《flink》专题
-
正在处理Apache Flink限制数据
我正在寻找一种可以限制当前正在处理的数据量的选项。 用例:我正在从Kafka数据流中读取并处理该数据,我想限制正在运行的消息数量。这样做的原因是第三方应用程序的吞吐量。通常这不是问题,但在背压的场景中,由于这些故障,经常会出现故障和应用程序重新启动。
-
Flink 1.15中是否有结合KafkaSource和ThrottleEditor的方法?
关于速率限制/限制Kafka消费者,有很多老话题 如何在flink上使用Ratimiter? 动态油门闪烁Kafka源 等等 但是它们都不能在案例1.15中使用: 不公开 现在它驻留在中 KafkaSource是首选方法 所以,我的问题是,是否有必要将ThrottleEditor与KafkaSource结合起来?
-
当源输入已耗尽时,Flink触发进程功能上的注册计时器
我正在使用Flink流从包括文件在内的多个资源读取输入。我的目标是定期触发一些计算(流转时长),并在到达文件末尾时触发最终结果。我的处理子拓扑如下所示 我的生成器源之一可以是包含有界数据的文件 <代码>例如环境。readFile(inputFormat、filename、FileProcessingMode.PROCESS\u ONCE、interval、typeInfo) 因此,我想知道是否有一
-
Apache Flink TwoInputStreamOP运算符的水印行为
有2个指定了时间戳的数据流和定义如下的水印生成器。 当这两个流在一个操作符中连接时,来自streamA或streamB的最小水印作为连接操作符的水印。 组合B运算符的水印是A或B中的最小值。基于C类元素是否标记为延迟。 但是,由于我们没有附加任何分配给的时间戳,这是否意味着运算符中的任何元素都没有被标记为延迟?因此在C上窗口不会有任何延迟记录被删除? 假设我们将分配的时间戳和水印生成器附加到C,如
-
如何在Apache Flink中实现流的左外连接
我有两条左右流。就在同一时间窗口 左侧流包含元素L1、L2(数字为键) 右流包含元素R1、R3 我想知道如何在Apache Flink中实现LEFT OUTER JOIN,以便处理此窗口时获得的结果如下: L1、R1通过键(1)匹配,L2、R3不匹配。L2包括在内,因为它位于左侧
-
Flink失去了领导者并崩溃
我正在LocalStream环境(嵌入式flink集群)中运行一个流处理应用程序。我成功地使用我的代码处理了几次特定的数据集。我昨天想在对处理逻辑进行一些修改后重新运行应用程序,但是在大约3/4的数据处理方式之后,flink集群似乎无缘无故地崩溃了。查看浓缩日志-我的评论插入尖括号中 第一条信息是关于我的源代码从s3读取数据并将其收集到flink中。 之后,第一个错误产生:https://gith
-
Flink kafka消费者落后
我在Flink的工作中使用Kafka资料来源的信息流,一次阅读50个主题,如下所示: 然后有一些运算符,如:过滤器- 我能获得的最大吞吐量是每秒10k到20k条记录,考虑到源发布了数十万个事件,这相当低,我可以清楚地看到消费者落后于生产者。我甚至试着移除水槽和其他操作员,以确保没有背压,但它仍然是一样的。我正在将我的应用程序部署到Amazon Kinesis data analytics,并尝试了
-
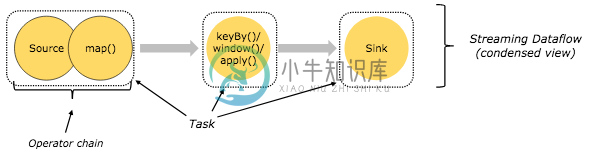 是Apache Flink中的一个任务一个线程
是Apache Flink中的一个任务一个线程我是Flink的新手。据我了解,在Flink中,一个TaskManager可以分成多个插槽,一个插槽可以分配多个任务,一个任务是一个线程。 让我们看看WordCount示例: 据我所知,一个任务就是一个线程,有三个任务:<代码>源映射() ,<代码>keyBy()/窗口()/应用() 和<代码>接收器 。所以每个都有自己的线程,这意味着我们需要三个线程来完成这个示例。我们可以将三个任务(三个线程)
-
在flink中的链式操作符内分配负载
我有一个带有单个碎片的输入动觉流。我创建了一个简单的应用程序,它具有映射函数,但环境级并行度为8。使用线程档案器,当我检查创建的线程时,只有1个线程对map函数和源代码处于活动状态(如文档中所述,查询)。我意识到这是因为我正在环境级别设置并行性。在使用map函数后,是否可以在为其创建的所有并行实例之间分配负载?
