《flink》专题
-
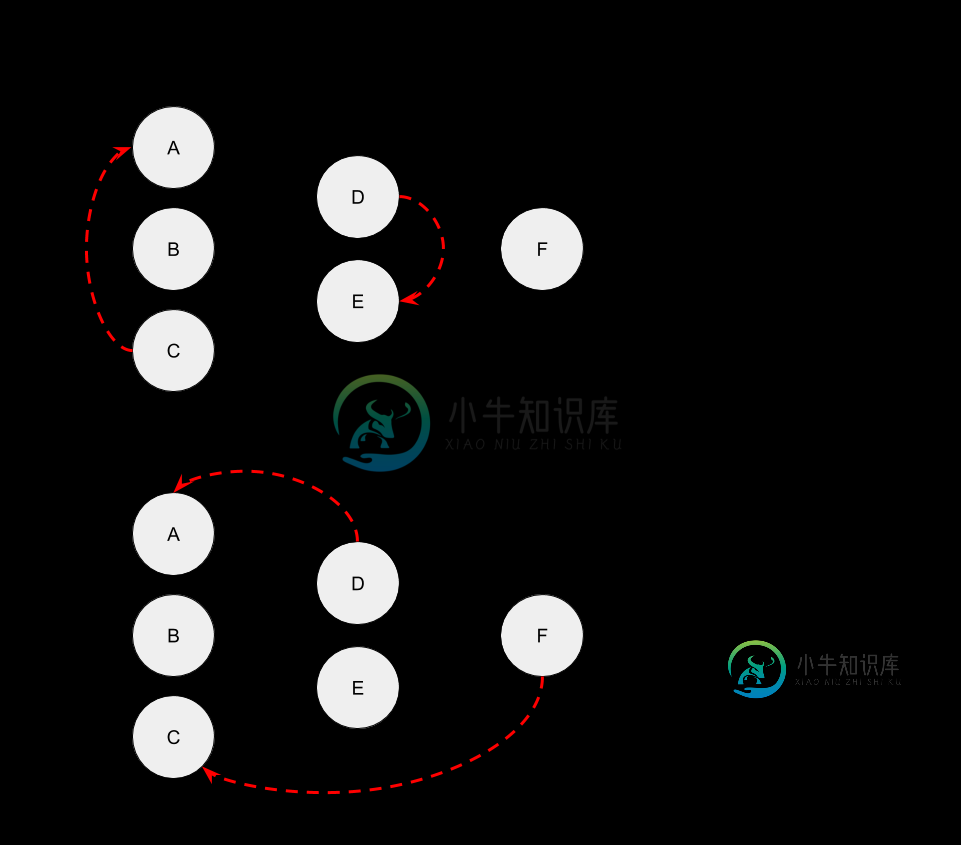 Flink中运营商之间的共享状态
Flink中运营商之间的共享状态我想知道在Flink中是否可以在运营商之间共享状态。 比方说,我在一个操作符上按键进行分区,我需要一个分区的状态(无论出于什么原因)(图1.a),或者我需要下游操作符中操作符的状态(图1.b)。 我知道可以将记录广播到所有分区。因此,如果在记录中包含操作符的内部状态,则可以与下游操作符共享内部状态 然而,这可能是一个昂贵的操作,而不是简单地让op1专门请求op2状态。 可查询状态的最新发展是朝着这
-
Flink Core和Flink CEP在功能方面有什么区别?
在过去几天研究Flink CEP库时,我一直认为它没有为Flink的标准功能添加任何新的基本功能。Flink CEP的唯一目的似乎是通过清晰的语义和直观的代码结构简化事件处理。例如,Flink CEP只提供了5种事件匹配跳过语义。虽然这些语义对于很多情况可能已经足够了,但它可能无法解决具体问题,这让我们回到了普通的Flink。 测试用例是以下模式:
-
查找每个元组的Flink CEP检测延迟
我有一个简单的模式,如下所示 为了找到CEP检测时间的延迟,添加了在如上所示的模式中选择每个事件的时间。每个事件类都有一个参数Edtl(事件检测时间本地),该参数最初设置为0,然后再设置为系统。nanoTime() 我在执行时遇到以下错误,但问题是该错误是在程序运行一段时间后出现的 我想我设置这个模式是因为我在模式中同时进行读取和写入操作。如果是这样,那么我应该如何在Flink CEP中找到平均复
-
是否可以在apache flink CEP中处理多个流?
