
检查点恢复时,flink kafka生产者以仅一次模式发送重复消息

我正在写一个测试flink两步提交的案例,下面是概述。
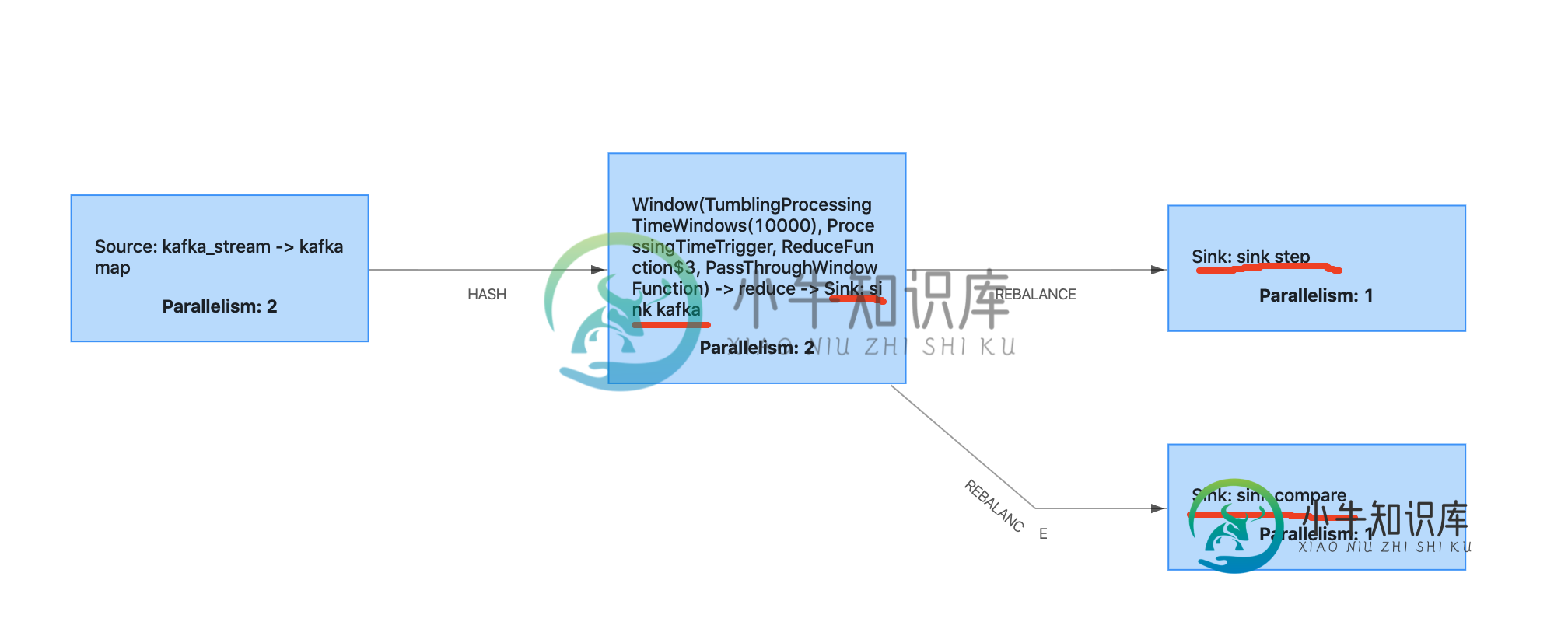
接收器kafka正是曾经的kafka生产者。接收器步骤是mysql接收器扩展两步提交。接收器比较是mysql接收器扩展两步提交,这个接收器偶尔会抛出一个exeption来模拟检查点失败。
当检查点失败并恢复时,我发现mysql两步提交可以正常工作,但Kafka消费者会读取上次成功的偏移量,Kafka生产者会生成消息,即使他在检查点失败之前就这样做了。
在这种情况下,如何避免重复消息?
