《红黑树》专题
-
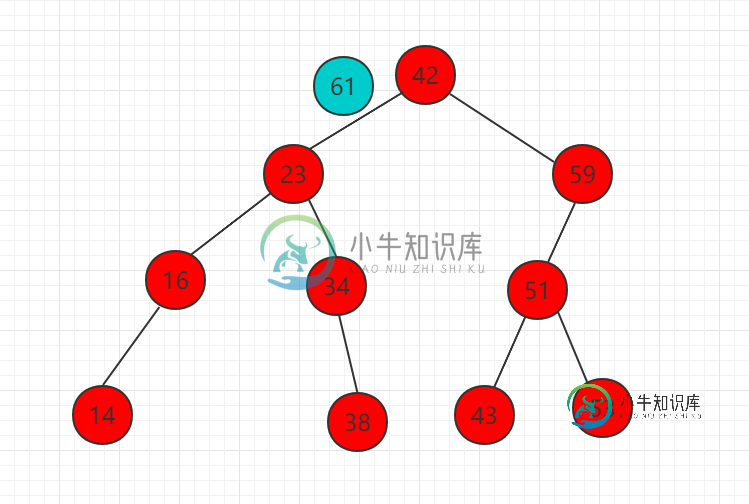 二分搜索树节点的插入
二分搜索树节点的插入主要内容:src/runoob/binary/BinarySearchTreeInsert.java 文件代码:首先定义一个二分搜索树,Java 代码表示如下: public class BST < Key extends Comparable <Key >, Value > { // 树中的节点为私有的类, 外界不需要了解二分搜索树节点的具体实现 private class Node { private Key key ; private Val
-
 二分搜索树
二分搜索树主要内容:src/runoob/binary/BinarySearch.java 文件代码:一、概念及其介绍 二分搜索树(英语:Binary Search Tree),也称为 二叉查找树 、二叉搜索树 、有序二叉树或排序二叉树。满足以下几个条件: 若它的左子树不为空,左子树上所有节点的值都小于它的根节点。 若它的右子树不为空,右子树上所有的节点的值都大于它的根节点。 它的左、右子树也都是二分搜索树。 如下图所示: 二、适用说明 二分搜索树有着高效的插入、删除、查询操作。 平均时间的时间复
-
sklearn决策树分类算法
主要内容:决策树算法应用,决策树实现步骤,决策树算法应用本节基于 Python Sklearn 机器学习算法库,对决策树这类算法做相关介绍,并对该算法的使用步骤做简单的总结,最后通过应用案例对决策树算法的代码实现进行演示。 决策树算法应用 在 sklearn 库中与决策树相关的算法都存放在 模块里,该模块提供了 4 个决策树算法,下面对这些算法做简单的介绍: 1) .DecisionTreeClassifier() 这是一个经典的决策树分类算法,它提供
-
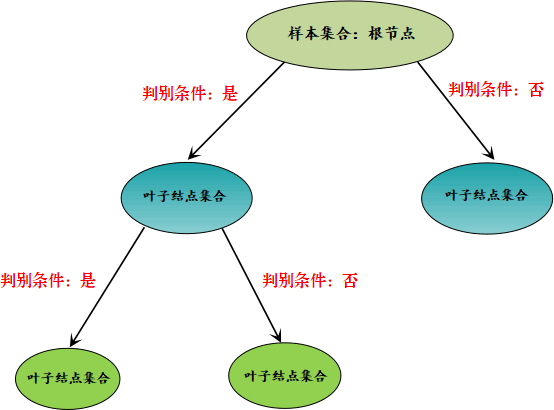 决策树算法和剪枝原理
决策树算法和剪枝原理主要内容:决策树算法原理,决策树剪枝策略本节我们对决策算法原理做简单的解析,帮助您理清算法思路,温故而知新。 我们知道,决策树算法是一种树形分类结构,要通过这棵树实现样本分类,就要根据 if -else 原理设置判别条件。因此您可以这样理解,决策树是由许多 if -else 分枝组合而成的树形模型。 决策树算法原理 决策树特征属性是 if -else 判别条件的关键所在,我们可以把这些特征属性看成一个 集合,我们要选择的判别条件都来自于
