
Apache Flink-Kafka集成分区分离

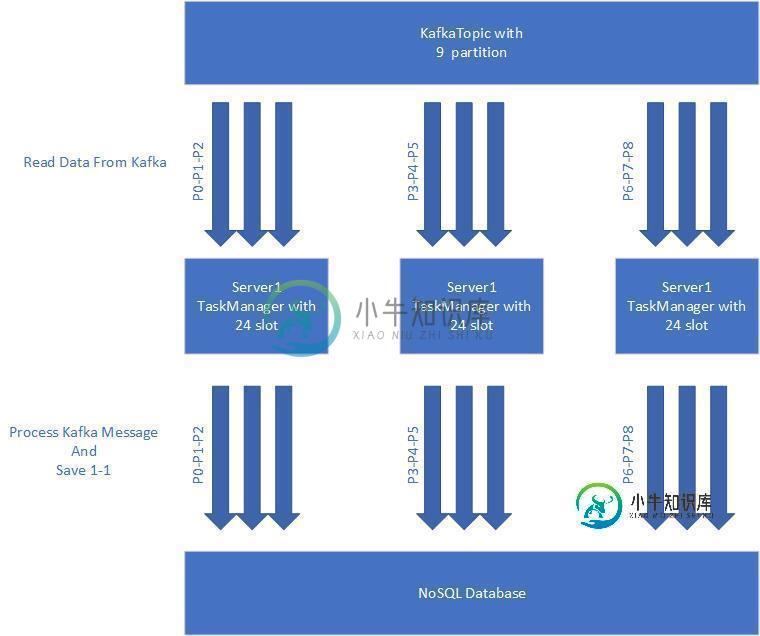
我需要实现下面的数据流。我有一个kafka主题,它有9个分区。我可以用9个并行级别阅读这个主题。我还有3个节点Flink集群。这个集群的每个节点都有24个任务槽。
首先,我想传播我的kafka,每个服务器有3个分区,如下所示。顺序没关系,我只转换kafka消息并发送DB。
第二件事是,我想在保存NoSQL DB的同时提高并行度。如果我增加并行度48,因为发送DB是IO操作,它不会消耗CPU,我想确定的是,当Flink重新平衡我的消息时,我的消息将保留在同一个服务器上。
有什么建议吗?
共有1个答案

如果要将Kafka读取器分布在所有3个节点上,我建议从每个节点开始使用3个插槽,并将Kafka源的并行度设置为9。
问题是,如果可用的插槽数超过了所需的并行度,那么目前无法控制任务的放置方式。这意味着如果您的源少于插槽,那么可能会将所有源部署到一台机器上,而其他机器则为空(源)。
能够将任务分散到所有可用的机器上是社区目前正在开发的一项功能。
-
我正在用单个主题和多个分区实现kafka producer。我通过消息中的一个特定值(消息json中的feedName属性值)选择消息到哪个分区。我正在为feedName-partitionId映射维护一个SQL表。我的问题是,leader和副本的分区Id是否相同?如果不同,如何在所有代理中唯一地标识分区?
-
Kafka主题分区偏移位置始终从0或随机值开始,如何确保使用者记录是分区中的第一条记录?有没有办法找出答案?如果有的话,请让我知道。谢谢。
-
本文向大家介绍Kafka分区分配的概念?相关面试题,主要包含被问及Kafka分区分配的概念?时的应答技巧和注意事项,需要的朋友参考一下 一个topic多个分区,一个消费者组多个消费者,故需要将分区分配个消费者(roundrobin、range)
-
本文向大家介绍集的分区,包括了集的分区的使用技巧和注意事项,需要的朋友参考一下 集合的分区(例如S)是满足以下三个条件的n个不相交的子集(例如P 1,P 1,... P n)的集合- P i不包含空集。 对于所有0 <i≤n, [P i ≠{∅} 子集的并集必须等于整个原始集合。 [P 1 ∪P 2 ∪..
-
我设置了一个Spring集成流程来处理一个有3个分区的主题,并将侦听器容器的并发性设置为3。正如所料,我看到三个线程处理来自所有3个分区的批处理。然而,我发现在某些情况下,一个侦听器线程可能处理包含来自多个分区的消息的单个批处理。在kafka中,我的数据是按id划分的,因此它可以与其他id同时处理,但不能在另一个线程上与相同的id一起处理(我很惊讶地发现这种情况正在发生)。通过阅读文档,我认为每个
-
本文向大家介绍Kafka 分区的目的?相关面试题,主要包含被问及Kafka 分区的目的?时的应答技巧和注意事项,需要的朋友参考一下 分区对于 Kafka 集群的好处是:实现负载均衡。分区对于消费者来说,可以提高并发度,提高效率。