我的问题是,如果我们有两个原始事件流,即烟雾和温度,并且我们想通过将运算符应用于原始流来找出复杂事件(即火灾)是否发生,我们可以在Flink中做到这一点吗? 我问这个问题是因为到目前为止,我所看到的Flink CEP的所有示例都只包括一个输入流。如果我错了,请纠正我。
-
在执行纱线应用程序终止并再次运行后,flink会从上一个偏移恢复吗?
我使用FlinkKafkaConsumer消费Kafka并启用检查点。现在我对偏移管理和检查点机制有点困惑。我已经知道flink将开始读取消费群体的分区。
-
部署新版本的Flink应用程序失败
环境 Flink1.7.1 Kafka1.0.1 当我用新版本的代码更改应用程序并进行部署时,就会出现应用程序执行失败的问题 如果我部署相同的组。id更改应用程序代码后,是否会与以前的状态检查点信息发生冲突?
-
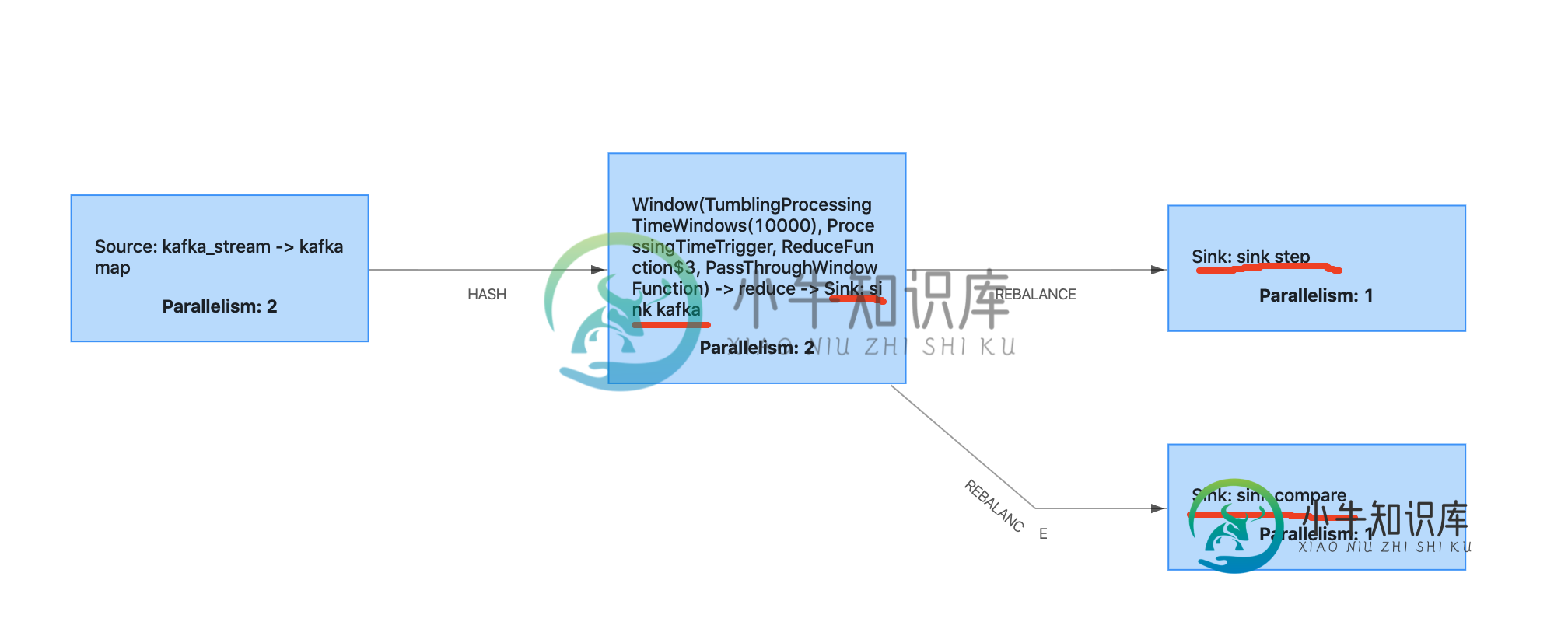 检查点恢复时,flink kafka生产者以仅一次模式发送重复消息
检查点恢复时,flink kafka生产者以仅一次模式发送重复消息我正在写一个测试flink两步提交的案例,下面是概述。 正是曾经的kafka生产者。是mysql接收器扩展。是mysql接收器扩展,这个接收器偶尔会抛出一个exeption来模拟检查点失败。 当检查点失败并恢复时,我发现mysql两步提交可以正常工作,但Kafka消费者会读取上次成功的偏移量,Kafka生产者会生成消息,即使他在检查点失败之前就这样做了。 在这种情况下,如何避免重复消息? 谢谢你的
-
Flink-如何通过JMX Reporter导出Flink的Kafka连接器偏移量?