-
 选择决策树判别条件
选择决策树判别条件主要内容:纯度的概念,纯度度量规则,纯度度量方法首先来看一个“我想你来猜”的游戏,游戏规则很简单:一个人从脑海中构建一个事物,另外几个人最多可以向他提问 20 个问题,游戏规定,问题的答案只能用是或者否来回答。问问题的人通过回答者的“答案”来推分析、逐步缩小待猜测事物的范围,从而来判断他想的是什么。其实这个游戏与决策树工作过程相似。 那么你有没有考虑过要怎样选择“问什么问题”呢,在这里“问什么问题”就相当于决策树算法中的“判别条件”。选择什么判
-
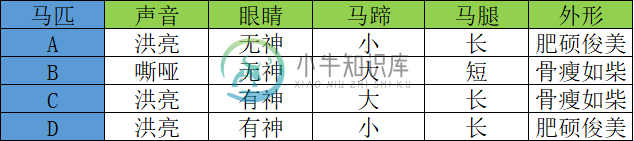 决策树算法if-else原理
决策树算法if-else原理主要内容:if-else原理,决策树算法关键在本节我们将介绍“机器学习”中的“明星”算法“决策树算法”。决策树算法在“决策”领域有着广泛的应用,比如个人决策、公司管理决策等。其实更准确的来讲,决策树算法算是一类算法,这类算法逻辑模型以“树形结构”呈现,因此它比较容易理解,并不是很复杂,我们可以清楚的掌握分类过程中的每一个细节。 if-else原理 想要认识“决策树算法”我们不妨从最简单的“if - else原理”出发来一探究竟。作为程序员,
-
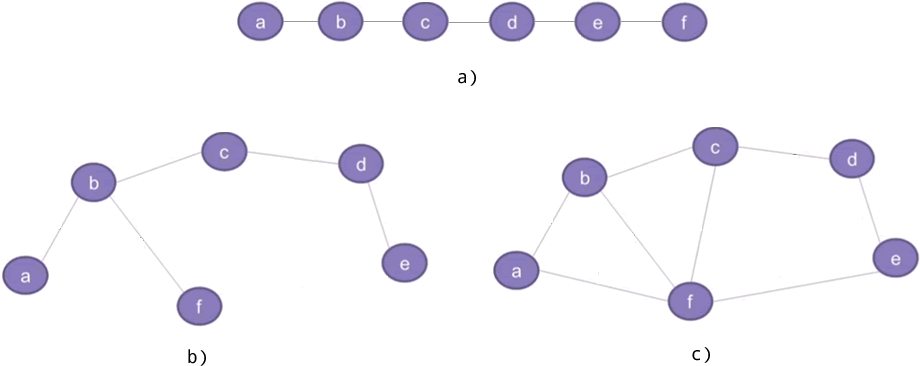 最小生成树
最小生成树主要内容:生成树,最小生成树数据结构提供了 3 种存储结构,分别称为线性表、树和图,如图 1 所示。 图 1 3 种存储结构 a) 是线性表,b) 是树,c) 是图。 在图存储结构中,a、b、c 等称为顶点,连接顶点的线称为边。 线性表是最简单的存储结构,很容易分辨。树和图有很多相似之处,它们的区别是:树存储结构中不允许存在环路,而图存储结构中可以存在环路(例如图 1 c) 中,c-b-f-c、b-a-f-b 等都是环路)。
-
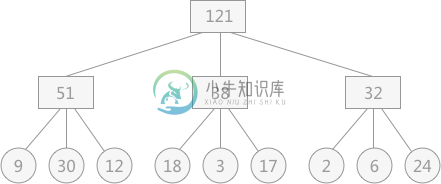 最佳归并树
最佳归并树主要内容:附加“虚段”的归并树通过上一节对置换-选择排序算法的学习了解到,通过对初始文件进行置换选择排序能够获得多个长度不等的初始归并段,相比于按照内存容量大小对初始文件进行等分,大大减少了初始归并段的数量,从而提高了外部排序的整体效率。 本节带领大家思考一个问题:无论是通过等分还是置换-选择排序得到的归并段,如何设置它们的归并顺序,可以使得对外存的访问次数降到最低? 例如,现有通过置换选择排序算法所得到的 9 个初始归并段,
