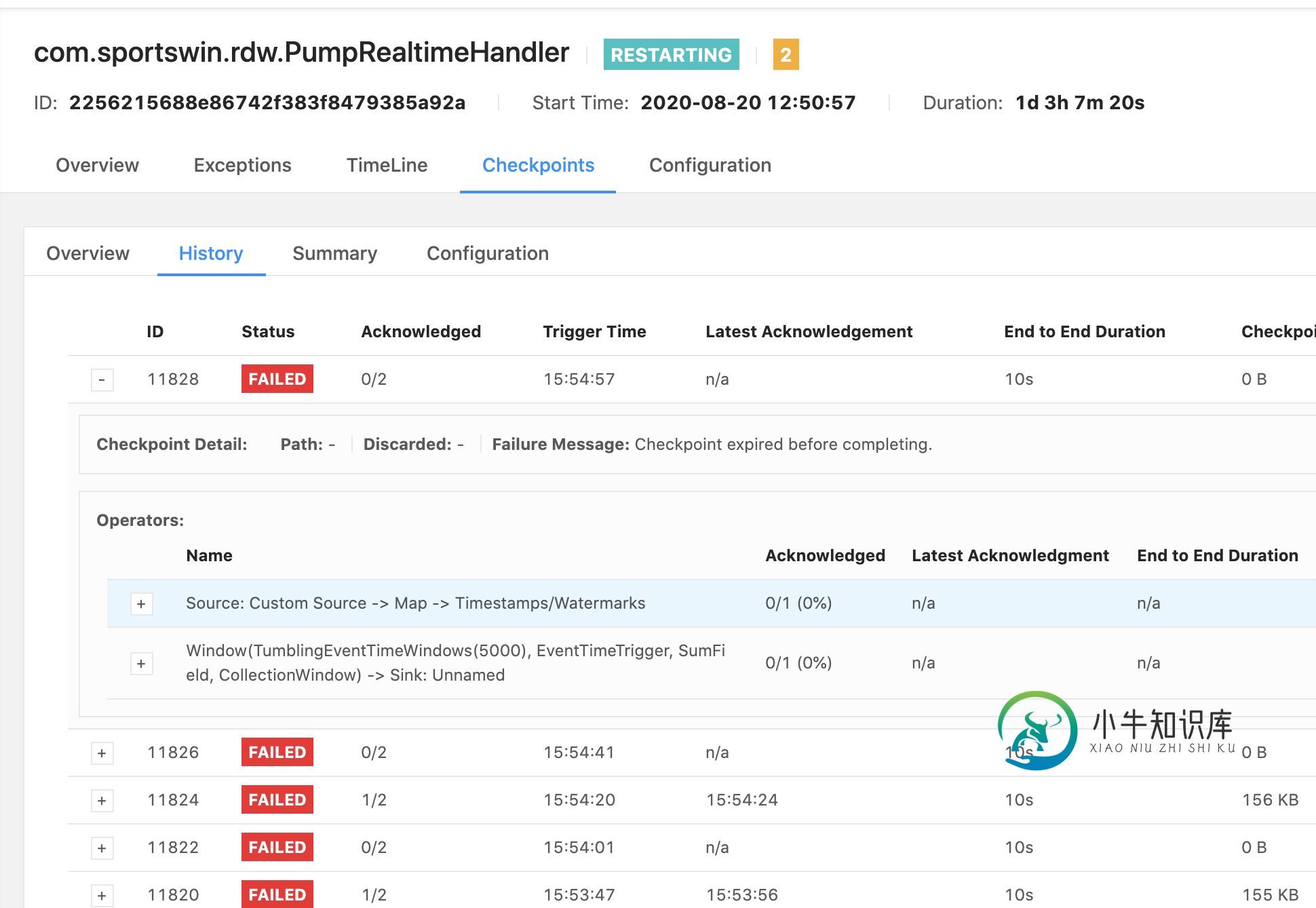 失败消息:使用apache flink 1.11时,检查点在完成之前已过期
失败消息:使用apache flink 1.11时,检查点在完成之前已过期我最近在kubernetes集群中将我的Apache Flink升级到1.11版,但今天我发现一个任务检查点总是失败。此任务从RabbitMQ读取数据并计算结果并调用HTTP请求将数据保存到MySQL。这是任务管理器错误日志输出: 这是Apache FlinkUI错误消息: 工作总是在一段时间内重新启动。我有2个任务,另一个任务检查点保持成功。那么问题出在哪里,我应该怎么做才能解决这个问题? 这是
-
代码更改后从状态恢复Flink作业
我使用Apache Flink 1.9和标准检查点/保存点机制来FS。 我的问题是:如果作业的代码发生了更改,从保存点恢复作业的正确方法是什么?例如,在重构之后,我重命名了几个类,之后我无法从旧的检查点恢复。 我丢失了我的数据,想问-在这种情况下我能做些什么? 所有运算符都有uid和name
-
数据流API中的Flink迭代-缺点
我们希望将迭代与Async IO运算符结合使用,为同一事件执行顺序API调用。但是,在回答我提出的另一个问题时,有人提到使用Datastreams唱迭代是个坏主意。 管理使用大量内存的状态-从存储中查询 有人能进一步解释一下吗?
