《flink》专题
-
Flink Kafka源时间戳提取器的类加载
我正在尝试将Flink作业部署到基于Flink:1.4.1-hadoop27-scala\u 2.11-alpine映像的集群中。作业使用的是Kafka连接器源(flink-connector-Kafka-0.11),我试图为其分配时间戳和水印。我的代码与Flink Kafka连接器文档中的Scala示例非常相似。但FlinkKafkaConsumer011 这在从IDE本地运行时非常有效。但是,
-
Flink Kafka重置检查点和偏移量
简而言之,我想从一开始就对Kafka的数据重新运行Flink管道。 Flink0.10.2,Kafka0.8.2。 我在Kafka中有一个保留2小时的推文主题,以及Flink中的一个管道,该管道以每10秒5分钟的滑动窗口计算推文。 如果我中断管道并重新运行它,我希望它重新读取旧推文,从而发出价值5分钟的推文计数。相反,它似乎从新到达的推文重新开始,因此需要5分钟才能计数为“处于状态”。 我已经尝试
-
如何在Apache Flink中处理瞬态/应用程序故障?
我的Flink处理器监听Kafka,处理器中的业务逻辑涉及调用外部REST服务,服务可能会停止。我想将元组重放回处理器中,是否仍有这样做的方法?我使用了Storm,我们将能够使元组失败,这样元组就不会被确认。因此,相同的元组将重播到处理器。 在Flink中,一旦消息被Flink Kafka消费者消费,元组就会被自动确认。有很多方法可以解决这个问题。其中一种方法是将消息发布回同一队列/重试队列。但我
-
flink:处理背压(来源:kafka,sink:elasticsearch)
我有一份flink的工作,从Kafka读取数据,执行某些聚合,并将结果写入elasticsearch索引。我看到震源上有很高的背压。高背压导致数据从Kafka缓慢读取,我看到数据在网络堆栈中排队(netstat RecvQ显示源Kafka连接中有上万字节的数据,数据最终被读取),这反过来会导致数据在延迟后沉入elasticsearch,并且延迟持续增加。 源每分钟产生约17500条记录,Flink
-
Kafka主题分区重新分配时,Flink作业持续失败
Kafka1.0.1 我使用200个分区的主题。flink使用这个主题。 最近,我进行了手动分区重新分配。 当我重新分配分区时,Flink连续失败并出现此错误。 错误1。 错误2. 错误3。 当我重新启动失败的作业时,这个错误会不断发生。 所以我重新启动了所有mesos和flink集群,并获得了动物园管理员的许可<有什么原因需要寻找吗?
-
具有巨大状态的Flink恢复/重启作业
我正在K8上运行flink cluster,状态约为1TB。 我面临的问题之一是获取保存点并恢复作业。现在,这些更新有时是简单的代码更新,而不是并行性更改。但是获取保存点然后用旧状态恢复新作业的时间相当长。 是否有方法对作业进行就地更新,以使本地状态和作业ID不发生更改,从而避免执行保存点恢复所需的时间?