-
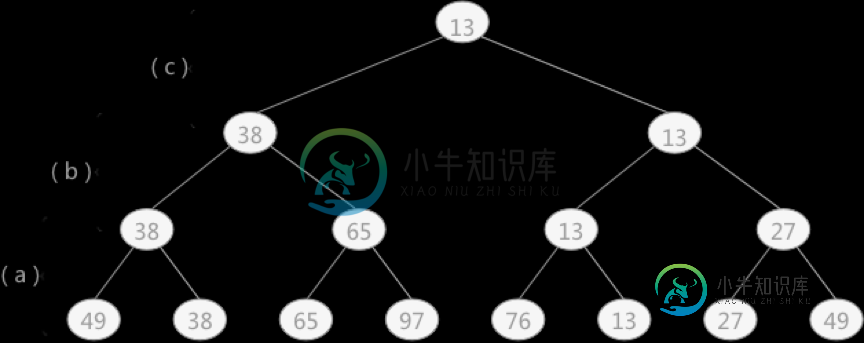 多路平衡归并排序(胜者树、败者树)算法
多路平衡归并排序(胜者树、败者树)算法主要内容:败者树实现内部归并,败者树内部归并的具体实现,总结通过上一节对于外部排序的介绍得知:对于 外部排序算法来说,其直接影响算法效率的因素为读写外存的次数,即次数越多,算法效率越低。若想提高算法的效率,即减少算法运行过程中读写外存的次数,可以增加 k –路平衡归并中的 k 值。 但是经过计算得知,如果毫无限度地增加 k 值,虽然会减少读写外存数据的次数,但会增加内部归并的时间,得不偿失。 例如在上节中,对于 10 个临时文件,当采用 2-路平衡归并时,
-
 平衡二叉树(AVL树)
平衡二叉树(AVL树)主要内容:二叉排序树转化为平衡二叉树,构建平衡二叉树的代码实现,总结上一节介绍如何使用二叉排序树实现动态 查找表,本节介绍另外一种实现方式—— 平衡二叉树。 平衡二叉树,又称为 AVL 树。实际上就是遵循以下两个特点的二叉树: 每棵子树中的左子树和右子树的深度差不能超过 1; 二叉树中每棵子树都要求是平衡二叉树; 其实就是在二叉树的基础上,若树中每棵子树都满足其左子树和右子树的深度差都不超过 1,则这棵二叉树就是平衡二叉树。 图 1 平衡与不平衡的二叉树及结点的
-
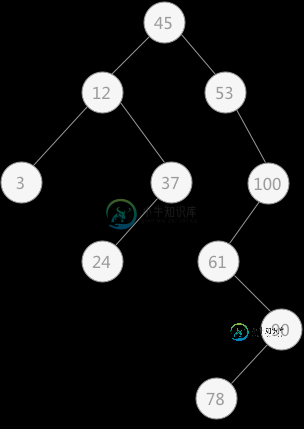 二叉排序树(二叉查找树)
二叉排序树(二叉查找树)主要内容:什么是二叉排序树?,使用二叉排序树查找关键字,二叉排序树中插入关键字,二叉排序树中删除关键字,总结前几节介绍的都是有关静态 查找表的相关知识,从本节开始介绍另外一种查找表—— 动态查找表。 动态查找表中做查找操作时,若查找成功可以对其进行删除;如果查找失败,即表中无该关键字,可以将该关键字插入到表中。 动态查找表的表示方式有多种,本节介绍一种使用树结构表示动态查找表的实现方法—— 二叉排序树(又称为 “二叉查找树”)。 什么是二叉排序树? 二叉排序树要么是空 二叉树,要么具有如下特点:
-
 深度优先生成树和广度优先生成树
