《机器学习》专题
-
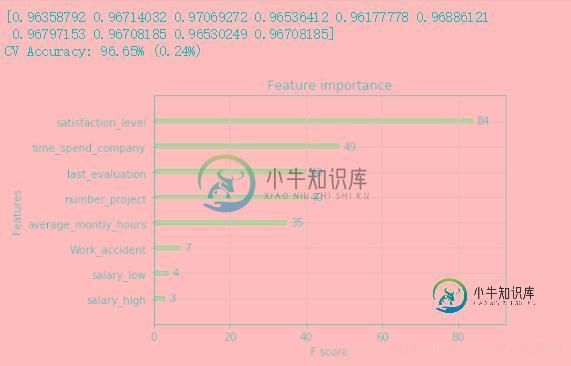 python机器学习库xgboost的使用
python机器学习库xgboost的使用本文向大家介绍python机器学习库xgboost的使用,包括了python机器学习库xgboost的使用的使用技巧和注意事项,需要的朋友参考一下 1.数据读取 利用原生xgboost库读取libsvm数据 使用sklearn读取libsvm数据 使用pandas读取完数据后在转化为标准形式 2.模型训练过程 1.未调参基线模型 使用xgboost原生库进行训练 使用XGBClassifier进行
-
 机器学习图像特征提取
机器学习图像特征提取在机器学习中,灰度图像的特征提取是一个难题。 我有一个灰色的图像,是用这个从彩色图像转换而来的。 我实际上需要从这张灰色图片中提取特征,因为下一部分将训练一个具有该特征的模型,以预测图像的彩色形式。 我们不能使用任何深度学习库 有一些方法,如快速筛选球。。。但我真的不知道如何才能为我的目标提取特征。 以上代码的输出就是真的。 有什么解决方案或想法吗?我该怎么办?
-
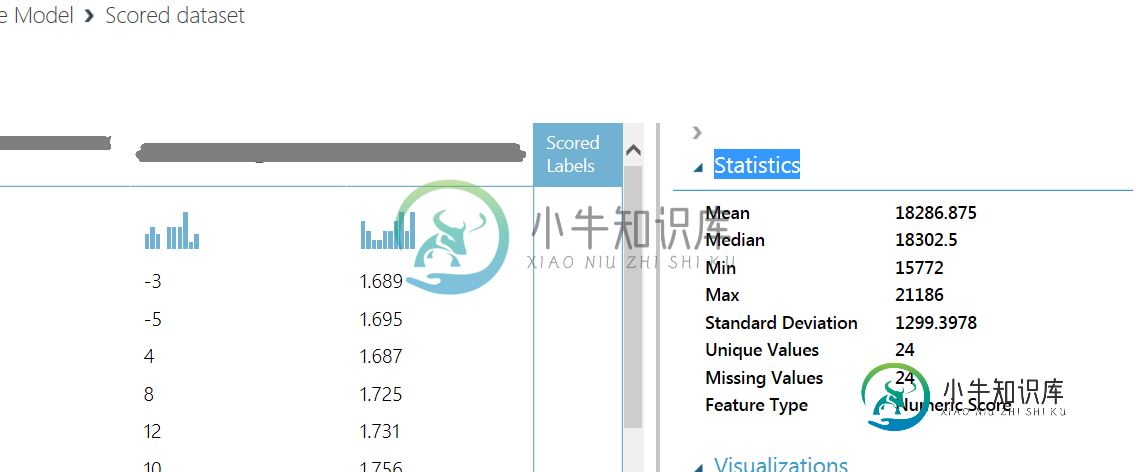 Azure机器学习-空分数结果
Azure机器学习-空分数结果我训练了一个模型,在测试集上的测试结果是可以的。现在,我已经将模型保存为“训练模型”,并将一个新的实验转化为一个新的数据集,以便在我没有实际值的情况下进行预测。 通常,训练过的模型给我一个每个实例的评分标签结果。但是现在,打分的标签结果是空的。另外,当我将得分结果转换为CSV时,得分标签列是空的。 更奇怪的是,当我查看score Visualize选项卡的统计数据时,我确实看到了得分值的统计数据。
-
第十八章 机器学习入门
入门文章 一文读懂机器学习,大数据/自然语言处理/算法全有了
-
8. 大数据与机器学习 - Tensorflow
Kubeflow 是 Google 发布的用于在 Kubernetes 集群中部署和管理 tensorflow 任务的框架。主要功能包括 用于管理 Jupyter 的 JupyterHub 服务 用于管理训练任务的 Tensorflow Training Controller 用于模型服务的 TF Serving 容器 部署 部署之前需要确保 一套部署好的 Kubernetes 集群或者 Mini
-
8. 大数据与机器学习 - Spark
Kubernetes 从 v1.8 开始支持原生的Apache Spark应用(需要Spark支持Kubernetes,比如v2.2.0-kubernetes-0.4.0),可以通过 spark-submit 命令直接提交Kubernetes任务。比如计算圆周率 bin/spark-submit --deploy-mode cluster --class org.apache.spark.