-
错误:java。lang.ClassNotFoundException:组织。json4s。运行flink作业时的默认格式
我使用flink-1.4.2与scala。同时运行我的代码与flink。我得到错误:
-
如何使Flink的工作以巨大的状态完成
我们正在运行一个Flink集群来计算历史上数TB的流式数据。数据计算有一个巨大的状态,我们使用键控状态-RocksDb后端的值和映射状态。在工作计算的某个时候,工作绩效开始下降,输入和输出率下降到几乎为0。此时,可以在日志中看到诸如“与Taskmanager通信X超时错误”之类的异常情况,但作业甚至在之前就已被破坏。 我想我们面临的问题是RocksDb的磁盘后端。随着作业状态的增长,需要更频繁地访
-
Flink如何发现每个键的所有kafka分区
我在数据流中使用“keyby”。我要flink发现每个键的所有kafka分区。我有30个分区
-
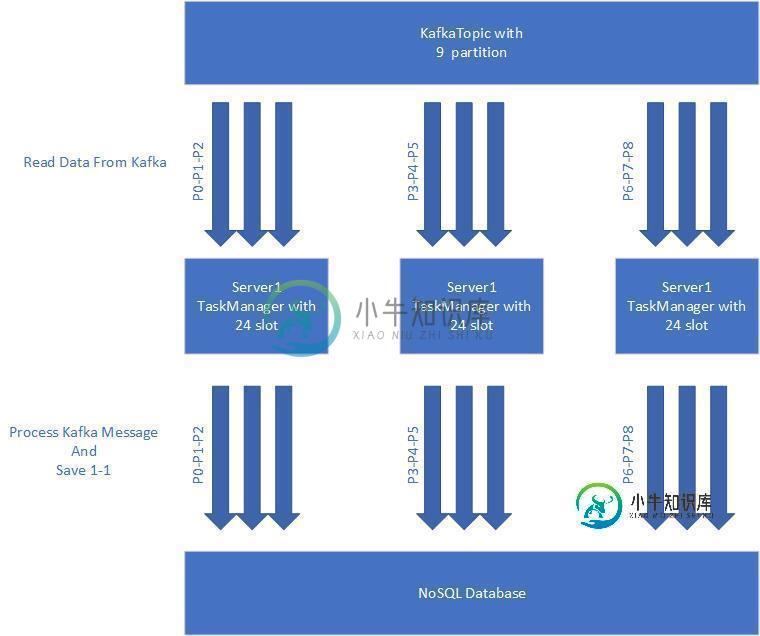 Apache Flink-Kafka集成分区分离
Apache Flink-Kafka集成分区分离我需要实现下面的数据流。我有一个kafka主题,它有9个分区。我可以用9个并行级别阅读这个主题。我还有3个节点Flink集群。这个集群的每个节点都有24个任务槽。 首先,我想传播我的kafka,每个服务器有3个分区,如下所示。顺序没关系,我只转换kafka消息并发送DB。 第二件事是,我想在保存NoSQL DB的同时提高并行度。如果我增加并行度48,因为发送DB是IO操作,它不会消耗CPU,我想确
-
Apache Flink,线程比Kafka分区多
数据流很简单 Kafka- “一些逻辑”是这里的瓶颈,所以我想使用更多的线程/任务来提高吞吐量,而不是增加kafka分区(目前为3个)。输入和输出主题之间的顺序在这里并不重要。 使用Apache Storm可以轻松完成。我可以为一些逻辑增加螺栓的并行度。如何使用Flink做到这一点?更普遍的问题是,是否有任何简单的方法可以在Flink的不同阶段使用不同的并行度?
-
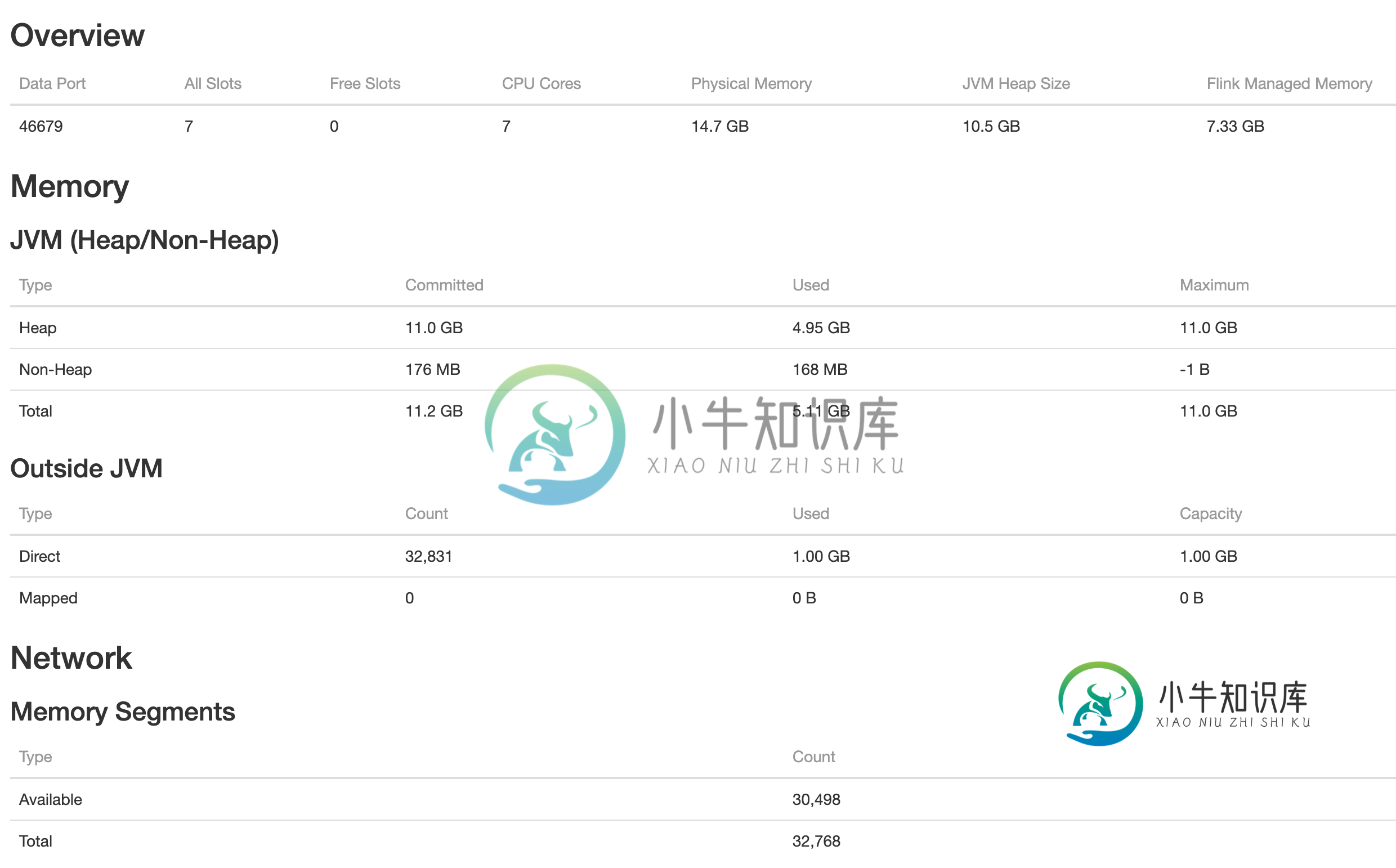 Apache Flink:与网络内存段的直接内存关系
