《flink》专题
-
Flink Streaming:由控制流控制的数据流
我有一个问题是这个问题的变体:Flink:如何存储状态和在另一个流中使用? 我有两条流: val ipStream:DataStream[IP地址]= <代码>val routeStream:数据流[路由表]= 我想知道哪个包裹使用哪条路线。通常可以通过以下方式完成: 这里的问题是,我无法在这里真正为流设置密钥,因为这既需要完整的表,也需要ip地址(并且密钥必须独立计算)。 对于中的每个元素,我需
-
Flink为单个源使用多个数据类
一些代码: 这里,我从kinesis流中获取数据,并将其序列化到我的数据类中。一切正常,但现在需要增加以另一种格式接收数据的能力(例如,DataClassSecond) 其中一个选项是,添加一个额外的数据源并在您自己的流中处理它们。 但是这需要一个额外的运动队列。我不确定这是否是一个好方法有没有什么方法可以从运动接收不同的数据,然后根据类型分割流?
-
为什么flink不删除延迟数据?
我在计算一个简单蒸汽的最大值,结果是: (S11000,S1,值:999) (S12000,S1,值:41) 最后一行数据明显迟到了: 为什么按第一个窗口(0-1000)计算? 我认为第一个窗口应该在到达时触发。 对于这个结果,我很疑惑。 MyReductingMax(),MyWindowFunction()
-
Flink键控过程函数是否可以有多个状态描述符?
我使用键控进程函数来使用RocksDB状态后端。我想为同一把钥匙持有两种不同的状态; 状态1类型:ValueState[字符串] 状态2类型:MapState[String, Long] 在这种情况下,我必须在同一个键控进程函数中创建两个状态描述符。这在flink中可能吗?
-
Apache Flink浓缩
我有一个这样的事件来源 我需要通过用户过去的网页访问来丰富我的事件流。(我在数据库中拥有信息,我可以将其用作Flink源) 如何确保在开始处理事件流之前,我已经准备好了扩展数据 我不想从流中进行DB调用。
-
如何为实时数据流配置Apache Flink Cluster(flink-conf.yml)
请帮帮我,我有一个Apache Flink集群(2个作业管理器,3个任务管理器),但我不知道在Flink-conf.yml中为该参数设置哪些值: jobmanager。堆大小 taskmanager。堆大小 taskmanager。TaskSlots数量 相似违约 任务管理器机器有:8CPU,32GB RAM 任务管理器机器有:8CPU,32GB RAM 我将计划在此群集上运行15。。20份Apa
-
Apache flink:RocksDB后端保存点的延迟加载
我们希望将Apache Flink与RocksDB后端(HDFS)一起用于有状态流处理。然而,我们的应用程序状态(键控状态)将以TB为单位。 据我所知,当我们从保存点恢复作业时,所有操作员状态数据都将从HDFS上的保存点位置传送到每个任务管理器。如果状态为TB量级,那么如果需要传输所有此状态,则每次部署都会导致很长的停机时间。 我想了解,在RocksDB的情况下,是否可以配置延迟加载,其中键控状态
-
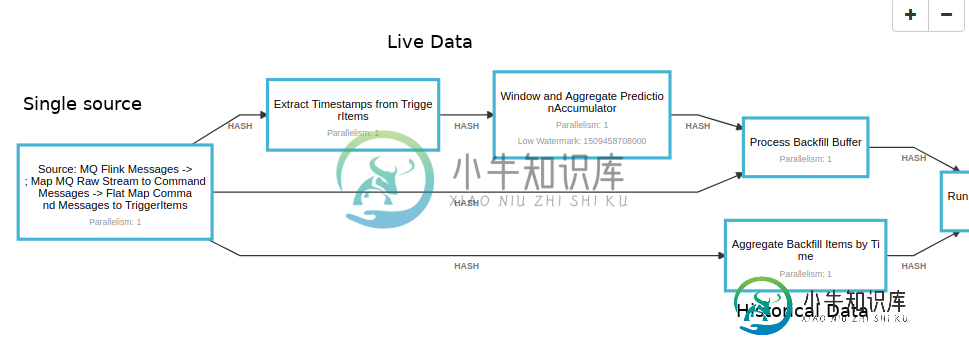 Flink EventTime应用程序中的每条记录都需要时间戳吗?