深度优先生成树和广度优先生成树主要内容:非连通图的生成森林,深度优先生成森林,广度优先生成森林前面已经给大家介绍了有关 生成树和生成森林的有关知识,本节来解决对于给定的无向图,如何构建它们相对应的生成树或者生成森林。 其实在对无向图进行遍历的时候,遍历过程中所经历过的图中的顶点和边的组合,就是图的生成树或者生成森林。 图 1 无向图 例如,图 1 中的无向图是由 V1~V7 的顶点和编号分别为 a~i 的边组成。当使用 深度优先搜索算法时,假设 V1 作为遍历的起始点,涉及到的顶点和边
-
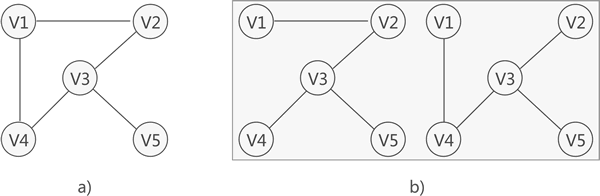 什么是生成树(生成森林)
什么是生成树(生成森林)主要内容:生成森林在学习 连通图的基础上,本节学习什么是 生成树,以及什么是 生成森林。 对连通图进行遍历,过程中所经过的边和顶点的组合可看做是一棵普通树,通常称为 生成树 。 图 1 连通图及其对应的生成树 如图 1 所示,图 1a) 是一张连通图,图 1b) 是其对应的 2 种生成树。 连通图中,由于任意两顶点之间可能含有多条通路,遍历连通图的方式有多种,往往一张连通图可能有多种不同的生成树与之对应。 连通图中
-
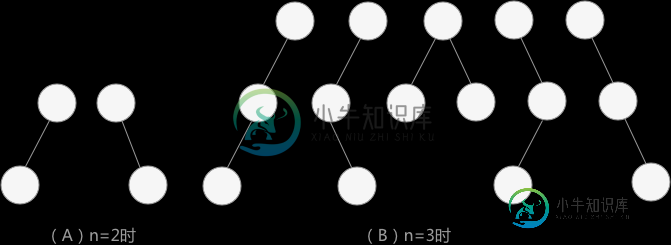 n个结点的二叉树种类
n个结点的二叉树种类本节要讨论的是当给定 n(n>=0)个结点时,可以构建多少种形态不同的树。 如果两棵树中各个结点的位置都一一对应,可以说这两棵树相似。如果两棵树不仅相似,而且对应结点上的数据也相同,就可以说这两棵树等价。本节中,形态不同的树指的是互不相似的树。 前面介绍过,对于任意一棵普通树,通过孩子兄弟表示法的转化,都可以找到唯一的一棵 二叉树与之对应。所以本节研究的题目也可以转化成:n 个结点可以构建多少种形
-
 哈夫曼树(赫夫曼树、最优树)
哈夫曼树(赫夫曼树、最优树)主要内容:哈夫曼树相关的几个名词,什么是哈夫曼树,构建哈夫曼树的过程,哈弗曼树中结点结构,构建哈弗曼树的算法实现赫夫曼树,别名“哈夫曼树”、“最优树”以及“最优 二叉树”。学习哈夫曼树之前,首先要了解几个名词。 哈夫曼树相关的几个名词 路径: 在一棵树中,一个结点到另一个结点之间的通路,称为 路径。图 1 中,从根结点到结点 a 之间的通路就是一条路径。 路径长度:在一条路径中,每经过一个结点,路径长度都要加 1 。例如在一棵树中,规定根结点所在层数为1层,那么从根结点到第 i 层结点的路径长度