根据这里的说明,我启用了JMX Exporter,并能够连接到它以查看一些指标:jobmanager。状态,jobmanager。工作 但是,我没有看到KafkaConnector的度量值。我该怎么做? 我想从Flink那里得到那些偏移量来计算 消费者滞后=最新kafka分区偏移量-flink分区偏移量。
-
Flink streaming,“sum”到底是做什么的?
我很难理解流,以workcount为例,对于像Kafka这样的无限源,“sum”到底是做什么的? 我有点理解有时间窗的情况,因为它有开始和结束时间,对我来说就像一个“批次”,但如果没有时间窗, 什么是开始时间和结束时间
-
使用线程在消费流中使用Flink producer in循环运行Flink消费程序
我希望flink consumer stream中的每条消息都能使用flink kafka producer生成多条消息,每条消息都通过一个单独的线程指向Kafka中的某个主题。我正在用Scala编写程序,但用Java就可以了 类似这样: 因此,对于flink消费者中的每个输入,我希望使用多线程向其他队列生成10条消息。
-
Flink流媒体:比较不同窗口的事件
首先,我是流处理框架的新手。我想对其中一些进行基准测试,所以我从Flink开始。 对于我的用例,我需要将窗口t中的事件与窗口t-1中的事件进行比较,两者的大小都是15分钟,然后进行一些聚合。 以下是我的用例的简化版本: 我们将分析的事件视为形式的元组。在窗口1中,我们有:(A,1),(B,2),(C,3),在窗口2中,我们有:(D,6)和(B,7)。然后,我需要将当前窗口中的事件与前一个窗口中的事
-
Flink、Kafka和JDBC水槽
我有一个Flink 1.11作业,它使用来自Kafka主题的消息,键入它们,过滤它们(keyBy后跟自定义ProcessFunction),并通过JDBC接收器将它们保存到db中(如下所述:https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/connectors/jdbc.html) Kafka消费者使用以下选项初始化:
-
我真的需要Flink检查点吗?
我有一个Flink应用程序,它从Kafka中读取一些事件,从MySQL中丰富数据,使用窗口函数缓冲数据,并将窗口内的数据写入HBase。我目前已经启用了检查点,但事实证明,检查点非常昂贵,随着时间的推移,它花费的时间越来越长,并影响我的作业延迟(Kafka摄取率落后)。如果我想办法使HBase写操作幂等,是否有充分的理由使用检查点?我可以将内部kafka消费客户端配置为每隔一段时间提交一次,对吗?
-
Flink RocksDB性能问题
我有一个flink作业(scala),它基本上是从Kafka主题(1.0)读取数据,聚合数据(1分钟事件时间翻转窗口,使用折叠函数,我知道这是不推荐的,但比聚合函数更容易实现),并将结果写入两个不同的Kafka主题。 问题是——当我使用FS状态后端时,一切都运行顺利,检查点需要1-2秒,平均状态大小为200 mb——也就是说,直到状态大小增加(例如,在缩小差距的同时)。 我想我会尝试使用rocks
-
Flink关闭挂钩以最大限度地减少数据丢失/重复
我有一个flink作业,从kafka读取数据,从redis读取一些数据,然后将聚合的窗口数据写入redis接收器(redis写入操作实际上是调用加载到redis中的lua脚本,该脚本会增加现有值,因此我只能在此处增加而不能更新)。 问题是,当我停止作业(维护、代码更改等)时,即使使用保存点,我也会向redis写入重复数据,或者在恢复时丢失一些数据,因为据我所知,redis sink在语义方面没有任