-
Apache Flink:REST API检索度量值
我开始了延迟跟踪,并通过了RESTAPI的作业/指标。获得以下信息: <代码>{“id”:“延迟。源代码id。cbc357ccb763df2852fee8c4fc7d55f2。操作员id。e5ebb093256018a0621f548fbe118f8a。操作员子任务\U索引。0。延迟\U p75},{“id”:“lastCheckpointExternalPath”},{“id”:“延迟。源代码i
-
Flink动态表和流连接
我试图从动态表和基于某些字段的流中派生新表。 有没有人能为你提供最好的指导。我对flink和尝试新事物是陌生的。 书籍 ============================ BookId, Instruments, Quantity Book1, Goog,100 Book2, Vod,10 Book1, Appl,50 Book2, Goog,60 Book1, Vod,130 Book3,
-
使用as端输出数据流时,Flink如何处理延迟事件?
在我看来,Flink以三种方式处理后期事件: 窗口过期时删除延迟事件(默认)。 通过使用“允许延迟”机制包含延迟事件来更新窗口。 使用“侧输出”机制将延迟事件重定向到另一个DataStream。 让我们假设我有一个事件时间作业,它使用来自Kafka的数据,并每5分钟处理一个窗口。现在,假设我将延迟事件重定向到另一个数据流中。 这个新的数据流是独立的吗 谢谢大家!
-
如何在Flink中使用ListState进行BroadcastProcessFunction
我们有一个包含事务的非键控数据流和一个包含规则的广播流。事实上,我们希望根据上次看到的规则处理事务。如果我们最后看到的规则是每日,我们必须将当前事务添加到每日事务列表中。此外,如果dailyTrnsList的大小大于阈值,则必须清除列表并将事务写入数据库。如果最后看到的规则是temp,我们也会做同样的事情。 代码如下: 我们的问题是编写一种容错方法。我们不知道如何使用ListState来解决我们的
-
如何访问从外部Flink作业计算的状态?(不知道其id)
我是Flink的新手,目前正在测试用例框架,该用例包含丰富来自Kafka的事务,并具有许多历史特征(例如,相同源和相同目标之间过去的事务数),然后使用机器学习模型对该事务进行评分。 目前,功能都保留在Flink状态中,同一个工作是对丰富的事务进行评分。但是我想将特征计算工作与评分工作分开,我不知道如何做到这一点。 > 我曾想过直接查询RocksDB,但也许有更简单的方法? 对Flink来说,将这项
-
Flink监控:捕获统计数据5分钟以上
我是Flink社区的新成员,我正在尝试进行一项实验研究,以捕获Flink在流数据方面的性能。为此,我试图收集几个小时内运行作业的统计数据。然而,使用Flink的UI,我只能看到过去5分钟的统计数据。我尝试访问Rest API,但它不包含除读/写字节以外的统计数据。 UI中任务度量下提供的度量非常有用,但不会超过5分钟。是否有一种方法可以捕获度量的整个历史记录。
-
如何在Apache Flink正确初始化任务状态?
我正在开发基于Apache Flink的金融反欺诈系统。我需要根据金融交易计算许多不同的总量。我使用Kafka作为流数据源。例如,在平均交易金额计算中,我使用MapState存储总交易计数和每张卡的总金额。存储在Apache Accumulo的聚合数据。我知道Flink中的持久状态,但这不是我需要的。在计算开始之前,有没有办法将初始数据加载到Flink中?是否可以通过使用两个连接的流和来自Accu
-
Flink:无法在另一台机器上创建HDFS保存点
我正在尝试在HDFS中使用Apache Flink 1.2创建一个保存点。我在我机器上的本地集群中运行Flink。HDFS在虚拟机中运行。我设法在Flink Streaming作业中写入HDFS,但保存点不会这样做。我的保存点路径是,我在提交任务之前在UI中指定的。 它给我以下错误消息:(路径无效) 作业内部配置: 我不知道我做错了什么。在工作中,我设法写入HDFS(没有保存点)。因此HDFS不是
-
如何在flink独立安装上执行kerberos身份验证?
我有一个独立的Flink安装,我想在上面运行一个流作业,将数据写入HDFS安装。HDFS安装是Cloudera部署的一部分,需要Kerberos身份验证才能读取和写入HDFS。由于我没有找到关于如何使Flink连接到受Kerberos保护的HDFS的文档,因此我不得不对该过程进行一些有根据的猜测。以下是我目前所做的: > 我为我的用户创建了一个keytab文件 在我的Flink工作中,我添加了以下
-
FlinkKafkaConsumer082汽车。抵消重置设置不起作用?
我有一个Flink流媒体程序,可以读取Kafka主题的数据。在程序中,自动。抵消重置设置为“最小”。在IDE/Intellij IDEA中进行测试时,程序始终可以从主题的开头读取数据。然后,我建立了一个flink/kafka集群,并将一些数据生成kafka主题。我第一次运行流媒体作业时,它可以读取主题开头的数据。但在那之后,我停止了流式处理作业并再次运行它,它将不会读取主题开头的数据。如何使程序始