Flink EventTime应用程序中的每条记录都需要时间戳吗?我正在构建一个Flink流媒体系统,可以处理实时数据和历史数据。所有数据都来自同一来源,然后将其拆分为历史数据和实时数据。实时数据得到时间戳和水印,而历史数据则按顺序接收。活动流打开窗口后,两个流将联合并流入同一个处理管道。 如果EventTime流媒体环境中的所有记录都需要加时间戳,或者Flink是否可以同时处理实时数据和历史数据的混合,我在任何地方都找不到。这是一种可行的方法,还是会造成我经验
-
Flink CEP模式检测不会实时发生
我对Flink CEP库还是个新手,但我不了解模式检测行为。考虑到下面的示例,我有一个Flink应用程序,它使用来自kafka主题的数据,数据是定期生成的,我想使用Flink CEP模式来检测值何时大于给定阈值。代码如下: 当我运行作业时会发生什么,模式检测不会实时发生,它只在生成第二条记录后才输出当前记录检测到的模式的警告,似乎延迟了将警告打印到日志中,我真的不知道如何让它在检测到模式时输出警告
-
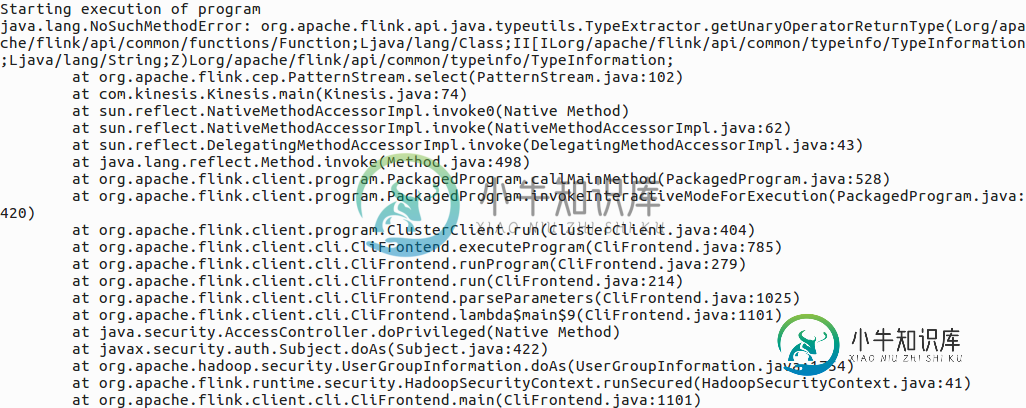 Flink CEP:java。lang.NoSuchMethodError
Flink CEP:java。lang.NoSuchMethodErrorFink跑 /home/admin/Documents/flink_cep/Flink-master/dist/Kinesis.jar 当我尝试在命令行中运行Jar文件时,收到错误,但我的代码在Netbean IDE中运行良好:
-
Flink CEP state商店
Flink CEP如何管理间歇性状态?它将它们存储在哪里?它只是在内存中还是有一个快速的持久存储支持状态? 留档在任何地方都没有提到这一点。
-
如何使用带有特定分区器的Apache Flink将数据作为键/值发送给Kafka
我在Flink有一个载荷,如下所示; 我想用指定的分区器将数据作为键值格式发送给kafka。对于分区器,我将使用模分区器。 模分配器示例; 让我们假设参数为3。如果我们可以使用上面定义的有效负载的memberId,那么partitionId应该是4%3 根据上面的分区器,我想将具有相同分区ID的数据发送到相同的Kafka主题。另一个例子; 如果(假设num分区=3); 如果我没说错的话,如果我们不
-
找不到Apache flink Kafka连接器
我对flink/Java/Scala还比较陌生,所以这可能不是问题,但非常感谢您的帮助。我还没有找到一个将Flink Kafka连接器与Flink 1.13结合使用的示例(对我适用)。 我的项目在这里:https://github.com/sysarcher/flink-scala-tests 我想我无法使用我想试用的FlinkKafkaConsumer(链接)。 我正在使用IntelliJ Id
-
如何使用Apache Flink 1.12和DataStream API批处理模式将Kafka添加为有界源
我想在Apache Flink 1.12中使用Kafka源作为有界数据源,我尝试过使用Flink Kafka消费者连接器,但它给了我以下原因 原因:java.lang.IllegalStateException:检测到一个未绑定的源,execution.runtime模式设置为BATCH。不允许此组合,请在org.apache.flink.util.Preconditions.check状态下将e
-
我怎样才能把Flink和德鲁伊联系起来?
我试图把Flink和德鲁伊联系起来。 然而,我不知道如何正确地做到这一点。 在此Flink留档中,"bootstrap.servers"设置为"localhost:9092"。 这是否意味着我可以使用Apache Kafka摄取直接连接,因为下面设置了示例主管规范? 除了Flink,我还需要管理Kafka吗?或者我应该做其他事情来连接Flink和德鲁伊?