谢谢你的帮助。
环境:
>
闪烁1.9.1
java 1.8
Kafka2.11
Kafka制作人代码:
dataStreamReduce.addSink(new FlinkKafkaProducer<>(
"flink_output",
new KafkaSerializationSchema<Tuple4<String, String, String, Long>>() {
@Override
public ProducerRecord<byte[], byte[]> serialize(Tuple4<String, String, String, Long> element, @Nullable Long timestamp) {
UUID uuid = UUID.randomUUID();
JSONObject jsonObject = new JSONObject();
jsonObject.put("uuid", uuid.toString());
jsonObject.put("key1", element.f0);
jsonObject.put("key2", element.f1);
jsonObject.put("key3", element.f2);
jsonObject.put("indicate", element.f3);
return new ProducerRecord<>("flink_output", jsonObject.toJSONString().getBytes(StandardCharsets.UTF_8));
}
},
kafkaProps,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
)).name("sink kafka");
检查点设置:
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.enableCheckpointing(10000);
executionEnvironment.getCheckpointConfig().setTolerableCheckpointFailureNumber(0);
executionEnvironment.getCheckpointConfig().setPreferCheckpointForRecovery(true);
mysql接收器:
dataStreamReduce.addSink(
new TwoPhaseCommitSinkFunction<Tuple4<String, String, String, Long>,
Connection, Void>
(new KryoSerializer<>(Connection.class, new ExecutionConfig()), VoidSerializer.INSTANCE) {
int count = 0;
Connection connection;
@Override
protected void invoke(Connection transaction, Tuple4<String, String, String, Long> value, Context context) throws Exception {
if (count > 10) {
throw new Exception("compare test exception.");
}
PreparedStatement ps = transaction.prepareStatement(
" insert into test_two_step_compare(slot_time, key1, key2, key3, indicate) " +
" values(?, ?, ?, ?, ?) " +
" ON DUPLICATE KEY UPDATE indicate = indicate + values(indicate) "
);
ps.setString(1, context.timestamp().toString());
ps.setString(2, value.f0);
ps.setString(3, value.f1);
ps.setString(4, value.f1);
ps.setLong(5, value.f3);
ps.execute();
ps.close();
count += 1;
}
@Override
protected Connection beginTransaction() throws Exception {
LOGGER.error("compare in begin transaction");
try {
if (connection.isClosed()) {
throw new Exception("mysql connection closed");
}
}catch (Exception e) {
LOGGER.error("mysql connection is error: " + e.toString());
LOGGER.error("reconnect mysql connection");
String jdbcURI = "jdbc:mysql://";
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection(jdbcURI);
connection.setAutoCommit(false);
this.connection = connection;
}
return this.connection;
}
@Override
protected void preCommit(Connection transaction) throws Exception {
LOGGER.error("compare in pre Commit");
}
@Override
protected void commit(Connection transaction) {
LOGGER.error("compare in commit");
try {
transaction.commit();
} catch (Exception e) {
LOGGER.error("compare Commit error: " + e.toString());
}
}
@Override
protected void abort(Connection transaction) {
LOGGER.error("compare in abort");
try {
transaction.rollback();
} catch (Exception e) {
LOGGER.error("compare abort error." + e.toString());
}
}
@Override
protected void recoverAndCommit(Connection transaction) {
super.recoverAndCommit(transaction);
LOGGER.error("compare in recover And Commit");
}
@Override
protected void recoverAndAbort(Connection transaction) {
super.recoverAndAbort(transaction);
LOGGER.error("compare in recover And Abort");
}
})
.setParallelism(1).name("sink compare");
共有1个答案

我不太确定我是否正确理解了这个问题:
当检查点失败并恢复时,我发现mysql两步提交可以正常工作,但kafka制作人会读取上次成功的偏移量并产生消息,即使他在此检查点失败之前完成了。
Kafka生产者没有读取任何数据。所以,我假设您的整个管道重新读取旧的偏移量并产生重复。如果是这样,您需要了解Flink如何确保只有一次。
- 创建定期检查点,以便在出现故障时保持一致的状态
对于最后一点,有两个选项:
- 仅在写入检查点时输出数据,这样目标中就不会出现有效的重复项。这种天真的方法非常通用(独立于接收器),但会将检查点间隔添加到延迟中
后一个选项用于Kafka水槽。它使用Kafka事务来消除重复数据。为了避免消费者端的重复,您需要确保它没有读取文档中提到的未提交数据。还要确保事务超时足够大,不会在故障和恢复之间丢弃数据。
-
我正在使用Spring Boot中的。Java 8 我的主要目的是,消费者不应重复使用信息。 1)调用表获取100行并将其发送到kafka 2) 假设我处理了70行(我得到了成功确认),然后Kafka宕机了(Kafka在RETRY机制计时内无法恢复) 因此,当我重新启动Spring启动应用程序时,我如何确保不再发送这70条消息。 一种选择是我可以在数据库表消息 中使用标志。 还有其他有效的方法吗?
-
我有以下设置 3个Kafka(v2.1.1)代理5个Zookeeper实例 Kafka代理具有以下配置: 生产者配置(使用Spring Kafka)大致如下: 这个配置我读如下:有三个Kafka代理,但一旦其中一个死了,它是罚款,如果只有至少两个复制和持久的数据发送ack回(=在同步副本)。如果失败,Kafka制作人会持续重试6分钟,但随后放弃。 这就是让我头疼的场景: 所有Kafka和Zooke
-
ActiveMQ是否支持幂等生产者?我知道Camel有一个幂等消费者模式来检测和处理重复消息,但我想知道是否可以从源头(生产者)防止这种情况。 这里有一点背景。我有水平扩展的应用程序访问同一个数据库。有一个特定的表维护特定进程的状态。这些水平应用程序应该能够读取状态并调用另一个进程,但是只有一个应用程序能够调用它。一旦满足所需条件,该应用程序会定期轮询数据库并将消息发布到消息代理。但我希望其中一个
-
我有一份flink的工作,它使用Kafka的数据,制作一些无状态平面图,并向Kafka生成数据,这是一份工作量非常小的工作。 例如,在作业需要从检查点还原之前,它通常会无问题地获取检查点,而它只是无法使用下面的堆栈跟踪还原状态。 状态非常小,我相信它只是Kafka偏移量,它至少运行了一次语义。 所有操作员都有。uid()集,我完全没有主意了。 这是尝试从检查点重新启动时的错误: 任务管理器在正常操
-
一、线程间通信的两种方式 1.wait()/notify() Object类中相关的方法有notify方法和wait方法。因为wait和notify方法定义在Object类中,因此会被所有的类所继承。这些方法都是final的,即它们都是不能被重写的,不能通过子类覆写去改变它们的行为。 ①wait()方法: 让当前线程进入等待,并释放锁。 ②wait(long)方法: 让当前线程进入等待,并释放锁,
-
我正在使用融合架构注册表,我在同一主题下注册了多个架构。 如果我尝试发布记录,架构 Id 是作为记录的一部分发送的(即使从缓存中发送),还是仅在将新版本的架构注册到架构注册表时发送?