-
使用 scikit-learn 介绍机器学习
校验者: @小瑶 翻译者: @李昊伟 校验者: @hlxstc @BWM-蜜蜂 @小瑶 翻译者: @... 内容提要 在本节中,我们介绍一些在使用 scikit-learn 过程中用到的 机器学习 词汇,并且给出一些例子阐释它们。 机器学习:问题设置 一般来说,一个学习问题通常会考虑一系列 n 个 样本 数据,然后尝试预测未知数据的属性。 如果每个样本是 多个属性的数据 (比如说是一个多维记录),
-
6 最好的机器学习资源
用于制定人工智能、机器学习和深度学习课程表的资源概览。 制定课程表的一般建议 上学获得一个正式学位并不总是可行或者令人满意的。对于那些考虑自学来代替的人,这就是写给你们的。 1. 构建基础,之后专攻兴趣领域 你不能深入每个机器学习话题。有太多药学的东西,并且领域的进展较快。掌握基础概念,之后专注特定兴趣领域的项目 -- 无论是自然语言理解,计算机视觉,深度强化学习,机器人,还是任何其它东西。 2.
-
1 为什么机器学习重要
简单、纯中文的解释,辅以数学、代码和真实世界的示例 谁应该阅读它 想尽快赶上机器学习潮流的技术人员 想要入门机器学习,并愿意了解技术概念的非技术人员 好奇机器如何思考的任何人 本指南旨在让任何人访问。将讨论概率,统计学,程序设计,线性代数和微积分的基本概念,但从本系列中学到东西,不需要事先了解它们。 为什么机器学习重要 人工智能将比本世纪的任何其他创新,更有力地塑造我们的未来。 任何一个不了解它的
-
 腾讯 机器学习春招面试
腾讯 机器学习春招面试1. 项目相关 数据集来源 怎么标注 标注的坐标是什么 2. yolo从1开始介绍 3. 了解降维算法吗 pca介绍 4. 了解聚类算法吗 kmeans 密度聚类 5. 说一下knn和随机森林 6. 混淆矩阵 7. 激活函数 说几个 8. 手撕knn 9. 为什么选择llama2而不是其他的 怎么对比的 10. llama2遇到了什么问题 怎么解决 11. llama2有哪些参数 输入长度怎么设置
-
 荣耀-机器学习一面面积
荣耀-机器学习一面面积15Min速战速决,好像是海面 1.自我介绍 2.问了一个项目:介绍,为什么要这样做。为什么用Resnet18,了解其他图像分类模型吗? 3.问了研究课题和论文 4.问了实习经历 无手撕
-
 百度机器学习一面凉经
百度机器学习一面凉经做了海笔没ak也约面了 第一个大厂还是很紧张很紧张的 面试官提前了四十分钟进会议室。。。 一上来自我介绍(ppt)面试官当时表现得有点异常惊讶hh 然后介绍完什么都没说直接编辑距离 当时脑海中一直想直接做题就是kpi 然后出了两个bug,思路也不说的不太好 面试官提醒之后才搞完 再接着就是简历深挖,挖到地心了 很多自己没想过的被问了 然后问各种 bn、dropout、不过都是基础的机器学习的东西,
-
 淘天机器学习实习面试
淘天机器学习实习面试项目问题: 1、常用目标检测算法?区别? 2、基于人脸识别的目标检测有无研究? 3、yolo最初是谁提出的? 4、bert、trasformer的每一层具体结构? 5、transformer的输入输出? 6、如果用bert来做中译英任务,输入输出会是什么?QKV会是什么? 7、gpt的结构?gpt相当于transformer的哪一部分? 8、编码器、解码器的作用? 八股问题: 1、常用激活函数?
-
 bilibili机器学习引擎开发 1h
bilibili机器学习引擎开发 1h自我介绍 c++,计网八股 好多好多 项目深挖 raft和跳表 学校科研和难点 手撕快排(中间脑子一抽写完partition就运行了,现在想想,麻了) 面试官好好!也很温柔~全防出去了!!许愿~ bilibili💕b小将,启动!#bilibili##机器学习#
-
 腾讯cdg机器学习岗面经
腾讯cdg机器学习岗面经一面 (1)死锁的两种原因 (2)模型量化的方式,我说kv cache和参数量化,面试官问量化是怎么提高推理加速的效率,我答不太上来 (3)transformer自注意力层的时间复杂度 (4)stack和dequeue的区别 (5)算法题:有效ip地址 一面面试官是我遇到最善良的面试官,他对跨专业同学的包容性大到难以置信。也很感谢他的宽容和鼓励。最后反问环节,他跟我举了jieba分词的例子,鼓励我