Apache Flink:与网络内存段的直接内存关系我正在运行Flink 1.8版。 主要配置如下: 声明的堆大小是12GB,为什么在概述部分显示为7.33GB。 根据文档,堆大小=声明的堆大小-网络缓冲区内存(默认值:声明的堆的0.1倍,但最大为1gb)。所以正确的值是JVM(堆/非堆)部分中显示的值,即11GB :我假设,由于现在使用1GB作为网络缓冲内存,因此32768段基本上是指32KiB大小的内存段的计数。这些用于在任务之间传输数据的TC
-
Flink·Kafka,爪哇。并行度>1时的lang.OutOfMemoryError
我有一个玩具Flink工作,从3个Kafka主题中读取,然后联合所有这3个流。仅此而已,没有额外的工作。 如果在我的Flink工作中使用parallelism 1,只要我更改parallelism,一切都会很好 为什么它适用于并行1,但不适用于并行 是否与Kafka服务器端设置有关?或者它与我的java代码中的comsumer设置有关(我的代码中还没有特殊的配置)? 我知道这里提供的信息可能不够充
-
Flink和Beam SDK如何处理窗口-哪个更有效?
我将Apache Beam SDK与Flink SDK进行流处理比较,以确定使用Beam作为附加框架的成本/优势。 我有一个非常简单的设置,其中数据流从Kafka源读取并由运行Flink的节点集群并行处理。 根据我对这些SDK工作原理的理解,逐窗口处理数据流的最简单方法是: > 使用Apache Beam(在Flink上运行): 1.1.创建一个Pipeline对象。 1.2。创建Kafka记录的
-
关于Flink外部化检查点的两个问题
我有两个关于Flink外部化检查站的问题 (Q1)我可以在flink-conf.yaml中设置“state.checkpoints.dir”,以使外部化的检查点正常工作,但当我从IDE运行flink时,如何实现同样的效果呢?我尝试了中提到的全局配置方法(http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/state