-
在Flink中,同一个插槽中是否可以有一个操作符的多个子任务?
几天来,我一直在探索Apache Flink,我对任务槽的概念有些怀疑。虽然有人问了几个问题,但有一点我不明白。 我正在使用一个toy应用程序进行测试,运行一个本地集群。我已禁用操作员链接 我从文档中知道插槽允许内存隔离而不是CPU隔离。阅读文档,任务槽似乎是一个Java线程。 1)当我以并行度=1部署我的应用程序时,所有运算符的子任务都部署在同一个插槽中。但是,如果我从的方法打印当前线程ID,我
-
在Flink,是否可能有多个工人的全球国家?
在Flink文档中的任何地方,我都看到一个状态对map函数和工作人员来说都是单独的。这在独立方法中似乎很强大,但是如果Flink在集群中运行呢?Flink可以处理所有工作人员都可以添加数据并查询它的全局状态吗? 来自Flink关于国家的文章: 为了在此设置中实现高吞吐量和低延迟,必须最小化任务之间的网络通信。在Flink中,流处理的网络通信仅沿作业操作符图中的逻辑边(垂直)进行,因此流数据可以从上
-
Apache Flink:如何更改缓冲区超时参数?
Apache Flink缓冲任务的传出,然后将其发送到下一个任务进行处理。缓冲会影响延迟,而且正如我所知,即使缓冲区没有填满,也会有一个缓冲超时,以便将数据发送到下一个任务。 如何更改缓冲超时?我在留档中找不到任何东西。 配置是每个Flink集群还是每个TaskManager?它可以按任务/运算符配置吗? 据我所知,即使任务在同一个TaskManager上,Flink缓冲区也是如此。在这种情况下,
-
资源过度分配到Flink中的插槽
关于Flink上允许优化集群中资源使用的功能(延迟、吞吐量...),即插槽共享、任务链、异步i/o和动态扩展,我想问以下问题(都在流处理上下文中): > 在哪些情况下,有人会对任务管理器中的槽数高于cpu内核数感兴趣? 在哪种情况下,我们应该在多个插槽上拆分任务管道(禁用插槽共享),而不是增加并行性,以便应用程序跟上传入的数据速率? 是否有可能,即使在使用上述所有功能时,为插槽保留的资源也可能高于
-
Flink KeyedProcessFunction与广播状态
我尝试在我的flink应用程序中使用广播状态模式,但经过一些研究,我做了以下工作: 在中,我读取数据,并根据来自的数据对数据进行一些逻辑处理并发出一些元素。基本上,我使用就像广播状态模式一样。我没有专门使用广播,因为没有简单的方法可以从访问我的某些状态。由于我的配置流被用作清理状态的指示符,我在我的中拥有。 流是<代码>。keyBy所以我不希望出现并行性问题 我的问题是,还需要广播哪些案例?在什么
-
Flink state后端在失败后无法恢复taskmanager
我是flink的新手,我正在实现一个模式识别模块(不使用CEP实现模式匹配),该模块将从EventHub主题读取json流,并在模式匹配的情况下推送到另一个EventHub主题。我的模块功能如下 > 从Eventhub主题接收JSON有效负载 我正在使用RichSourceFunction,它将从API读取模式并发送到广播流 我正在使用Flink BroadcastProcessFunction根